The Collective Failure of Scientific Research Standards! New Benchmark SFE Delivers a Heavy Blow to Mainstream Multimodal LLMs}
The SFE benchmark reveals significant gaps in current large multimodal models' scientific capabilities, exposing their limitations across multiple disciplines and challenging their research validity.


Currently, AI for Science (AI4S) has made notable progress at the tool level, but to become a revolutionary tool, it requires a comprehensive AGI integration. Breakthroughs in large models are gradually transforming scientific research, yet their deep application in science urgently needs rigorous evaluation.
Existing scientific assessments mainly focus on knowledge recall, but real scientific research demands capabilities from raw data perception to complex reasoning across the entire chain. Fields like astronomy, earth sciences, biology, and materials science have vast untapped multimodal data analysis needs.
To address this, Shanghai AI Laboratory’s AI4S team launched Scientists’ First Exam (SFE) — a benchmark system for evaluating the scientific cognition abilities of multimodal large models (MLLMs) across multiple disciplines and high-difficulty tasks.
- SFE technical report: https://arxiv.org/abs/2506.10521
- SFE dataset: https://huggingface.co/datasets/PrismaX/SFE
- SFE benchmark on the Sinan Evaluation Community: https://hub.opencompass.org.cn/dataset-detail/SFE
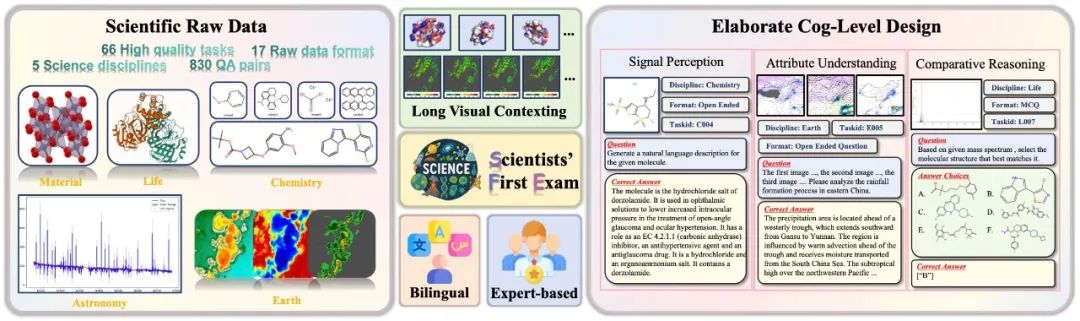
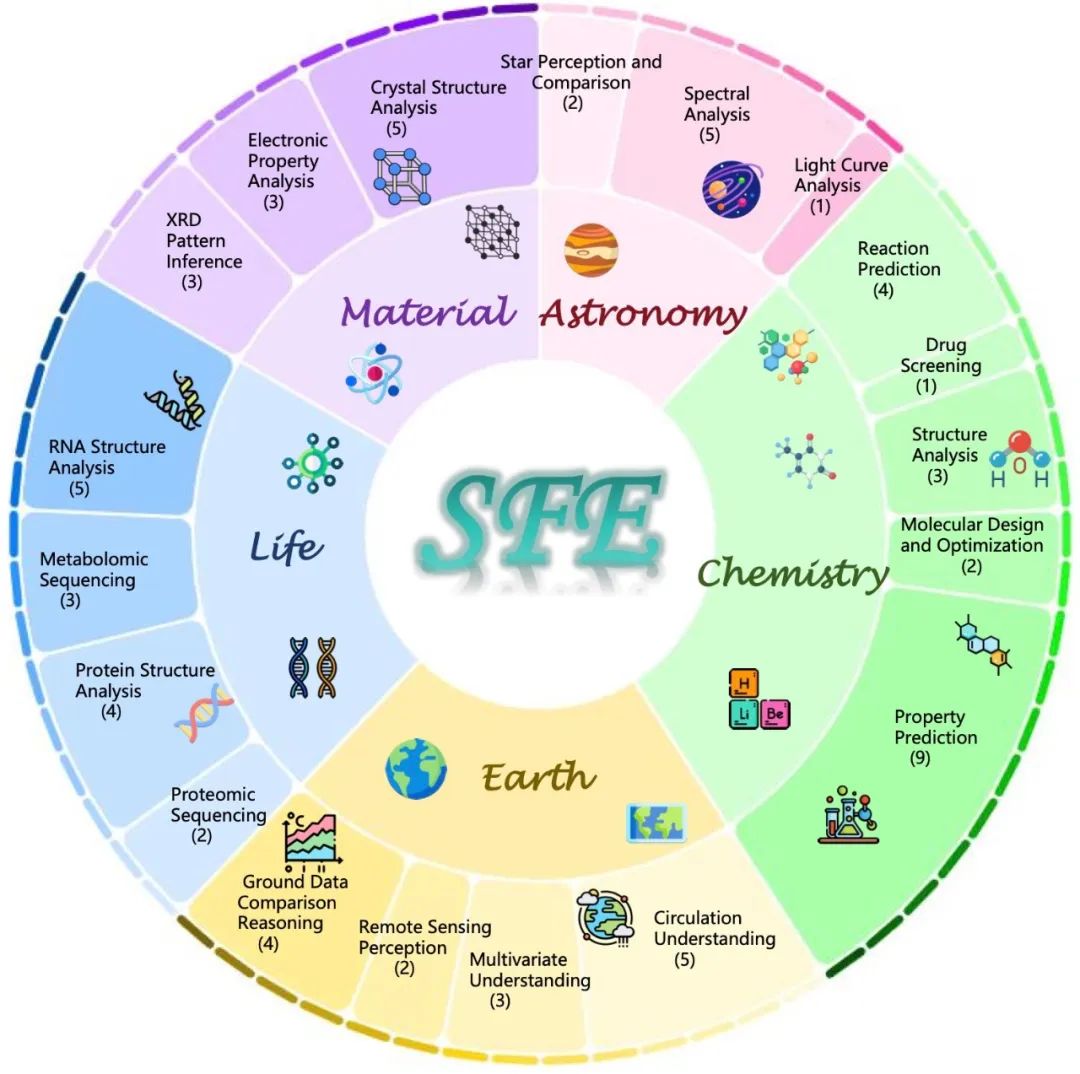
