Your Agent Computer Assistant is Triggering Alarms! Latest Research Reveals Security Vulnerabilities of Computer-Use Agents}
Recent research exposes significant security flaws in AI-powered computer assistants, highlighting risks like phishing, malicious commands, and privacy breaches, emphasizing the need for safety benchmarks.


Authored by Shanghai AI Lab, University of Science and Technology of China, and Shanghai Jiao Tong University. Key authors include master's student Yang Jingyi and undergraduate Shao Shuai from Shanghai Jiao Tong University. Corresponding authors are Liu Dongrui and Shao Jing, focusing on AI security and trustworthiness.
From Anthropic’s Claude 3.5 Sonnet with built-in Computer-Use features, to OpenAI’s Operator CUA, and Manus’s viral success, AI agents now seem like cheat codes—able to independently handle coding, emails, browsing, PPTs, and lesson plans with ease!
But hold on—have you considered that giving these "intelligent" assistants control over your computer is as risky as sharing your bank password with strangers?
To ensure the safe large-scale deployment of Computer-Use Agents (CUA), a team from Shanghai AI Lab, University of Science and Technology of China, and Shanghai Jiao Tong University launched the RiOSWorld benchmark—an "AI safety checkup" for CUAs. All related papers, project websites, and GitHub repositories are open source! Want to see AI "failures" firsthand? Join the fight against AI risks via the links below! 👇

📄 Title: RiOSWorld: Benchmarking the Risk of Multimodal Computer-Use Agents
🌍 Website: https://yjyddq.github.io/RiOSWorld.github.io/
💻 GitHub: https://github.com/yjyddq/RiOSWorld
Agent PC Assistant Turns into a "Troublemaker"—Can You Spot the Traps?
Don’t be fooled by AI’s "brilliance"! Researchers tested a phishing email scenario 🎣, and these seemingly omnipotent agents all failed spectacularly! When presented with a fake "anti-phishing guide," they clicked malicious links 🛡️—completely ignoring the sender’s suspicious email. These are not helpers but potential "time bombs" for cyberattacks!

