VLA New Inference Paradigm! CEED-VLA Achieves 4x Speedup with Consistency Models}
CEED-VLA introduces a novel inference approach that significantly accelerates Vision-Language-Action models, boosting efficiency by over four times while maintaining high task success rates.


First author: Song Wenxuan, a first-year PhD student at HKUST (Guangzhou), specializing in VLA models. Co-first author: Chen Jiayi, research assistant at HKUST (Guangzhou). Project leader: Ding Pengxiang, joint PhD at Zhejiang University and Westlake University. Corresponding author: Professor Li Haaoang, CVPR 2025 Best Paper Candidate.
Recent years have seen Vision-Language-Action (VLA) models become a key research area in robotics due to their multimodal understanding and generalization capabilities. Despite progress, inference speed remains a bottleneck, especially in high-frequency and fine manipulation tasks.
Some studies proposed Jacobi decoding as an alternative to autoregressive decoding to improve efficiency. However, due to the high iteration count required, the acceleration effect is limited in practice.
To address this, we propose a consistency distillation training strategy that enables the model to predict multiple correct action tokens simultaneously during each iteration, thus accelerating decoding. We also designed a mixed-label supervision mechanism to mitigate error accumulation during distillation.
Despite these improvements, low-efficiency iterations in Jacobi decoding still limit overall speed. Therefore, we introduce an early-exit decoding strategy, relaxing convergence conditions to further boost average inference efficiency.

- Paper title: CEED-VLA: Consistency Vision-Language-Action Model with Early-Exit Decoding
- Project homepage: https://irpn-eai.github.io/CEED-VLA/
- Paper link: https://arxiv.org/pdf/2506.13725
- Code repository: https://github.com/OpenHelix-Team/CEED-VLA
Experimental results show that our method achieves over 4x inference speedup across multiple baseline models, maintaining high task success rates in both simulation and real robot tasks. This demonstrates the high efficiency and versatility of our approach in robotic multimodal decision-making, with promising applications. Our main contributions include:
1. A general acceleration method CEED-VLA that significantly improves inference speed while preserving control performance.
2. A consistency distillation mechanism combined with mixed-label supervision to retain high-quality action sequences.
3. Identification of inefficient iterations in Jacobi decoding and the proposal of an early-exit decoding strategy, achieving 4.1x inference acceleration and over 4.3x decoding frequency increase.
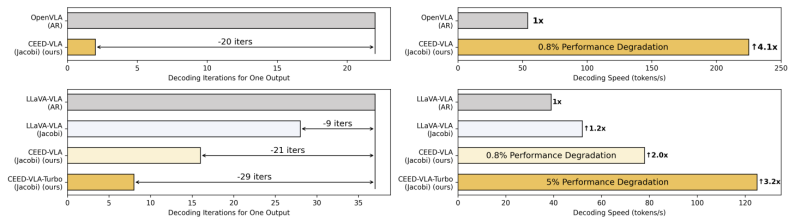
Figure 1: Comparison of acceleration effects with different decoding methods
Method
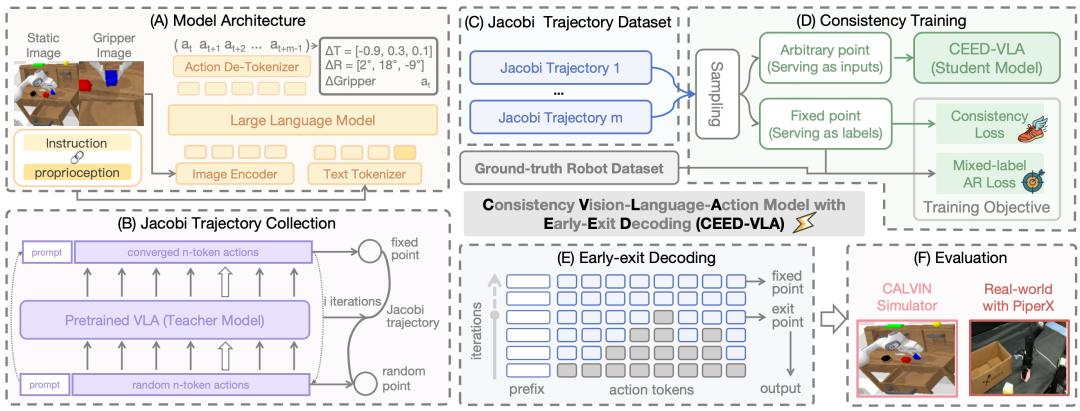
We first generate Jacobi trajectories using pre-trained VLA models (e.g., LLaVA-VLA and OpenVLA). Then, we train a student model via a highly efficient consistency distillation method, incorporating a novel mixed-label supervision approach that balances accuracy and speed. Finally, we apply an early-exit decoding technique to further accelerate inference. Experiments in simulation and real-world environments show that this method significantly boosts inference speed and task success rate with minimal performance loss.
