Target Detection Model 'Thinking' Comes! IDEA Introduces Rex-Thinker: Chain-of-Thought Based Referent Object Detection with Dual Breakthroughs in Accuracy and Interpretability}
IDEA's Rex-Thinker, a novel chain-of-thought-based referent detection model, achieves high accuracy and interpretability, marking a significant advancement in visual object detection.


Caption: Rex-Thinker 的思考过程
In daily life, we often describe and locate specific objects through language: “the person in the blue shirt,” “the cup on the left of the table.” How to enable AI to accurately understand such instructions and locate targets has long been a core challenge in computer vision. Existing methods are often troubled by two major issues: decision process opacity (“black box” predictions) and poor rejection ability (incorrectly outputting results for non-existent objects).

图 1:指代检测的应用场景实例
Recently, IDEA proposed a novel solution Rex-Thinker, which first introduces the “logical reasoning chain” from human thinking into visual referent tasks, allowing AI to think step-by-step and verify evidence like humans. This not only significantly improves accuracy in authoritative evaluations but also demonstrates strong “knowing what it knows” capability!

- Project homepage: https://rexthinker.github.io/
- Online Demo: https://huggingface.co/spaces/Mountchicken/Rex-Thinker
- Paper: https://arxiv.org/abs/2506.04034
- Open-source code: https://github.com/IDEA-Research/Rex-Thinker
What’s the breakthrough? Teaching AI “three-step thinking”
Traditional models directly output detection boxes, but Rex-Thinker innovatively constructs an explainable reasoning framework:
1. Planning: Decompose language instructions, e.g., “Find the person on the turtle” → “Step 1: Find the turtle → Step 2: Determine if each person is on the turtle”
2. Verification: Step-by-step verify each candidate object (e.g., “Person 1,” “Person 2”), binding each analysis to specific image regions (e.g., Person 1 corresponds to the marked person in the image, see Figure 2)
3. Decision: Summarize verification results, output matching coordinates or declare “not found”

图 2: Rex-Thinker 推理示例
Model architecture: Retrieval-based multimodal detection + CoT reasoning
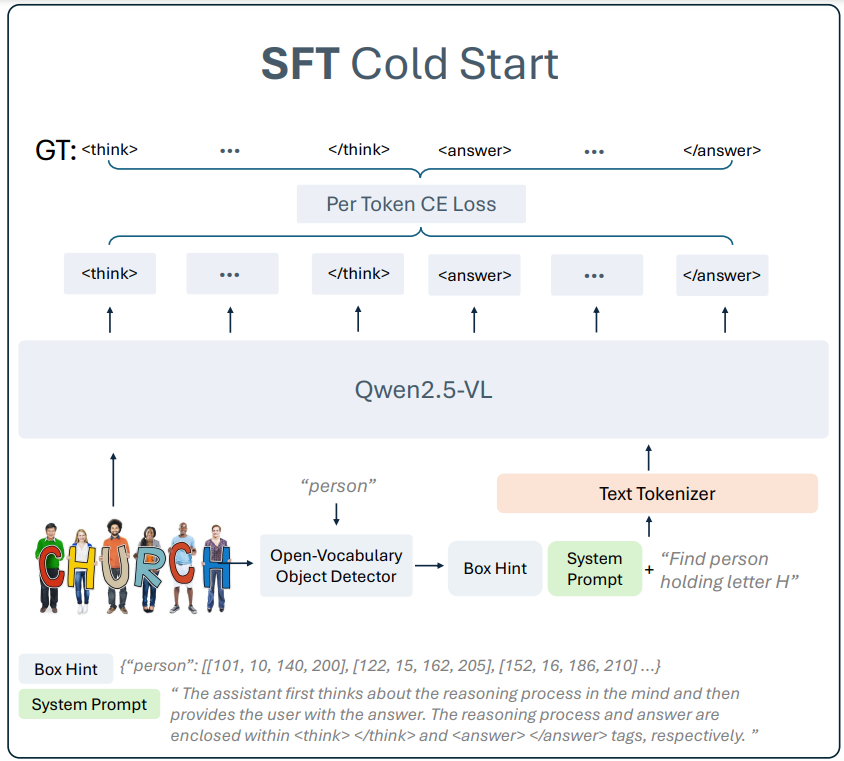
图 3: Rex-Thinker 模型结构
As shown in Figure 3, Rex-Thinker adopts a retrieval strategy-based model design: first, extract all candidate boxes using an open-set detector (e.g., Grounding DINO), then input these candidates into the model for reasoning, and finally output the answer. The process includes:
1. Candidate box generation: Use an open vocabulary detector (e.g., Grounding DINO) to detect all potential target regions as Box Hints;
2. Chain reasoning (CoT Reasoning): Given candidate boxes, the model compares and reasons step-by-step, generating a structured thought process <think>...</think> and the final answer <answer>...</answer>. The input prompt for this process is as follows:

