VLA Unified Architecture Breakthrough: Autoregressive World Model Leads Embodied Intelligence}
A new VLA framework introduces a fully discrete, autoregressive world model, significantly advancing embodied intelligence with superior perception, reasoning, and decision-making capabilities.


This article features: Wang Yuqi, PhD from the Institute of Automation, Chinese Academy of Sciences, focusing on world models, autonomous driving perception, and decision-making, with multiple publications at top conferences like CVPR, NeurIPS, ICCV, ECCV, ICLR.
Wang Xinlong’s team at Beijing Academy of Artificial Intelligence, leading the core work on the Emu series of native multimodal large models.
Zhang Zhaoxiang’s team at the Institute of Automation, CAS, focusing on world models, visual generation and reconstruction, autonomous driving, and embodied intelligence.
From Sora to Genie2, from language-driven video generation to interactive world simulation, world models are accelerating as a key foundation connecting perception, understanding, and decision-making. The rapid development of visual-language-action (VLA) models is reshaping the boundaries between multimodal data.However, current methods mainly focus on language modality, often neglecting the rich temporal dynamics and causal structures embedded in visual information.To address this, Beijing Academy of Artificial Intelligence and CAS Institute of Automation propose UniVLA — a novel VLA architecture based on a fully discrete, autoregressive mechanism, modeling visual, language, and action signals natively. During post-training, it incorporates world model training, learning temporal and causal logic from large-scale videos, effectively enhancing downstream decision-making performance and learning efficiency.UniVLA has set new SOTA records on mainstream embodied intelligence benchmarks such as CALVIN, LIBERO, and SimplerEnv, demonstrating broad potential in real-world scenarios like robot control and autonomous driving.
- Paper Title: Unified Vision-Language-Action Model
- Project Website: https://robertwyq.github.io/univla.github.io/
- Code Repository: https://github.com/baaivision/UniVLA
A Fully Discrete, Autoregressive Multimodal Model
This framework converts visual, language, and action signals into discrete tokens, constructing a multimodal spatiotemporal sequence for native unified modeling. It employs an autoregressive training paradigm, which is efficient, stable, and scalable.
Thanks to this temporal multimodal representation, the model supports various tasks such as visual understanding, text-to-video, and action prediction, demonstrating strong generalization and data expansion capabilities.
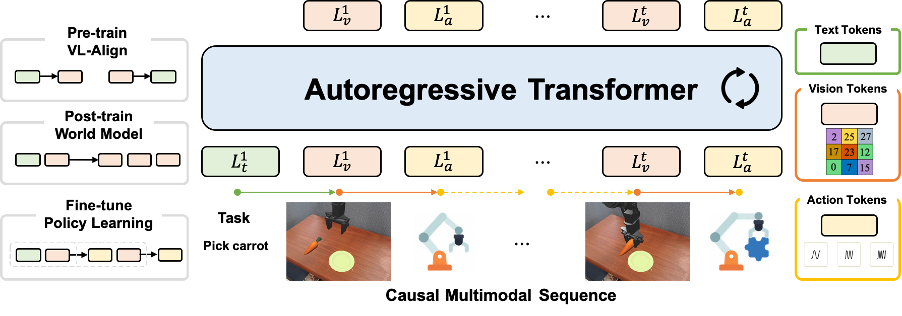
Unified vision-language-action model architecture
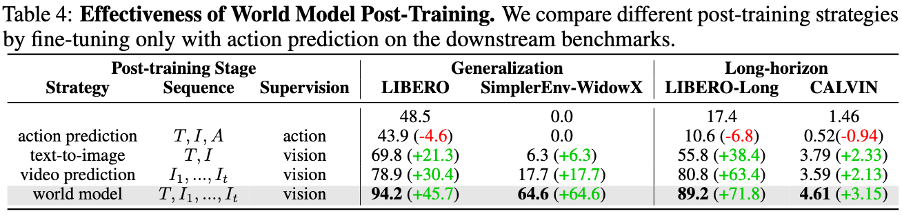
World Model Enhances Downstream Decision-Making
Within this unified framework, post-training of the world model significantly improves downstream decision performance, learning efficiently from large-scale videos without relying on extensive action data. Temporal dynamics and semantic alignment are crucial, opening new pathways for robots to learn real-world knowledge from videos, showcasing the potential of world models in multimodal perception and decision fusion.