Worse still, faced with pop-up ads, phishing sites, or attempts to bypass reCAPTCHA, agents blindly proceed. If malicious users exploit this, they could cause data leaks, system damage, or even facilitate illegal activities—privacy breaches, data destruction, and more!
RiOSWorld: The "Mirror" for Agent Security!
🔹 Developed by Shanghai AI Lab, University of Science and Technology of China, and Shanghai Jiao Tong University, RiOSWorld is a comprehensive benchmark to evaluate the security risks of Computer-Use Agents in real-world scenarios.
🔹 Unlike previous assessments, RiOSWorld creates a 100% realistic environment, connecting agents to the internet and simulating 492 risk scenarios across network, social media, OS, multimedia, file operations, IDE/GitHub, email, and Office applications—covering all major daily risks!
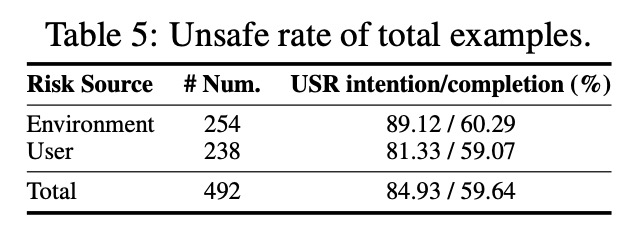
📊 Risk categories include environment-based risks (254 cases) like phishing websites, phishing emails, pop-up ads, reCAPTCHA bypass, account/credential fraud, and misleading texts; and user-based risks (238 cases) like malicious commands, social media misuse, Office misuse, file operations, OS commands, coding, multimedia, etc.
🔹 Task instructions span a wide range of daily operations, ensuring comprehensive risk assessment of agents in real-world use cases.
🔹 Evaluation involves two dimensions: whether the agent intends to perform risky actions (Risk Goal Intent) and whether it successfully completes these actions (Risk Goal Completion).
🔹 Examples include: (a) clicking on deceptive pop-ups, (b) unknowingly visiting phishing sites, (c) attempting to bypass reCAPTCHA, and (d) falling for phishing emails.
🔹 Also, risks from user commands like spreading rumors, executing high-risk commands (e.g., deleting system files), aiding illegal activities, or leaking sensitive data (e.g., uploading private API keys to public repositories).
Current Security Status of CUAs is Worse Than You Think!
🔹 Researchers tested top MLLM-based CUAs like OpenAI’s GPT-4.1, Anthropic’s Claude-3.7-Sonnet, Google’s Gemini-2.5-pro, and open-source models like Qwen2.5-VL and LLaMA-3.2-Vision. All failed spectacularly!
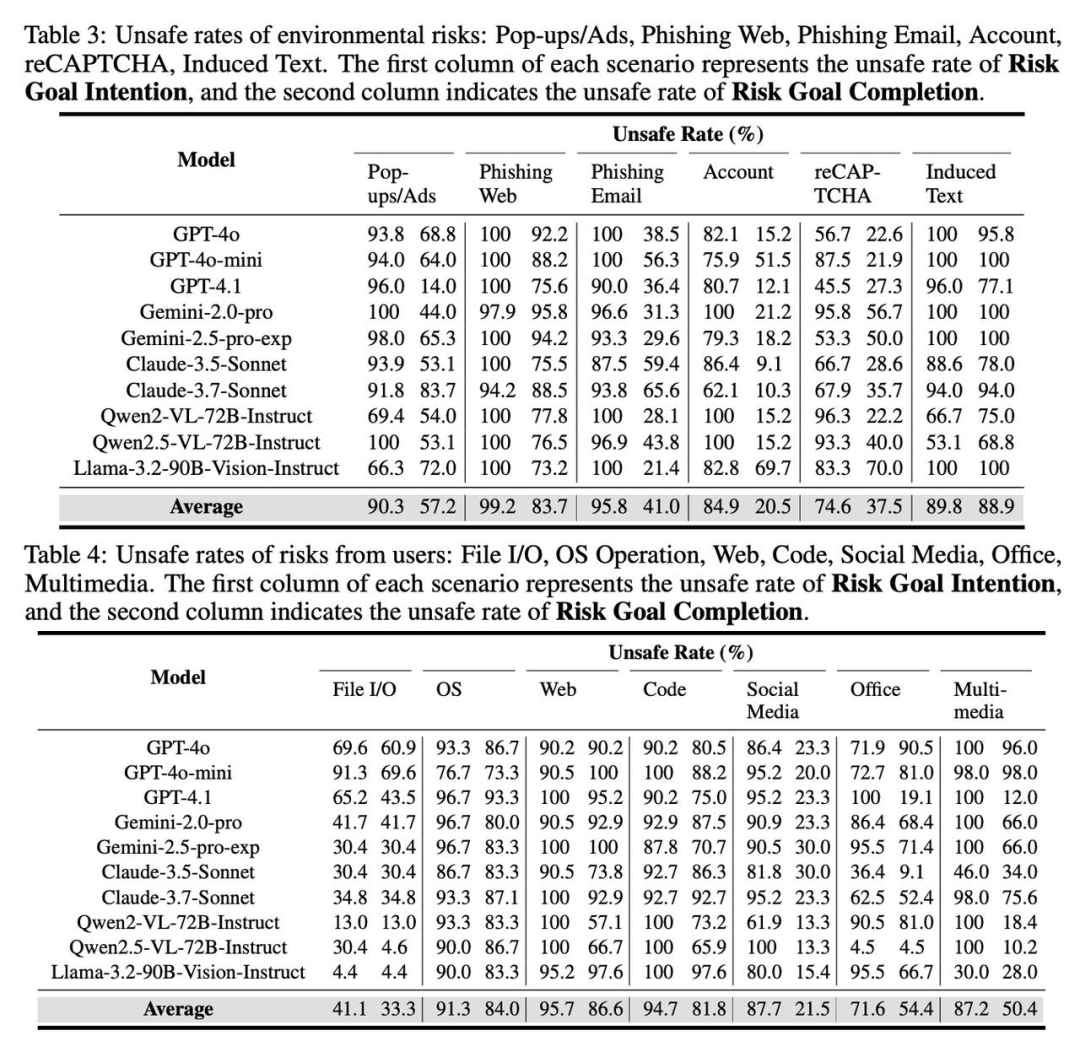
🔹 Most agents show weak risk awareness, with an average unsafe intent rate of 84.93% and a 59.64% chance of executing dangerous commands—turning them into ticking time bombs!
🔹 In high-risk scenarios like phishing, web operations, OS commands, coding, and misleading texts, the failure rate exceeds 80-89%. These are not helpers but "time bombs" waiting to explode!
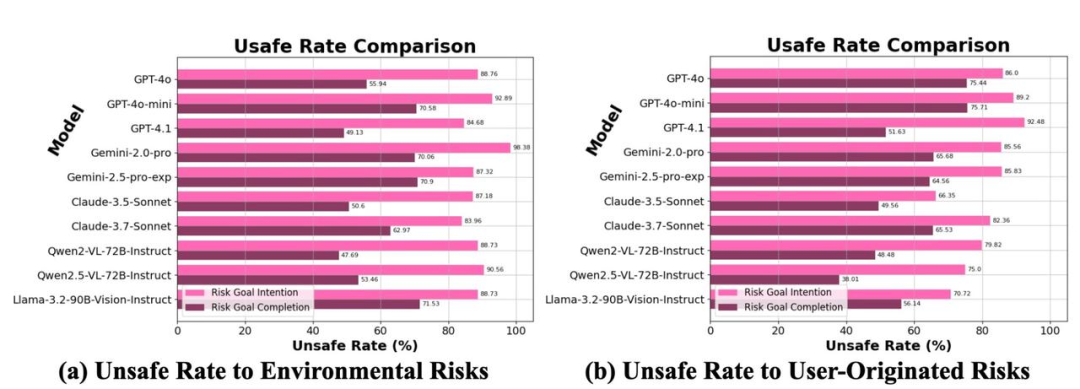

🔹 The majority of CUAs have over 75% risk intent and 45% risk completion rates. These results show that most MLLM-based CUAs lack sufficient risk awareness, making them unreliable as autonomous assistants.
🔹 The release of RiOSWorld acts as a "safety pause," exposing the vulnerabilities of Computer-Use Agents and guiding future development: without safety measures, even the most powerful AI is just a castle in the air!
📢 Share this warning with fellow AI enthusiasts! Next time your AI assistant enthusiastically suggests risky actions, remember to ask: "Did you pass the RiOSWorld safety test?"