SFE introduces a three-level evaluation system: Signal Perception - Attribute Understanding - Contrast Reasoning, covering 66 high-value tasks across five scientific fields in both raw data and bilingual Q&A formats. Despite excellent performance on traditional benchmarks, mainstream models face significant challenges in high-level scientific tasks (average scores around 30). SFE systematically evaluates these shortcomings, guiding future breakthroughs in scientific AI.
Three-layer cognitive framework for evaluating scientific ability
SFE constructs a three-layer cognitive framework:
- Scientific Signal Perception (L1)
- Scientific Attribute Understanding (L2)
- Scientific Contrast Reasoning (L3)
This comprehensive assessment covers five fields: astronomy, chemistry, earth sciences, biology, and materials science, with 66 expert-designed multimodal tasks based on raw scientific data, presented in visual question answering (VQA) format, supporting bilingual queries. It aims to improve research efficiency and promote scientific progress.
Deep assessment of the scientific capabilities of MLLMs across three cognitive levels
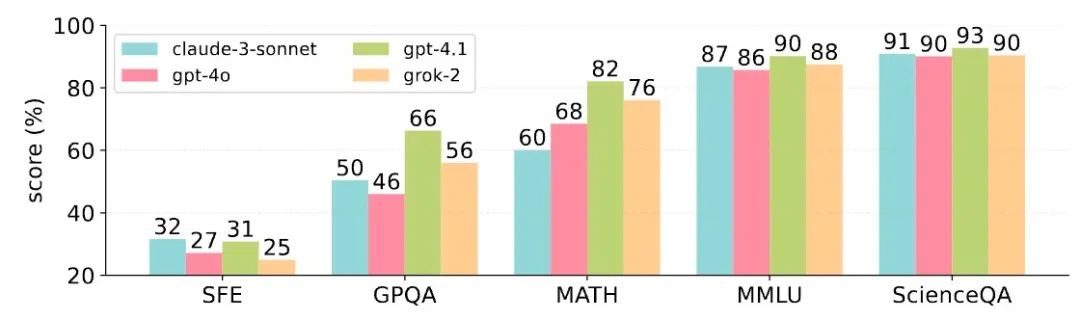
SFE reveals significant performance gaps of mainstream MLLMs in high-level scientific tasks
Evaluation results show that closed-source models (like GPT-3.5, Claude-3.7-Sonnet) outperform open-source models by 6-8% on average in scientific cognition. For example, GPT-3.5 surpasses Gemini-2.5-Pro by over 26%, mainly due to better reasoning efficiency and less redundant thinking during inference, demonstrating SFE’s effectiveness in model differentiation.
