Only 27 Million Parameters: This Reasoning Model Surpasses DeepSeek and Claude}
A novel hierarchical reasoning model with just 27 million parameters achieves superior performance over DeepSeek and Claude, demonstrating efficient, interpretable reasoning with minimal data.

Reasoning like humans.
Is it time for a fundamental change in large model architectures?
Current large language models (LLMs) mainly use Chain-of-Thought (CoT) techniques for complex reasoning tasks, but these face issues like task decomposition complexity, high data requirements, and high latency.
Inspired by the layered and multi-timescale processing mechanisms of the human brain, researchers from Sapient Intelligence proposed a Hierarchical Reasoning Model (HRM), a new cyclic architecture capable of deep reasoning while maintaining training stability and efficiency.
Specifically, HRM employs two interdependent cyclic modules that perform sequential reasoning in a single forward pass without explicit supervision of intermediate steps: a high-level module for slow, abstract planning, and a low-level module for fast, detailed computation. HRM contains only 27 million parameters and uses just 1,000 training samples, yet achieves outstanding performance on complex reasoning tasks.
This model can operate without pretraining or CoT data, but still performs near-perfectly on challenging tasks like complex Sudoku puzzles and optimal pathfinding in large mazes. Additionally, on the Abstract and Reasoning Corpus (ARC), HRM outperforms larger models with shorter context windows. ARC is a key benchmark for general AI capabilities.
Thus, HRM has the potential to drive revolutionary progress in general-purpose computation.

- Paper: Hierarchical Reasoning Model
- Link: https://arxiv.org/abs/2506.21734
As shown in the diagrams below: the left illustrates HRM inspired by the brain’s layered processing and multi-timescale mechanisms, featuring two cyclic networks operating at different timescales to collaboratively solve tasks. The right shows HRM (with only about 1,000 training samples) surpassing state-of-the-art CoT models on inductive benchmarks (ARC-AGI) and challenging symbolic puzzles (Sudoku-Extreme, Maze-Hard). HRM is initialized randomly, operates without explicit reasoning chains, and completes tasks directly from input.
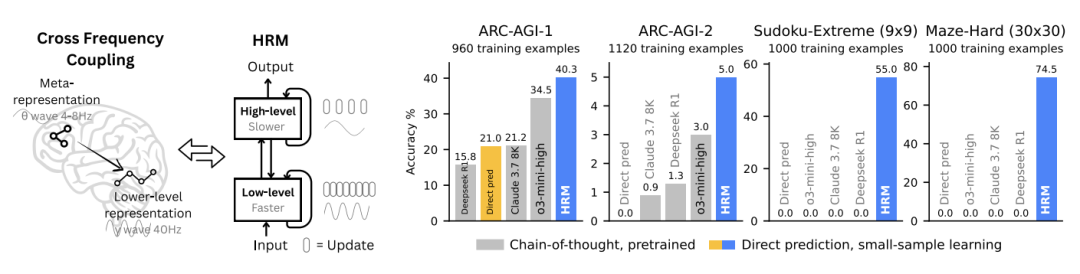
Hierarchical Reasoning Model
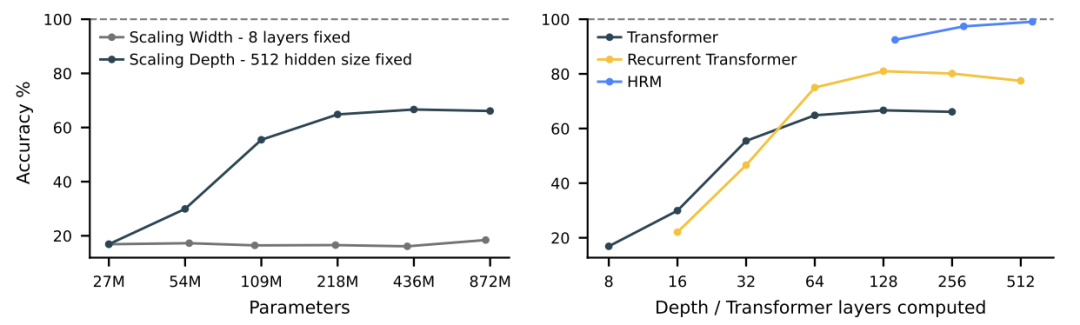
The necessity of depth in complex reasoning is illustrated below.