图 4: Rex-Thinker 输入 prompt 构成
3. Output format: The final output is a standardized JSON format of target coordinates, which avoids the difficulty of direct coordinate regression and makes each reasoning step image-based, enhancing interpretability and trustworthiness.
Training process: SFT cold start + GRPO fine-tuning for strong reasoning
Teaching AI to think step-by-step is key. Rex-Thinker employs a two-stage training strategy, starting with high-quality reasoning data.
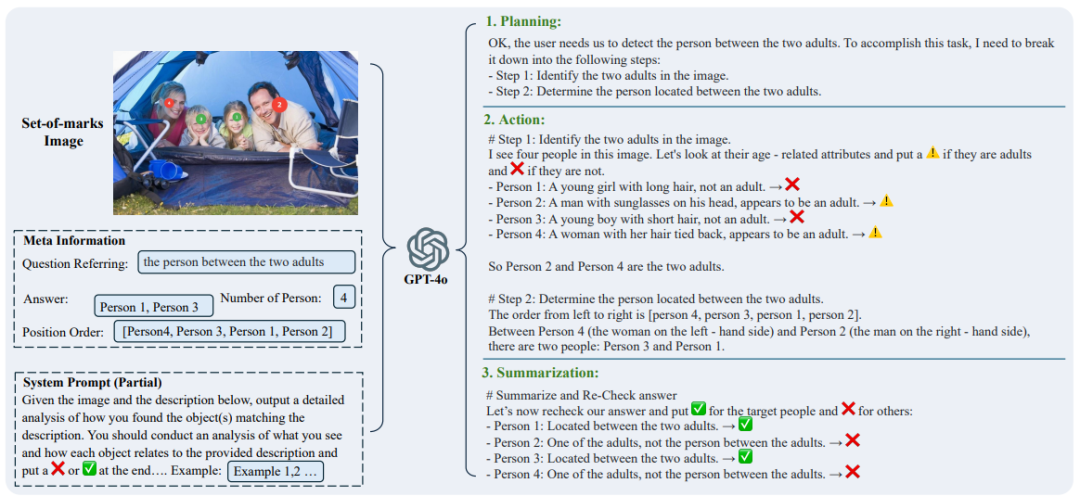
图 5: HumanRef-CoT 数据集构造流程
1. Building reasoning dataset HumanRef-CoT
Starting from the existing HumanRef dataset (focused on multi-object referents), the team used GPT-4o to automatically generate 90,000 chain reasoning examples, creating HumanRef-CoT. Key features include:
- Complete reasoning chains: Each sample follows the “Planning - Verification - Summarization” process.
- Varied reasoning scenarios: Covering single-object, multi-object, attribute combinations, spatial relations, and interactions.
- Rejection samples: Including descriptions with no matching target, training the model to refuse answering when necessary, improving hallucination resistance.
This dataset systematically introduces reasoning chain annotations, laying the foundation for training reasoning-capable visual referent models.
2. Two-stage training strategy

图 6. Rex-Thinker 采用的两阶段训练方法
(1) Cold start training
Supervised fine-tuning (SFT) on HumanRef-CoT to help the model learn basic reasoning framework and output norms.
(2) Post-training with GRPO reinforcement learning
After establishing basic reasoning ability, the model undergoes GRPO reinforcement learning to further improve reasoning quality and robustness. Rewards include F1 accuracy and format regularization, guiding the model to optimize reasoning paths. This mechanism prevents overfitting to a single reasoning path, promoting diversity and generalization. The final result is a model with enhanced reasoning accuracy and robustness, capable of handling unseen categories and complex descriptions, as shown in the model’s reasoning on an unseen category (hotdog).

