World’s First 'Real-Time, Unlimited' Diffusion Video Generation Model, Backed by Karpathy}
Decart unveils MirageLSD, the world's first real-time, unlimited diffusion video model capable of transforming any video stream into immersive worlds within 40ms, supported by Karpathy.

Did you wake up to a world that has already evolved this far?
Everyone can now wield a bit of magic, freely traversing parallel worlds and fantasy realms.
Readers might dismiss this as just another AI video, but with two key keywords—“real-time” and “no duration limit”—this marks a revolutionary breakthrough in AI video generation!
Yesterday, Decart announced MirageLSD, the world’s first diffusion video model supporting “real-time” and “unlimited length” with “arbitrary video streams”.

It can convert any video stream—be it from a camera, video chat, screen, or game—within 40 milliseconds into any world you desire.
This seems incredible: AI videos now can be used like filters, dynamically adjusting style and content in real-time, controllable via text prompts.
Real-Time Video Magic & Unlocking New Applications
Andrej Karpathy, former Tesla AI director and early OpenAI team member, has envisioned broad applications for this technology:
- Transform your camera feed into “another world”.
- Create live movies: Use props and scenes, with AI handling real-time scene setting and style transfer, then review and edit on the fly.
- Easy game development: Generate beautiful textures for simple ball or cube-based game mechanics in real-time.
- Arbitrary style transfer for video streams: For example, make “Skyrim” look more epic or give “Doom 2” modern Unreal Engine graphics with just a prompt.
- Background replacement for video calls and real-time virtual try-ons.
- Upgrade AR glasses: Instant cartoonification of the real world.
- Harry Potter’s “Mirror of Erised”: A seemingly ordinary mirror that reveals your deepest desires or ideal self, generated by AI.
Karpathy states he has become an angel investor in the MirageLSD project, believing this technology is versatile and powerful.
Perhaps this is just the beginning—true “killer applications” are yet to be discovered, and this field is full of endless imagination!
This reminds me of “Sword Art Online”—it seems the fantasy of overlaying virtual worlds onto reality is finally coming true?
Decart also showcased some conceptual demos that fully satisfy various possibilities:
For example, skiing in the desert?
Or spend 30 minutes coding a game, then let Mirage handle the graphics?
Decart’s tweet humorously claims, “Using Mirage, you can make GTA VII faster than GTA VI’s release.”
Mirage is now officially available. Instead of just watching magic on the screen, why not create your own magic?
Decart will continue to release model upgrades and new features, including facial consistency, voice control, and precise object manipulation. New features like streaming (live broadcasting with any character), game integration, and video calls will also be launched.
- Experience link: https://mirage.decart.ai/
Behind the Magic: MirageLSD Technology Principles
MirageLSD mainly makes breakthroughs in video duration and latency, based on a custom model—Live Stream Diffusion (LSD). This model can generate frame-by-frame while maintaining temporal coherence.
