This Diffusion LLM Is Too Fast! No 'Please Wait' — Real-World Speed Test Outperforms Gemini 2.5 Flash}
Mercury, a diffusion-based LLM, achieves unprecedented speed, completing tasks in seconds—over 7 times faster than Gemini 2.5 Flash, demonstrating a new era of ultra-fast AI models.

In the blink of an eye, Mercury completes the task.
“We are excited to launch Mercury, the first commercial diffusion-based LLM tailored for chat applications! Mercury is extremely fast and efficient, providing real-time responses just like Mercury Coder does for coding.”

Recently, AI startup Inception Labs announced exciting news on X (formerly Twitter). Co-founder Stefano Ermon, one of the inventors of diffusion models and a co-author of the original FlashAttention paper, shared insights. Both Aditya Grover and Volodymyr Kuleshov, PhDs from Stanford, are now professors at UCLA and Cornell, respectively.

How does Mercury perform? Let’s look at an official demo:
The video shows a user learning Spanish. The user asks Mercury for common greetings and their meanings. Mercury responds almost instantly, delivering common Spanish greetings and meanings in just a blink of an eye, showcasing incredible speed.
Diffusion models have long been dominant in image and video generation. However, their application to discrete data, especially in language, remains limited to small-scale experiments. Compared to autoregressive models, diffusion models excel in parallel generation, significantly boosting speed, control, reasoning, and multimodal data handling.
Scaling diffusion models to large modern LLMs while maintaining high performance remains an unsolved challenge.
Mercury was created to address this. It is the first diffusion-based LLM, achieving state-of-the-art performance and efficiency compared to autoregressive models.
According to third-party benchmark provider Artificial Anlys, Mercury rivals cutting-edge models like GPT-4.1 Nano and Claude 3.5 Haiku, with over 7x faster inference speeds.
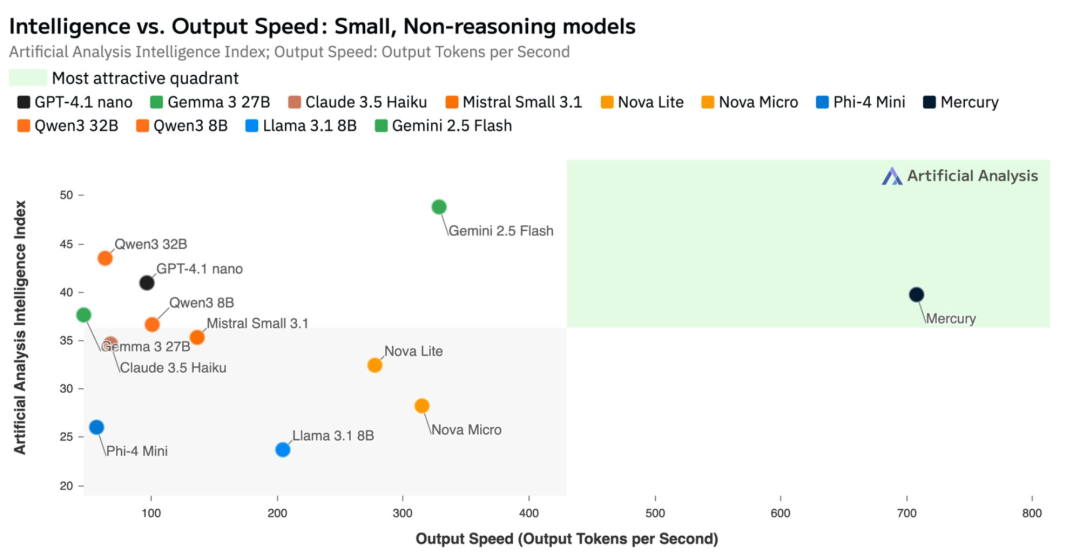
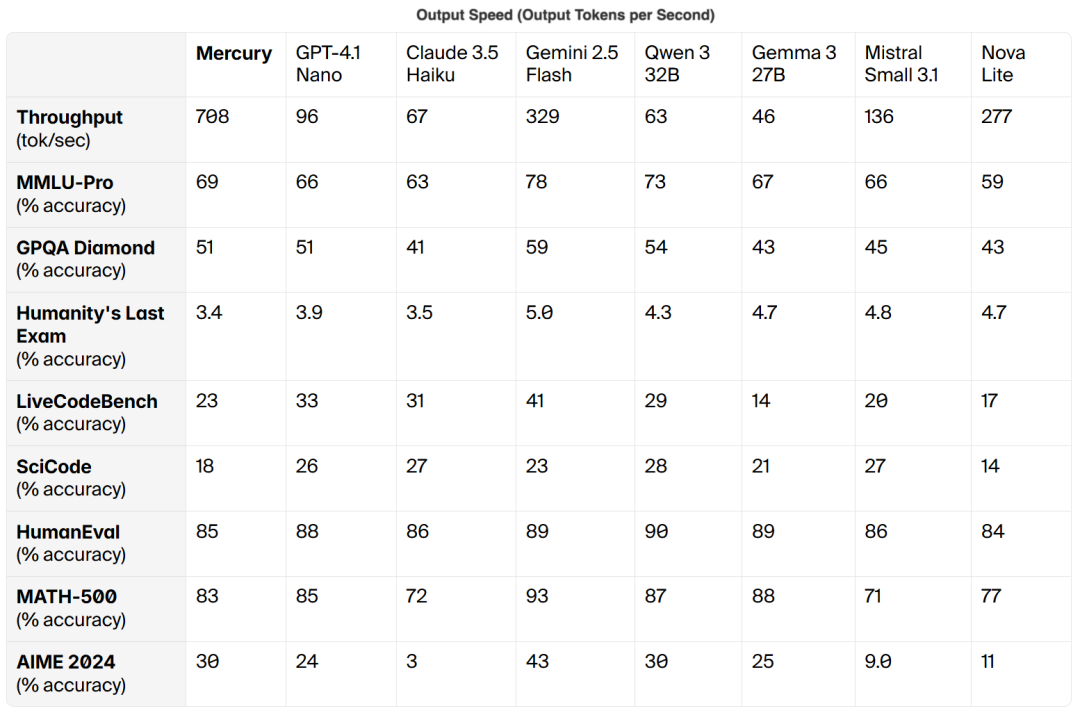
Mercury also demonstrates exceptional capabilities in other scenarios.
First, in real-time speech applications. Thanks to its low latency, Mercury supports translation services and call center agents. Tests on standard NVIDIA hardware show latency outperforming Llama 3.3 70B running on Cerebras systems.
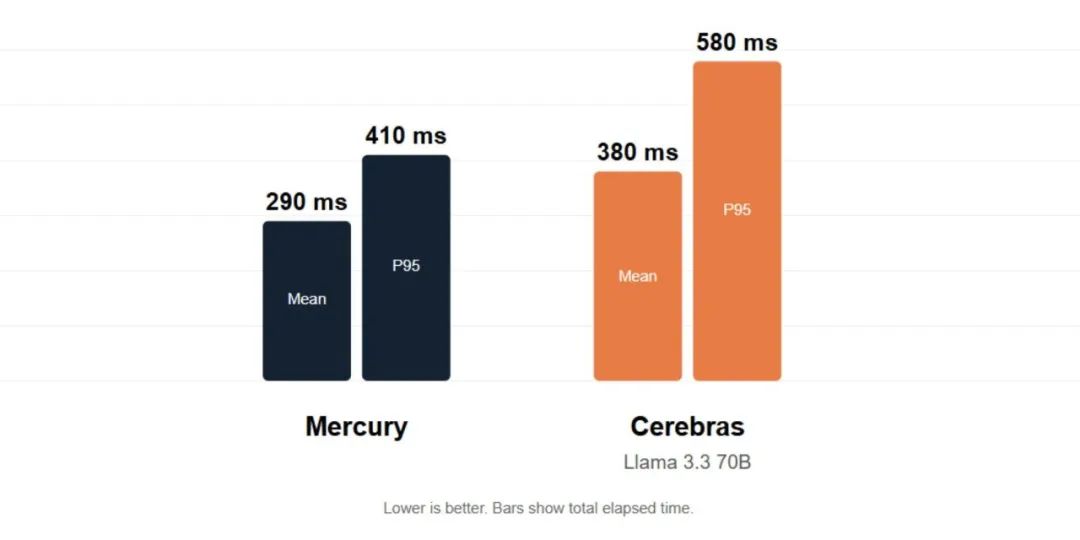
Second, in interactivity. Mercury partners with Microsoft NLWeb. When combined, NLWeb offers lightning-fast, natural conversations. Compared to models like GPT-4.1 Mini and Claude 3.5 Haiku, Mercury ensures smoother user experiences.