Refreshes Multiple Simulation Benchmarks
This approach demonstrates strong performance on mainstream embodied simulation benchmarks such as CALVIN, LIBERO, and SimplerEnv, setting new records across various tasks.
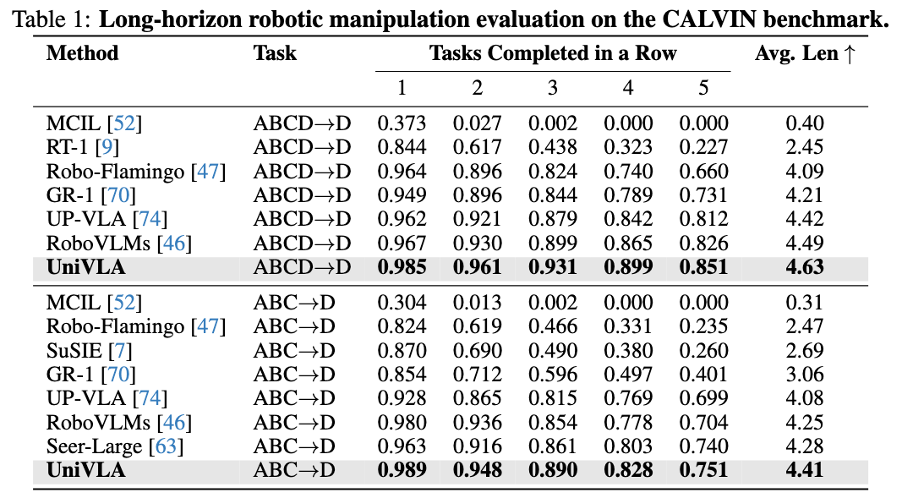
CALVIN Long-term Task Evaluation
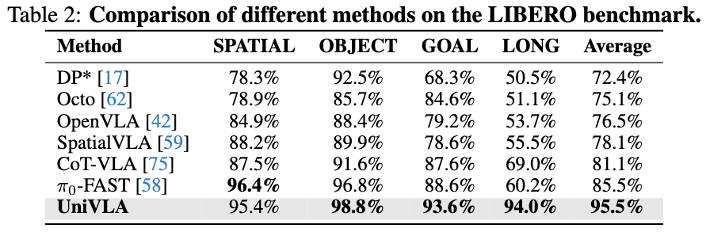
LIBERO Generalization Evaluation
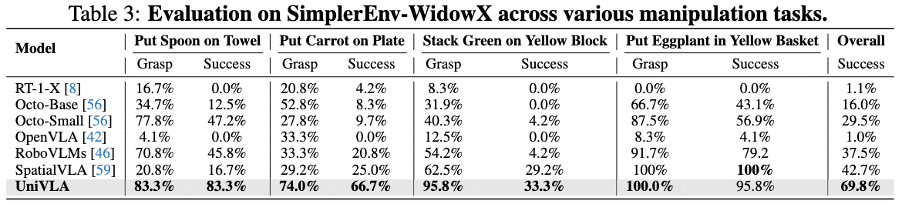
SimplerEnv Generalization Test
Unlocking broader applications: real robot dual-arm manipulation and end-to-end driving.
Exploring New VLA Techniques
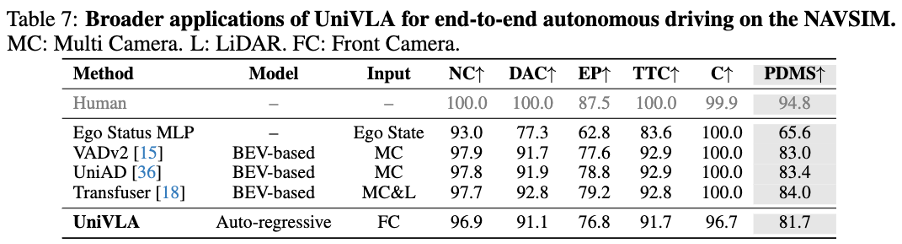
Compared to VLM-based VLA frameworks, this new approach demonstrates greater potential and exploration space. We built a video version of the VLA architecture, enabling the model to effectively capture spatiotemporal dynamics and utilize historical information during inference. Even without action labels, training on large-scale videos yields significant downstream advantages.
Additionally, we introduced a fully discrete autoregressive training paradigm, greatly improving training efficiency and scalability. Future work will explore deep integration with multimodal reinforcement learning, advancing perception, understanding, and decision-making in open worlds.