What’s the Difference Between AI Agents and Traditional Chatbots? How to Evaluate Them? A 30-Page Review Explained}
This comprehensive 30-page review clarifies the differences between AI agents and chatbots, explores evaluation methods, and discusses the evolution of AI assessment frameworks.


Authors include researchers from Shanghai Jiao Tong University such as Zhu Jiachen, Rui Renting, Shan Rong, Zheng Congmin, Xi Yunjia, Lin Jianghao, Liu Weiwen, Yu Yong, Zhang Weinan, and Huawei Noah Research Institute’s Zhu Menghui, Chen Bo, Tang Ruiming.
The first author is Zhu Jiachen, a PhD student at Shanghai Jiao Tong University, focusing on large model reasoning and personalized agents. The corresponding author is Professor Zhang Weinan, whose research includes reinforcement learning, data science, robotics control, and recommendation search.
Since the advent of Transformers, NLP has undergone revolutionary changes. Large language models (LLMs) have greatly enhanced text understanding and generation, becoming the foundation of modern AI systems. Now, AI continues to advance, with a new generation of autonomous decision-making AI agents rapidly emerging.
Unlike traditional chatbots that only respond to queries, AI agents can access the internet, invoke various APIs, and adapt strategies based on real-time environmental feedback. They possess perception and autonomous decision-making capabilities, breaking free from the limitations of simple Q&A, and can proactively execute tasks and handle complex scenarios, becoming reliable intelligent assistants around users.
In this wave of AI agents, everyone can have their own AI agent. But how to measure whether your AI agent is truly powerful? Numerous evaluation methods are emerging. Are you overwhelmed by choices? How to select the most suitable evaluation approach among countless options? As a developer, are you also pondering how to enhance your 'secret weapon' to stand out in this fierce AI agent competition?
This naturally raises an important question:
What are the fundamental differences between AI agents and traditional chatbots? And how should we scientifically evaluate AI agents?

- Paper Title: Evolutionary Perspectives on the Evaluation of LLM-Based AI Agents: A Comprehensive Survey
- Link: https://arxiv.org/pdf/2506.11102
1. From LLM Chatbots to AI Agents
The paper states that the emergence of AI agents marks a new stage in AI development. They not only respond to human queries but have evolved along five dimensions:
1. Complex Environments: Agents are no longer limited to single dialogue scenarios but can interact with codebases, web pages, operating systems, mobile devices, scientific experiments, and more.
2. Multi-source Instructions: Agents can process not only human inputs but also self-reflection and collaborative instructions from multiple sources.
3. Dynamic Feedback: Operating in continuous, diverse feedback environments, agents can optimize their abilities based on metrics, rewards, and other real-time feedback, moving beyond passive correction.
4. Multimodal Capabilities: Agents can understand and process text, visual, auditory, and other data types across modalities.
5. Advanced Abilities: As external environments grow more complex, agents develop sophisticated planning, persistent memory, and autonomous reasoning, transitioning from reactive to proactive execution.
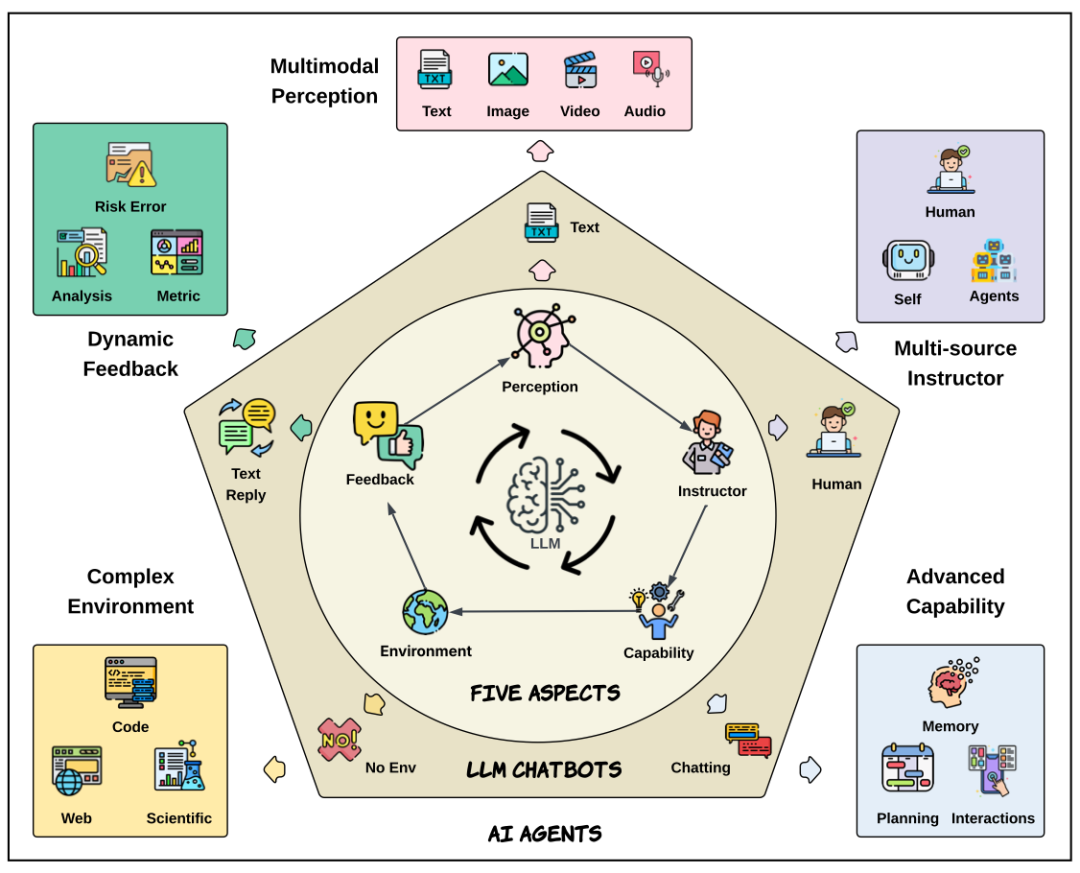
Figure 1: The five dimensions of AI agent evolution from LLM chatbots.
