The Future of General Visual Models in the Era of Large Models}
This article explores the evolution of general visual models amidst the rise of large models, discussing challenges, innovations, and future directions in multi-modal visual AI research.


Over the past few years, generalist visual models (VGM) have been a hot topic in computer vision. They aim to build unified architectures capable of handling various visual modalities such as images, point clouds, videos, and multiple downstream tasks like classification, detection, and segmentation, moving towards a "big unified visual model".
However, with the rapid development of large language models (LLMs), research focus has shifted. Multimodal large models now treat visual data as just one of many input modalities, discretizing visual information into tokens and modeling it jointly with text, redefining the independence of visual modalities.
In this trend, traditional visual-centric research on universal visual models seems to be gradually marginalized. Nonetheless, the visual domain should retain its unique features and research priorities. Compared to language data, visual data has strong structure and rich spatial information but faces challenges like large heterogeneity among modalities and difficulty in replacing certain features. For example: how to unify processing of 2D images, 3D point clouds, and video streams? How to design a unified output representation supporting diverse tasks like pixel-level segmentation and object detection? These issues are not fully addressed in current multimodal paradigms.
Therefore, reviewing and summarizing pure visual paradigm research remains meaningful. The team led by Lu Jiwen at Tsinghua University’s Department of Automation recently published a comprehensive review in IJCV, covering input unification methods, task generalization strategies, model architecture design, and evaluation, aiming to inspire future visual model development.

- Paper Title: Vision Generalist Model: A Survey
- Link: https://arxiv.org/abs/2506.09954
What problems does VGM address?
VGM aims to create a unified framework capable of handling multiple visual tasks and modalities. Unlike traditional models designed for specific tasks, VGMs leverage extensive pretraining and shared representations to enable zero-shot transfer across tasks, eliminating the need for task-specific adjustments.
Key capabilities include multi-modal input processing, where data from images, point clouds, and videos are mapped into a shared feature space, and multi-task learning, enabling simultaneous handling of recognition, detection, and analysis tasks within a single model.
Core content overview
Data + Tasks + Evaluation: Foundations for universal modeling
VGMs are trained and evaluated on large, diverse datasets covering images, videos, and point clouds. They are assessed on multiple benchmarks to measure cross-task generalization and multi-modal processing capabilities, with comprehensive reviews of existing benchmarks.
Model design paradigms and techniques
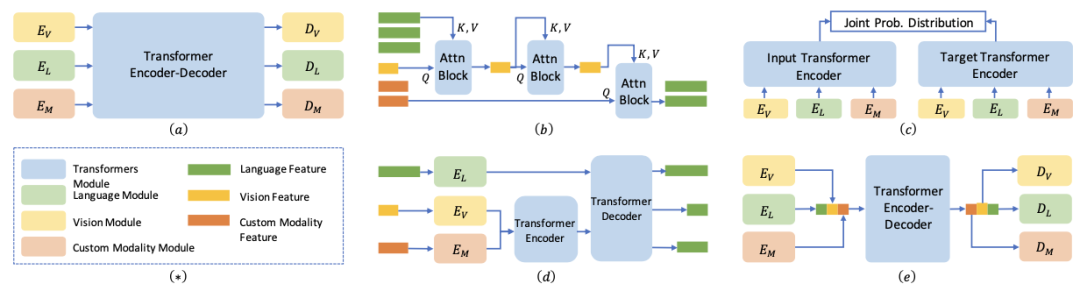
Current design paradigms mainly focus on unifying different visual modalities and diverse task outputs, categorized into two types: encoding-based frameworks and sequence-to-sequence frameworks.
Encoding-based frameworks aim to create shared feature spaces using transformers and domain-specific encoders for different data types, producing unified representations for downstream tasks.
Sequence-to-sequence frameworks borrow from NLP, converting inputs into fixed-length representations and decoding them into outputs, suitable for variable-length tasks like image synthesis and video analysis.
Although not all work is classified as a true VGM, many contribute significantly to multi-modal data integration, architecture design, and multi-task processing, expanding the boundaries of the field. Topics like multi-task learning, vision-language learning, and open vocabulary are also explored.