Within the same series, models like Claude-3.7-Sonnet have improved by over 7%, reflecting ongoing architecture and training method enhancements. This trend is also evident in the InternVL series, indicating continuous capability growth through innovation.
MLLMs’ performance varies across disciplines
Materials science is the strongest area, with GPT-3.5 achieving 63.44% in English and 58.20% in Chinese tasks, even open-source models like Qwen2.5-VL-72B and InternVL-3-78B exceeding 40%. This advantage stems from structured input data like phase diagrams and X-ray diffraction images, which align well with models’ visual-symbolic processing abilities.
In contrast, astronomy remains challenging due to noisy raw data and weak visual cues, making current models less capable. SFE effectively highlights these strengths and weaknesses across scientific reasoning types.

Scientific ability of MLLMs is shifting from knowledge comprehension to high-level reasoning
SFE’s three-level framework shows that recent models significantly improve in high-level reasoning (L3), with scores rising from 26.64% (GPT-4.1) to 36.48%, while understanding tasks (L2) see limited progress. This indicates that models are advancing in reasoning and tool use, but their knowledge breadth remains relatively unchanged.
For example, InternVL-3 improves by 8% in L3 tasks due to multimodal pretraining and chain-of-thought strategies, but L2 gains are minimal, emphasizing the importance of architecture and training innovations for high-level reasoning.
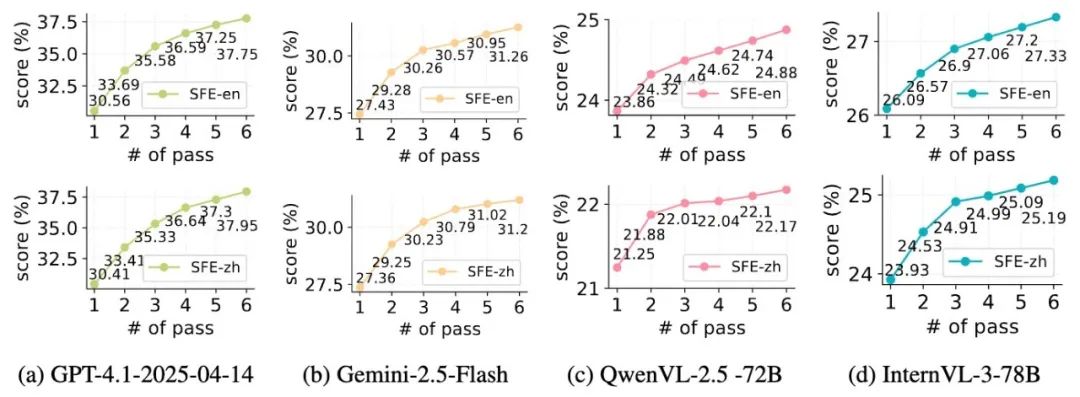
Closed-source models generally outperform open-source models in scalability
Using Pass@k metrics, closed-source models like GPT-4.1 and Gemini-2.5-Flash show higher initial scores (30.56% vs 26.09%) and greater improvements with increased k, indicating richer pretraining data and better exploration-exploitation balance.
These results suggest that closed models benefit from more diverse datasets and training strategies, outperforming open-source counterparts in scientific reasoning and answer quality.

Scaling laws in scientific model sizes
Under the SFE evaluation, models like Qwen2.5-VL-72B and InternVL-3-78B do not always show proportional performance gains with increased size. For instance, Qwen2.5-VL-72B performs worse than smaller models, indicating that scaling alone is insufficient without sufficient scientific data.
SciPrismaX: Building an AI4Science ecosystem
Beyond SFE, the team developed the SciPrismaX platform for scientific evaluation. It includes modules for model capability, disciplinary diversity, evaluation strategies, and tools, aiming to create a rigorous, dynamic AI evaluation ecosystem aligned with scientific research.
Additionally, the platform will maintain a high-quality, continuously updated database of scientific benchmarks through real-time tracking, self-collection, and community collaboration, advancing AI standards in science.