图 7. Rex-Thinker 在 GRPO 后训练后泛化到任意物体
实验结果:SFT赋予模型CoT能力,GRPO提升泛化能力
在 HumanRef Benchmark 上,Rex-Thinker 展示了显著的性能提升。团队测试了三种模型版本:
- Rex-Thinker-Plain:只训练最终检测结果,无推理监督;
- Rex-Thinker-CoT:加入思维链(CoT)监督,学习“如何思考”;
- Rex-Thinker-GRPO:在CoT基础上,用GRPO强化学习进一步优化推理质量。
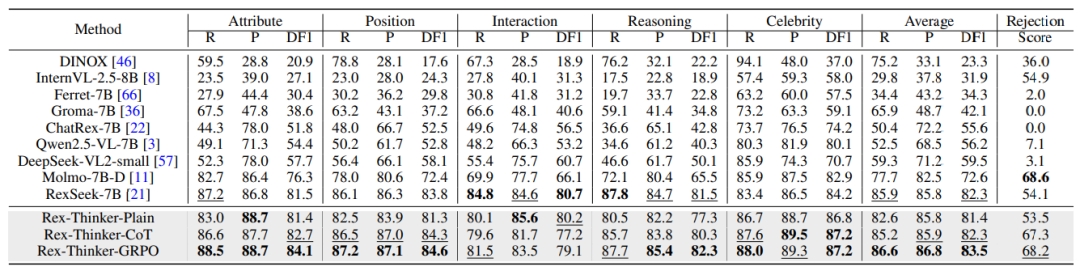
表 1 Rex-Thinker 在 HumanRef Benchmark 上的评测结果
如表 1 所示,加入CoT监督后,模型在各项指标上全面优于基础版本,平均提升0.9点DF1指标,特别是在“拒识”子集上的表现提升尤为明显,Rejection Score提高13.8个百分点,说明推理链引入显著增强了模型对“不存在目标”的识别能力。进一步,GRPO训练在CoT基础上带来额外性能提升,平均DF1提升至83.5。相比单一推理路径监督学习,GRPO引导模型探索更优推理路径,显著改善复杂场景下的鲁棒性和判断准确性。
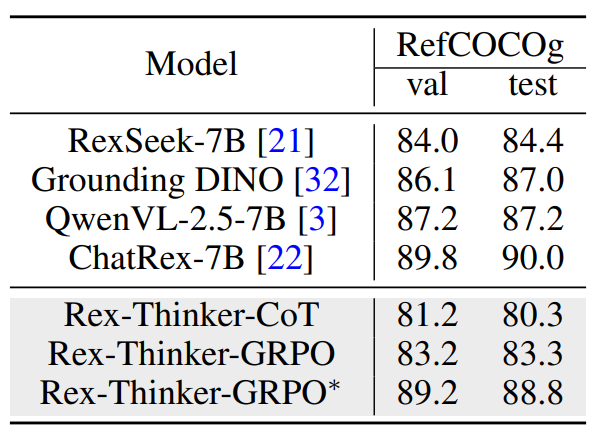
表 2 Rex-Thinker 在 RefCOCOg 数据集上的泛化结果
此外,在RefCOCOg数据集的跨类别评估中,Rex-Thinker表现出良好的迁移能力。在无需微调的情况下,模型仍能准确推理目标位置,展现出优异的泛化能力。通过少量GRPO微调,性能进一步接近甚至超越现有主流方法,验证了该方法在新类别和新任务中的扩展潜力。
可视化结果
接下来展示Rex-Thinker的推理过程可视化,包括每一步条件验证和最终决策输出。图中标注了模型在图像中逐步定位目标、识别条件是否满足,并最终输出或拒绝预测。这些可视化不仅体现了模型的目标理解能力,也突出了推理路径的清晰性和可解释性。在多干扰或目标不存在的场景中,Rex-Thinker能给出详尽的否定推理,展现“知之为知之,不知为不知”的能力。这在传统视觉模型中极为罕见,彰显了思维链机制的实际应用价值。