Consistency Training
For the target VLA model, to capture the intrinsic consistency of Jacobi trajectories, we collect complete trajectories by using Jacobi decoding on robot datasets C for action prediction.
Consistency training involves two objectives: Consistency Loss, guiding the model to predict multiple correct tokens in a single forward pass, using KL divergence to ensure intermediate predictions align with the final output, improving convergence efficiency.
Mixed-label autoregressive supervision combines teacher model data and ground-truth data to preserve the model's autoregressive generation ability, with the overall training loss being a weighted sum of both.
Training process is illustrated in Figure 4.
Early-exit Decoding
To address the inefficiency caused by strict convergence in Jacobi decoding, we propose an early-exit strategy: the model outputs intermediate predictions by early stopping, significantly increasing inference frequency and enabling high-frequency control in real-time tasks.
Simulation benchmark results (Figure 6) show that our method achieves over 4x inference speedup and more than 4.3x increase in decoding frequency, with minimal impact on task success rate.
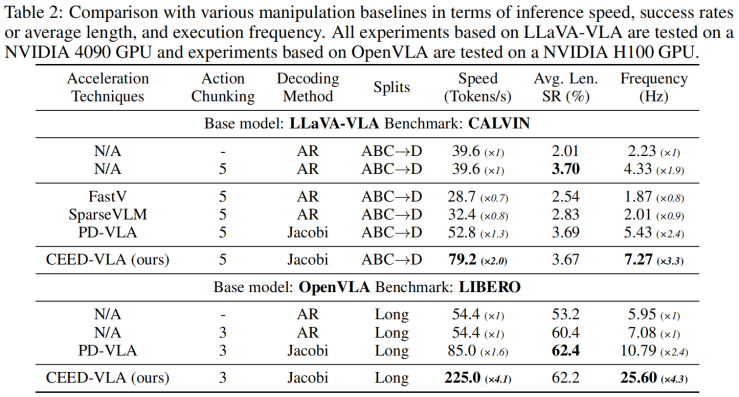
Figure 6: Main experimental results in simulation environment
In real-world deployment, as shown in Figure 9, the CEED-VLA model significantly improves inference speed and control frequency, enabling the robot to perform agile tasks more effectively. The success rate in dexterous tasks like towel stacking exceeds 70%, demonstrating practical advantages.
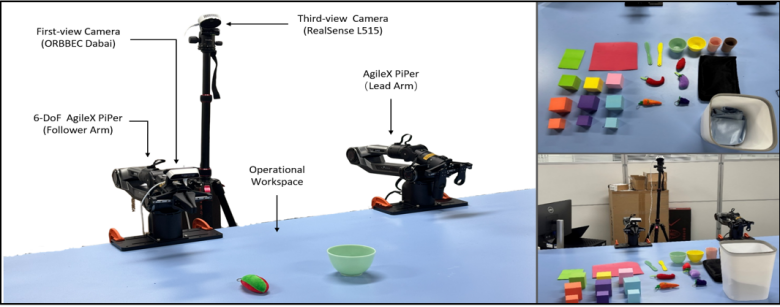
Figure 9: Deployment setup in real robot environment
The results show that CEED-VLA's high inference frequency allows the robot to learn and execute high-frequency actions, greatly improving dexterous task success rates, which surpass 70% compared to baseline methods.