As a case study, the review compares multiple mainstream VGM models evaluated across 22 benchmarks, providing insights into their performance and future directions.
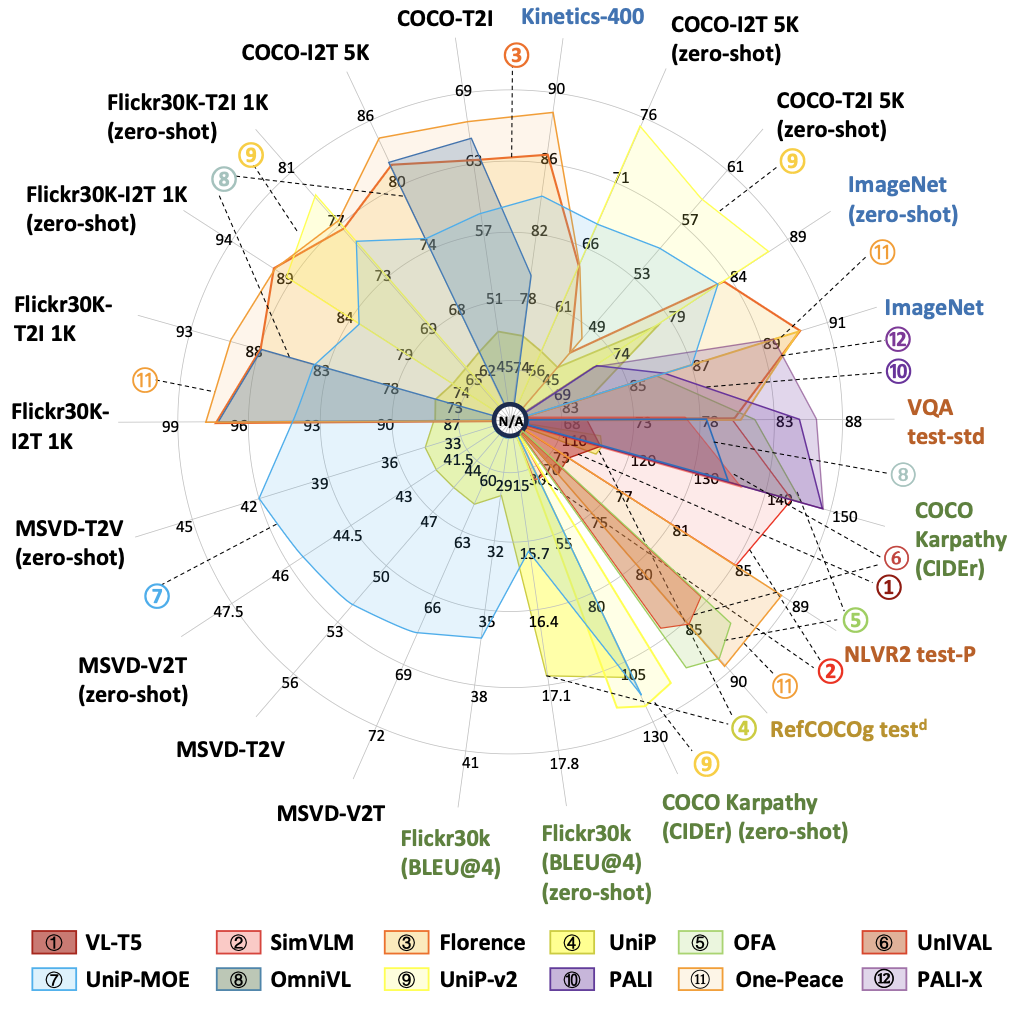
Future of VGMs?
This review summarizes current progress, challenges, and potential in practical applications. While significant advances have been made in handling multi-modal data, issues like training efficiency, data annotation, and ethical concerns remain. Addressing these through automated annotation and unsupervised learning will be key. As models grow larger, fairness, transparency, and safety issues also need attention. VGMs show broad potential in traditional tasks like classification, detection, and segmentation, as well as complex multi-modal applications such as visual question answering, image-text retrieval, and video understanding, impacting fields like surveillance, autonomous driving, and robotics. This review aims to inspire ongoing research and development in the field.