Wild DeepSeek Surges Ahead, Outpacing Official Version with Open-Source Weights}
An unofficial DeepSeek variant, DeepSeek R1T2, has gained popularity for its faster speed and competitive performance, with open-source weights available on Hugging Face.

Before the official release of DeepSeek R2, a faster and still powerful variant has emerged!
Recently, a model named DeepSeek R1T2 has become a hot topic!

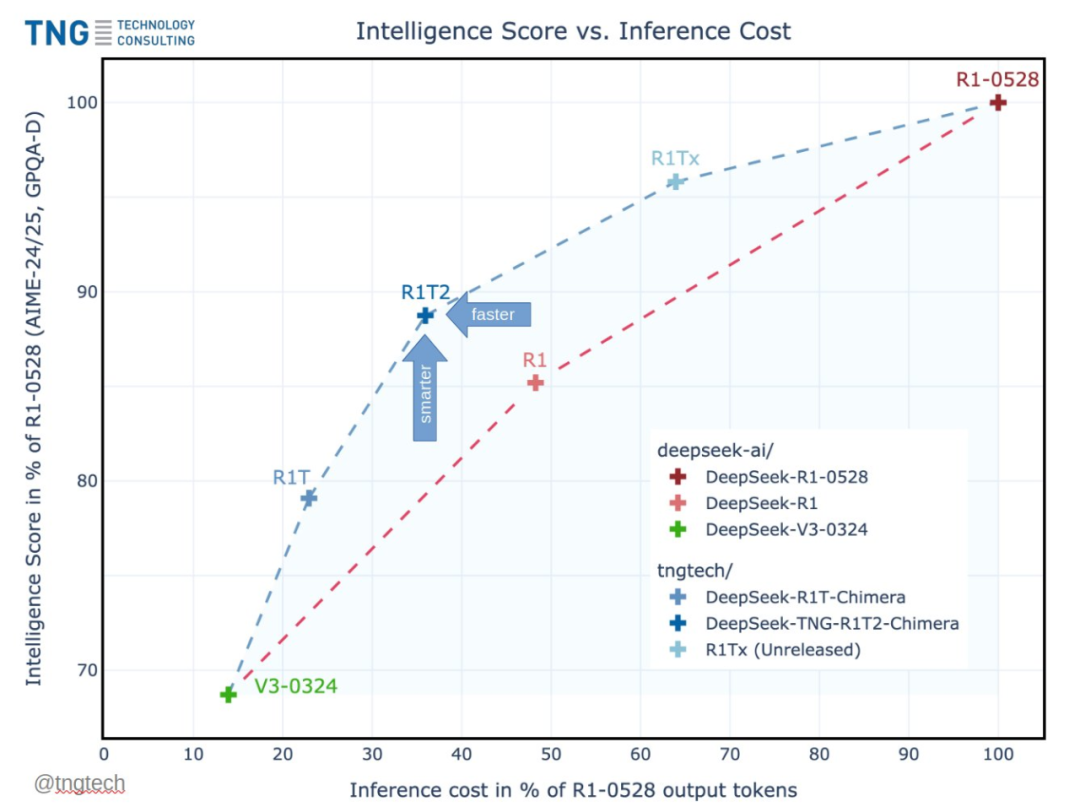
This model’s speed is 200% faster than R1-0528 and 20% faster than R1. Besides its significant speed advantage, it outperforms R1 on GPQA Diamond (expert reasoning benchmark) and AIME 24 (math reasoning benchmark), though it doesn’t quite reach R1-0528’s level.
Technically, it was developed using Assembly of Experts (AoE) technology, integrating DeepSeek’s official models V3, R1, and R1-0528.
Of course, this model is open-source, licensed under MIT, and weights are available on Hugging Face.
Hugging Face link: https://huggingface.co/tngtech/DeepSeek-TNG-R1T2-Chimera
Further investigation reveals that DeepSeek R1T2 is developed by the German AI consulting firm TNG, and its full name is DeepSeek-TNG R1T2 Chimera (hereafter R1T2).
This model not only balances intelligence and output efficiency but also shows a significant leap in reasoning ability and achieves breakthrough think-token consistency compared to the initial R1T Chimera.
Even without system prompts, it maintains stable performance and offers a natural conversational experience.

Some comments mistakenly believe this model is from DeepSeek’s official line, thinking they are just giving models different names instead of following the next-generation version numbering.

Many others recognize that this model “finds the optimal balance between intelligent output token length and speed,” and they are excited about its real-world performance prospects.


Model details overview
On Hugging Face, R1T2 is based on DeepSeek’s R1-0528, R1, and V3-0324 models, built as an AoE Chimera model.
This is a large language model with 671 billion parameters, utilizing DeepSeek’s MoE Transformer architecture.
R1T2 is the first iteration of the initial R1T Chimera model released on April 26. Compared to the dual-base architecture (V3-0324 + R1), it has upgraded to a Tri-Mind fusion architecture, adding the new base model R1-0528.
The model employs AoE technology, achieved through high-precision direct brain edits, resulting in comprehensive improvements and a complete resolution of the original R1T’s think-token inconsistency issues.
The team states that R1T2 has the following advantages over other models:
- Compared to DeepSeek R1: R1T2 is expected to be an ideal replacement, nearly interchangeable, with better performance.
- Compared to R1-0528: If the highest intelligence level of 0528 is not required, R1T2 is more economical.
- Compared to R1T: Usually, R1T2 is recommended unless R1T’s specific personality or speed is critical.
- Compared to DeepSeek V3-0324: V3 is faster, suitable if speed is the priority; but for reasoning, R1T2 is the best choice.
However, R1T2 also has limitations:
- R1-0528, though slower, outperforms R1T2 on high-difficulty benchmarks.
- According to SpeechMap.ai (by xlr8harder), R1T2’s response robustness is higher than R1T but lower than R1-0528.
- It currently does not support function calls; due to R1 base model limitations, function-heavy scenarios are not recommended (may be fixed in future versions).
- Benchmark changes: The development version shifted from AIME24+MT-Bench to AIME24/25+GPQA-Diamond, increasing the performance gap between R1 and the initial R1T compared to earlier data.
Finally, for details on the AoE technology used in R1T2, see the following paper:

- Paper title: Assembly of Experts: Linear-time construction of the Chimera LLM variants with emergent and adaptable behaviors
- Link: https://arxiv.org/pdf/2506.14794
Reference link: https://x.com/tngtech/status/1940531045432283412