Revival of Encoder-Decoder Architecture? Google Releases 32 T5Gemma Models}
Google unveils 32 T5Gemma models, reviving the encoder-decoder architecture, demonstrating its advantages in reasoning and efficiency, challenging the dominance of decoder-only models.


Today is a big day for xAI. Elon Musk announced the release of the Grok 4 large models, drawing attention from the AI community, with a live stream awaited (some are waiting for a spectacle due to recent unpredictable behavior).
Despite this, Google seems unfazed by the spotlight shift and has continued updating its Gemma series models.
First, Google released a series of multimodal models for healthcare AI MedGemma, including 4B and 27B variants: MedGemma 4B Multimodal, MedGemma 27B Text, and MedGemma 27B Multimodal. These models assist in diagnosis and provide medical advice based on images and text, showing strong performance.
Link to Hugging Face: https://huggingface.co/collections/google/medgemma-release-680aade845f90bec6a3f60c4
But the main focus today is on Google's T5Gemma, a series of models based on the encoder-decoder architecture, related to the original T5 (Text-to-Text Transfer Transformer). Unlike the dominant decoder-only models, T5 models incorporate both encoding and decoding, offering high inference efficiency, flexible design, and richer representations, making them ideal for tasks like summarization, translation, and QA.
Google used a technique called “adaptation” to convert pre-trained decoder-only models into encoder-decoder architectures. This involves initializing the encoder-decoder model with weights from pre-trained decoders and further fine-tuning with UL2 or PrefixLM objectives.
In total, Google released 32 different T5Gemma models, varying in size and training objectives, including variants trained with PrefixLM or UL2. They also include models with different configurations of encoders and decoders, supporting flexible combinations like large encoders with small decoders (e.g., 9B encoder with 2B decoder).
- Hugging Face: https://huggingface.co/collections/google/t5gemma-686ba262fe290b881d21ec86
- Kaggle: https://www.kaggle.com/models/google/t5gemma
Although not as popular as Grok 4, T5Gemma has received positive reviews, with some calling it “a strong comeback of encoder-decoder models in the LLM era.”
Some critics argue that the proliferation of models makes it difficult to choose the right one.
From Decoder-Only to Encoder-Decoder
Google explored whether pre-trained decoder-only models could be adapted into top-tier encoder-decoder models. The core idea is to use adaptation techniques, initializing encoder-decoder models with weights from pre-trained decoders, then fine-tuning with UL2 or PrefixLM objectives.
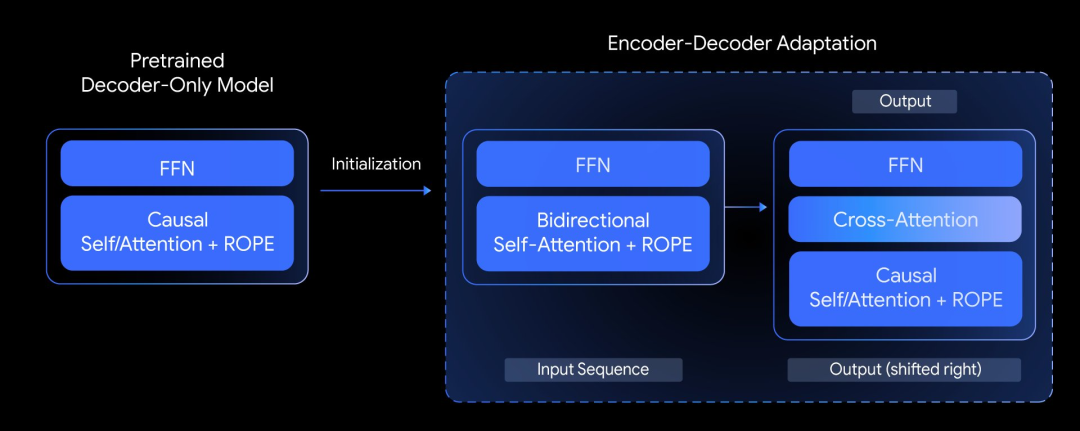
Google published a paper on adaptation in April, demonstrating how to use pre-trained decoder weights to initialize encoder-decoder models, supporting flexible model pairing for specific tasks like summarization or reasoning.
Performance-wise, T5Gemma matches or surpasses the original Gemma models in various benchmarks, such as SuperGLUE, indicating its potential to create more powerful and efficient foundational models.
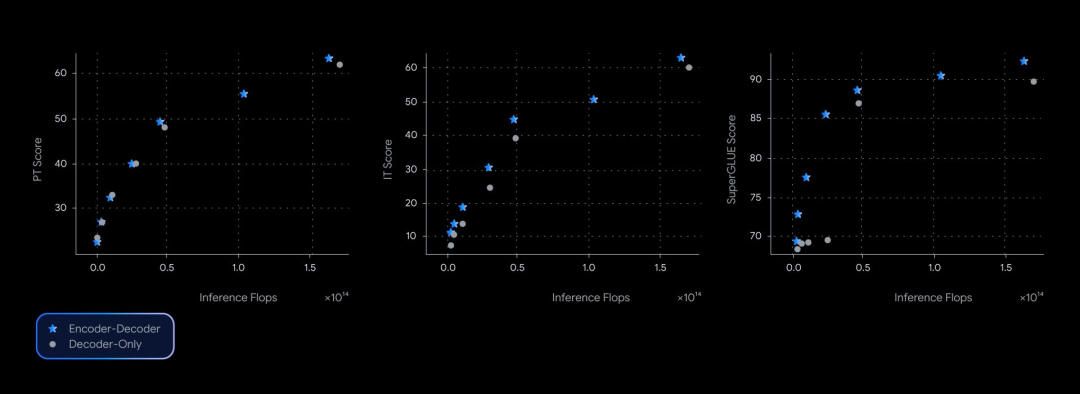
In conclusion, Google’s release of 32 T5Gemma models signifies a potential renaissance for encoder-decoder architectures, demonstrating their competitiveness and versatility in the era dominated by decoder-only models.
For more details, see the official blog: https://developers.googleblog.com/en/t5gemma/
Additional references: https://x.com/googleaidevs/status/1942977474339496208, https://research.google/blog/medgemma-our-most-capable-open-models-for-health-ai-development/