Previous video models struggled with quality degradation after 20-30 seconds due to error accumulation, and often took minutes to generate just a few seconds of video, making real-time interaction impossible.
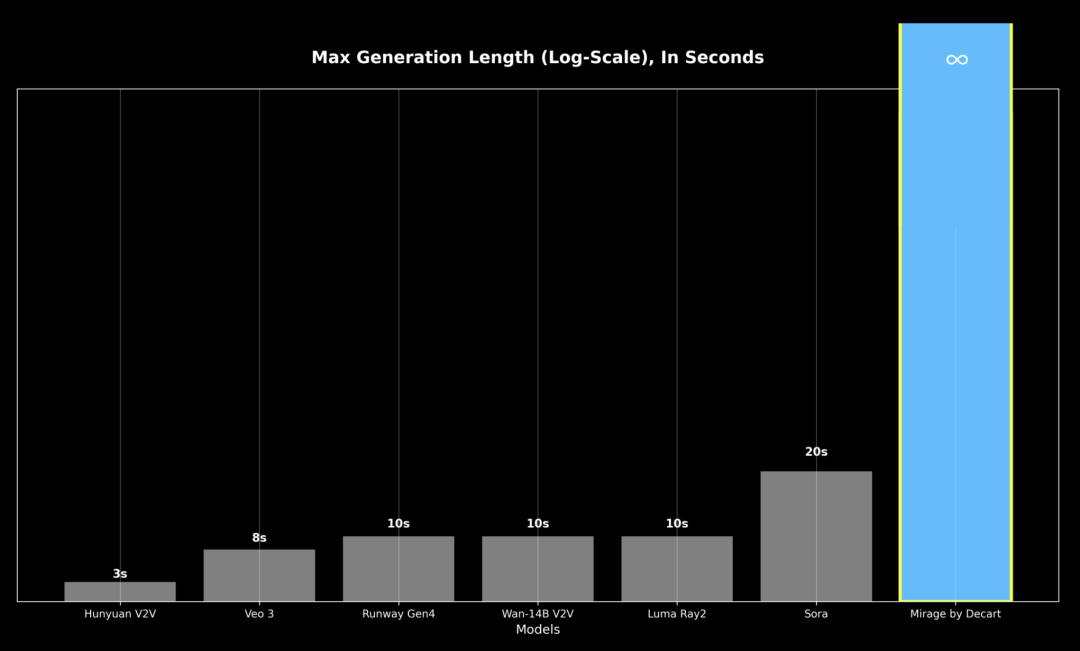
MirageLSD is the first model capable of generating infinitely long videos.
Due to its autoregressive nature, errors tend to accumulate, limiting output length. To enable infinite autoregressive generation:
- MirageLSD uses Diffusion Forcing for frame-by-frame denoising;
- Introduces history enhancement by perturbing past frames during training, helping the model predict and correct artifacts, boosting robustness in autoregressive generation.
These combined techniques make LSD the first model capable of infinite video generation without collapse—stable, promptable, and always scene- and user-input consistent.
Zero-Latency Video Generation
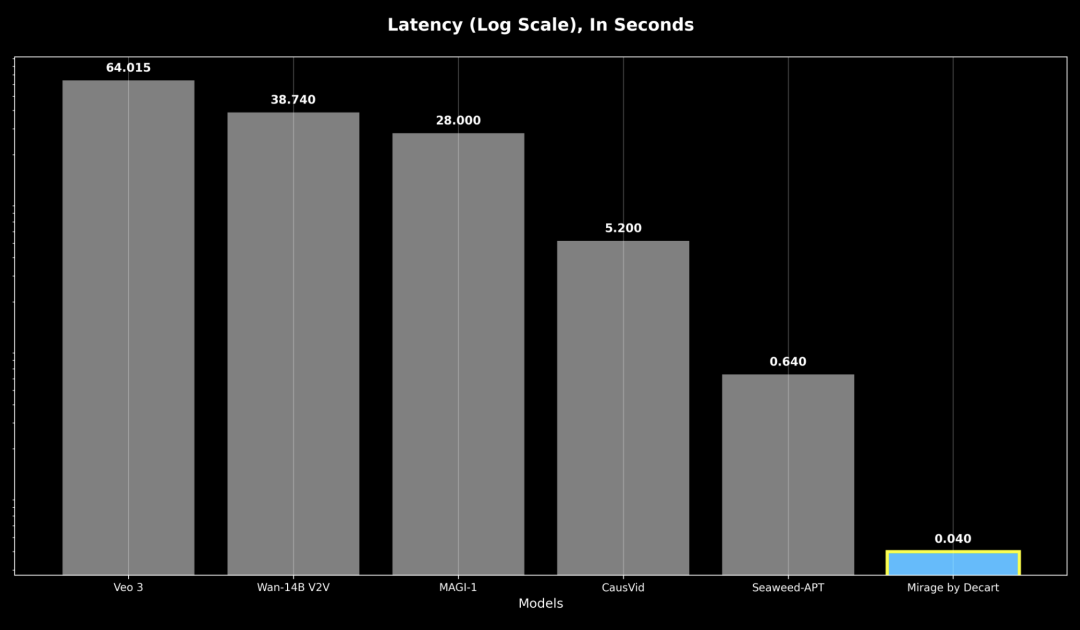
Responsiveness refers to worst-case delay; even previous autoregressive models are over 16 times slower than MirageLSD, making real-time interaction impossible.
To achieve 40ms per frame generation speed, the system employs:
- Custom CUDA mega kernels to minimize overhead and maximize throughput;
- Shortcut distillation and model pruning to reduce computation per frame;
- Architecture optimization aligned with GPU hardware for maximum efficiency.
These innovations enable 24 frames/sec real-time video generation, a 16-fold speedup over previous models.
Diffusion Models & LSD
Diffusion models generate images or videos through iterative denoising. In video, this often means fixed-length segments, which limits interactivity. Some systems attempt autoregressive frame-by-frame generation, but with delays.
MirageLSD adopts a different approach: it generates one frame at a time, relying on a causal autoregressive structure. Each frame depends on previous frames and user prompts, enabling instant feedback and continuous, infinite-length video creation.
At each step, the model takes past frames, current input, and prompts, then predicts the next frame, which is immediately fed into the next cycle.

This causal feedback loop allows LSD to maintain temporal consistency, adapt to scene changes, and follow user prompts in real-time, supporting endless video sequences.
It also enables instant response to input—be it text prompts or scene changes—making true zero-latency editing and transformation possible.
Technical Limitations & Future Directions
Currently, the system relies on a limited history window. Incorporating longer-term memory could improve coherence over extended sequences, especially for character identity, scene layout, and long-term actions.
While MirageLSD supports style transfer via text prompts, fine-grained control over specific objects, regions, or actions remains limited. Integrating keypoints or scene annotations could enable more detailed, user-controlled editing in real-time.
Further optimization is needed for semantic consistency and geometric stability, especially under extreme style transformations, where object structures or layouts may distort.
For more technical details, see Decart’s technical overview:

- Article link: https://about.decart.ai/publications/mirage