The evolution from LLM chatbots to AI agents is driven by two main factors: increasingly complex external environments and continuous internal capability improvements. The complex external environment pushes agents to grow, while enhanced capabilities motivate exploration of more challenging scenarios. This mutual cycle is the core driver of AI agent evolution. The overall framework (Figure 2) systematically reviews existing evaluation benchmarks, proposing a taxonomy based on 'environment' and 'capability.' It then discusses trends in evaluation methods, covering environment, agent, evaluator, and metric perspectives, and finally offers a methodology for benchmark selection.

Figure 2: Overview of the paper’s framework
2. Evaluation Framework and Benchmark Overview
With the exponential expansion of agent capabilities, traditional chatbot evaluation methods are no longer sufficient. The paper systematically reviews existing AI agent benchmarks, categorizing them into 'environment' and 'capability' dimensions:
1. Environment Dimension: Includes code, web, OS, mobile, scientific, gaming, and other environments.
2. Capability Dimension: Covers planning, self-reflection, interaction, memory, and other advanced skills.
For each environment and capability, the paper compiles representative benchmarks and creates a practical attribute table to help researchers select suitable benchmarks from the overwhelming options. For example, Table 1 lists key attributes such as realism, offline/online, evaluator, input modality, and main challenges, grouping all web environment benchmarks under these attributes.
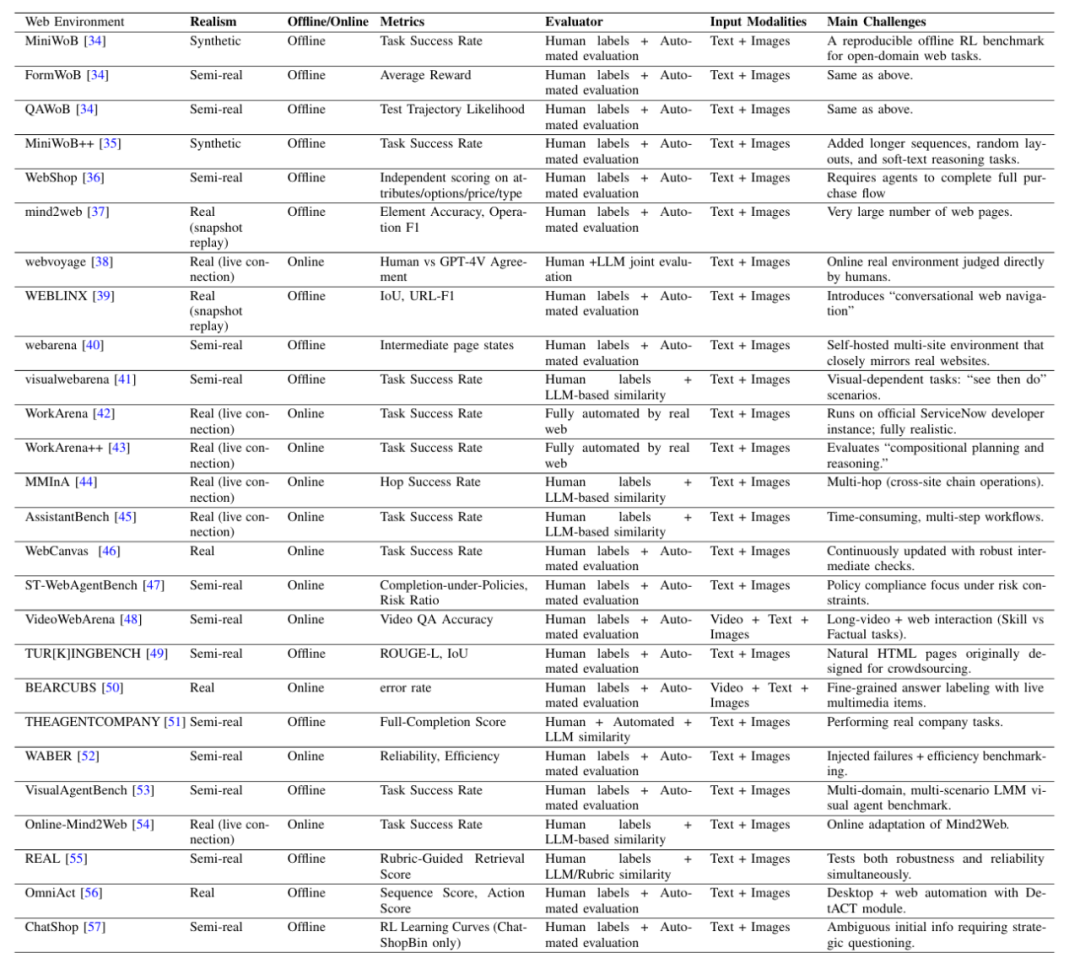
Table 1: Benchmark attributes for web environment agents
3. Evolution of AI Agent Evaluation Methods
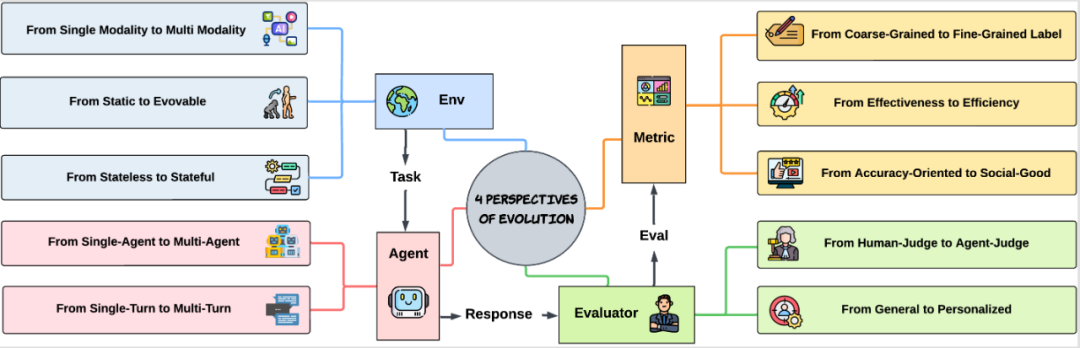
Figure 3: Four perspectives on the future evolution of AI agent evaluation methods
The paper provides a profound summary of future trends in AI agent evaluation, emphasizing that it will evolve from simply 'who answers correctly' to a comprehensive upgrade from four key perspectives:
1. Environment Perspective: From unimodal to multimodal, static to dynamic, and low to high state complexity.