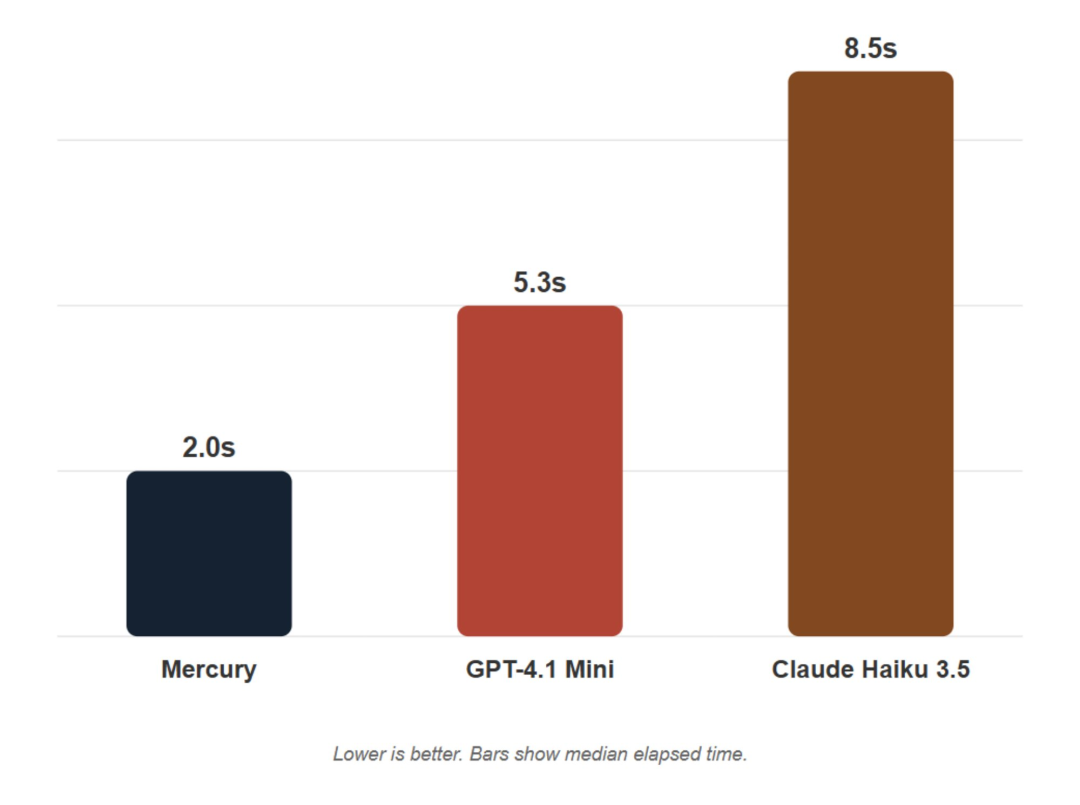
Inception Labs also released a technical report on Mercury. Interested readers can explore more details.

- Paper Title: Mercury: Ultra-Fast Language Models Based on Diffusion
- Demo Link: https://poe.com/Inception-Mercury
It’s clear that Mercury is a significant step toward the future of diffusion-based language modeling, poised to replace current autoregressive models with its speed and power.
To verify its real-world performance, TechInsight conducted hands-on testing.
Firsthand Experience
Initial tests of Mercury’s reasoning abilities answered correctly on classic questions like “Is 9.11 larger than 9.9?” and “How many ‘r’s are in ‘Strawberry’?”
However, it struggled with more complex questions like “Why did the father of a red-green colorblind girl break down?”
Next, we tested its coding ability by asking Mercury, Gemini 2.5 Flash, and GPT-4.1 Mini to generate the same script task: “Create a 1000-word TypeScript game script with character classes, attack logic, enemy AI, and UI initialization.”
It’s evident that Mercury generates text extremely quickly, completing tasks in just a few seconds, while Gemini and GPT produce text more slowly, like a typewriter.
Next, we evaluated the quality, with GPT-3 acting as a judge. Despite Mercury’s speed, its output quality still needs improvement.
Finally, we asked Mercury some everyday questions, and it responded with rapid answers.
