Zhu Zhihua’s Team Presents New Theoretical Proof of Reinforcement Learning Effectiveness in LLMs with Reward Models}
This groundbreaking research by Zhu Zhihua’s team provides the first theoretical proof that reinforcement learning is effective for large language models, leveraging internal reward mechanisms.

Aligning large language models (LLMs) with complex human values remains a core challenge in AI. Current methods mainly rely on reinforcement learning from human feedback (RLHF), which depends on a reward model trained on human preferences. The quality of the aligned LLM fundamentally depends on this reward model.
Creating an advanced reward model requires large, high-quality human preference datasets, which are slow, costly, and hard to scale. This reliance has led researchers to explore alternative alignment methods, such as AI feedback-based reinforcement learning (RLAIF), which uses proprietary LLMs to generate reward signals, avoiding human annotation. However, these methods lack rigorous theoretical foundations and risk inheriting biases from the judging models. This raises a key question: Must high-quality reward signals depend on external sources?
Researchers from Nanjing University discovered that a powerful general reward model can be mined from existing language models trained on next-token prediction, called 'endogenous reward.'
The core contribution of this paper is providing a rigorous theoretical basis for this view. It proves that a specific form of offline inverse reinforcement learning (IRL) reward function can be recovered from the standard next-token prediction objective, used in pretraining and supervised fine-tuning (SFT). This insight goes beyond heuristics, establishing a principled way to extract the implicit reward function learned by language models during training.
Specifically, the paper shows that the logits of language models can be directly interpreted as a soft Q-function, and the reward function can be recovered via an inverse soft Bellman operator.
More importantly, this theory not only offers a reward extraction method but also proves that fine-tuning with the model’s own endogenous reward can lead to policies that outperform baseline models within error bounds. Reinforcement learning effectively corrects the accumulated errors in standard imitation learning (next-token prediction), reducing the performance gap from quadratic dependence O(H²) to a linear relationship O(H).
This is the first theoretical proof of RL’s effectiveness in LLMs. Extensive experiments validate that this endogenous reward not only surpasses existing zero-shot evaluation methods but also outperforms costly explicit reward models trained on human preferences.

- Paper Title: GENERALIST REWARD MODELS: FOUND INSIDE LARGE LANGUAGE MODELS
- Link: https://arxiv.org/pdf/2506.23235
This paper proposes a solution to LLM alignment by utilizing the internal reward mechanism, which could revolutionize future development and application of large language models.
The study aims to evaluate key questions through experiments:
Q1: How does the unsupervised endogenous reward model (EndoRM) perform on common benchmark tests compared to heuristic baselines and explicitly trained reward models?
Q2: Can endogenous rewards exhibit strong instruction-following ability and serve as a universal reward model callable via prompts?
Q3: Can reinforcement learning based on endogenous rewards produce better policies and enable self-improvement?
Reward accuracy on diverse preferences (Q1)
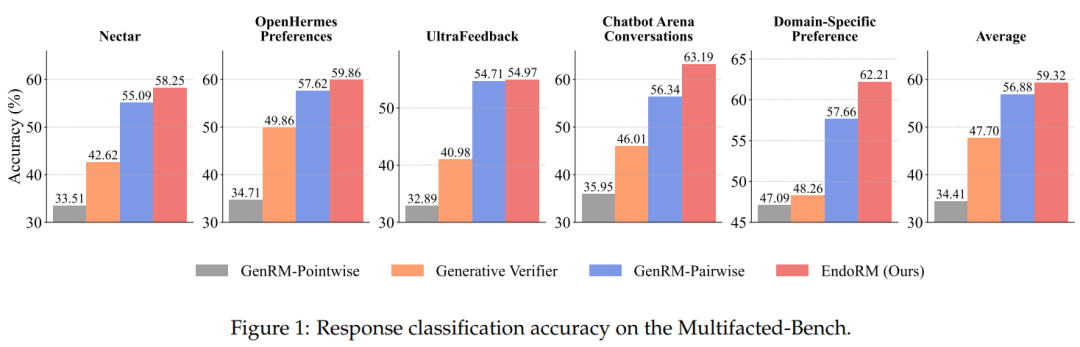
To answer Q1, the study evaluates reward models by predicting responses selected in RM-Bench, with higher accuracy indicating better reward quality. The evaluation compares methods like Generative Verifier, GenRM-Pairwise, and GenRM-Pointwise, all based on the Qwen2.5-7B-Instruct model for fairness. Results show that EndoRM significantly outperforms all zero-shot baselines and even surpasses some explicitly trained reward models, demonstrating its effectiveness without costly human data.
Figure 1 illustrates the results across Multifaceted-Bench, showing EndoRM’s consistent superiority in five domains, even with thousands of preference pairs, indicating robust scalability and the potential of internal reward signals.
Verifying instruction-following ability (Q2)
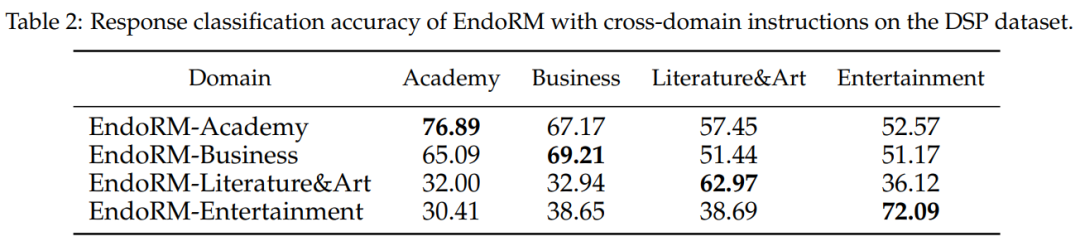
A key point is that endogenous rewards are not static but can be guided via prompts. Using the DSP dataset with four different domains, the study creates domain-specific endogenous reward versions by applying system prompts from the DSP paper. Response classification accuracy is then tested across all four datasets, showing a strong diagonal pattern: each EndoRM performs best in its own domain, confirming that endogenous rewards are dynamic, promptable evaluators inheriting the strong instruction-following capabilities of the base LLM.
Self-improvement via reinforcement learning (Q3)
The final evaluation tests the core theoretical claim: reinforcement learning with endogenous rewards can improve the base policy by reducing compounded errors. Using the Math-light evaluation dataset, the model Qwen2.5-Math-7B is fine-tuned with RL, with the endogenous reward model also based on Qwen2.5-Math-7B, keeping parameters fixed during training. Results show that RL fine-tuning with endogenous rewards consistently outperforms the base model across five benchmarks. Response examples before and after RL training demonstrate that the model initially struggles with questions but improves significantly after optimization, even generating Python code.
The evaluation provides a clear, simple solution to improve model performance through endogenous reward-based RL, validating the theoretical predictions.

For more details, refer to the original paper.