Initially, evaluations focused on text; now, they extend to images, audio, and video. Static datasets are insufficient; real-time, dynamic environments are becoming the norm. Evaluation methods are shifting to assess agent performance and adaptation in continuous tasks, not just final results.
2. Agent Perspective: From single agent to multi-agent, from single-turn to multi-turn interactions.
The new evaluation emphasizes multi-agent collaboration and competition. Tasks evolve from simple Q&A to multi-turn dialogues, ongoing reasoning, and complex task chains, testing global planning and long-term memory.
3. Evaluator Perspective: From human to AI automatic evaluation, from universal to personalized.
AI is no longer just passively rated by humans; more agents can autonomously evaluate peers, enabling scalable, autonomous assessments. Future evaluations will focus on personalized service quality for different users.
4. Metrics Perspective: From coarse to fine granularity, from accuracy to efficiency, safety, and social value.
Single accuracy is no longer sufficient. Future assessments will emphasize task efficiency, decision quality, safety, and ethics, including preventing errors, protecting user interests, and promoting societal good.
4. Action Guidelines: How to Choose the Right Benchmark
Facing rapid AI agent development, the paper proposes a two-stage benchmark selection methodology based on an 'evolutionary perspective':
Stage 1: Current Focus
Identify the environment and capability categories relevant to the task (Figure 2), and match the most suitable benchmarks from the attribute table (Table 1). For example, a developer creating a flight and hotel booking agent should prioritize web environment and interaction benchmarks like WebVoyager and ComplexFuncBench.
Stage 2: Future Considerations
Monitor evolving trends (Figure 3), incorporate new dimensions such as multimodal challenges, safety, and personalization (e.g., BFCL, ST WebAgentBench, PeToolBench) to ensure continuous optimization and evolution of the agent.
Conclusion
AI agents are evolving from 'dialogue systems' to 'action-oriented' systems, driving AI toward a more intelligent, autonomous, and valuable future. Scientific evaluation of AI agents is key to this progress. If you’re interested in how to evaluate new AI agents, this review is a must-read.