The left diagram shows that increasing Transformer width does not improve performance on Sudoku-Extreme Full, which requires extensive tree search and backtracking; increasing depth is crucial. The right diagram indicates that standard architectures are saturated and cannot benefit from added depth. HRM overcomes this fundamental limitation, leveraging its depth to achieve near-perfect accuracy.
HRM’s core design draws inspiration from the brain: layered structure + multi-timescale processing. Specifically:
- Layered processing: The brain processes information through a hierarchical cortical structure. Higher regions (like the prefrontal cortex) integrate information over longer timescales to form abstract representations, while lower regions (sensory cortex) handle immediate, perceptual data.
- Timescale separation: Neural activities across these layers exhibit different intrinsic rhythms, represented by specific oscillation patterns. This separation allows higher regions to guide faster computations in lower regions effectively, avoiding issues like vanishing gradients in backpropagation through time (BPTT).
HRM consists of four trainable components: input network f_I(・; θ_I), low-level cycle module f_L(・; θ_L), high-level cycle module f_H(・; θ_H), and output network f_O(・; θ_O). The input vector x is mapped to output y′. First, x is projected into a representation:
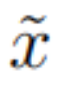
Then, the module’s final state at each cycle m (from 1 to M) encodes the hidden state, including high-level and low-level components. The pseudo-code for depth supervision training is shown in Figure 4.
Inspired by the brain’s dynamic switching between System 1 (fast, automatic) and System 2 (slow, deliberate), the model incorporates an adaptive stopping strategy (ACT) to balance speed and accuracy.
Figure 5 compares two variants of HRM. Results show ACT effectively adjusts computational resources based on task complexity, saving resources while maintaining performance.
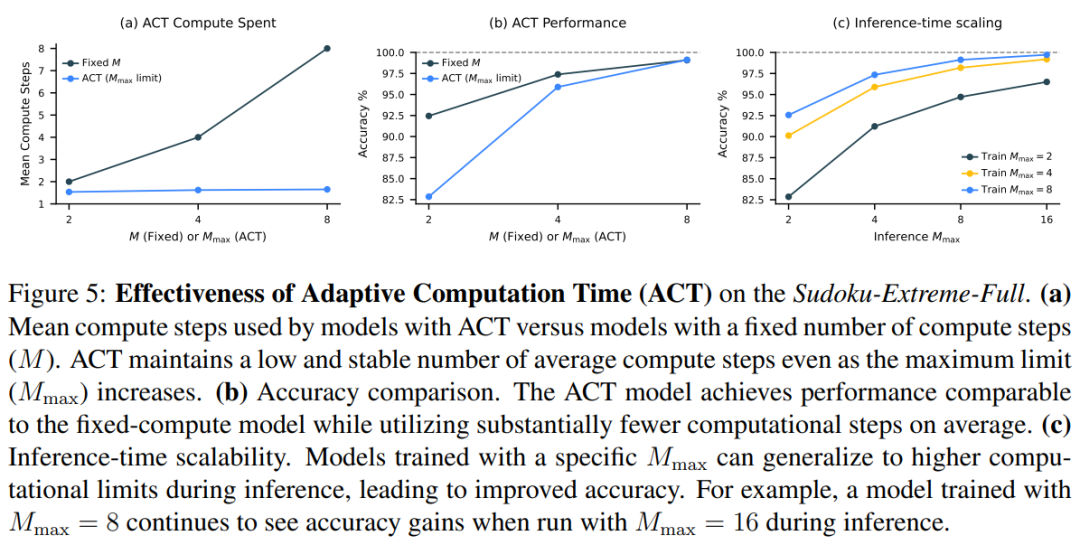
Inference time extension: an effective neural model should dynamically utilize additional resources during reasoning. HRM achieves this by simply increasing the maximum cycle parameter Mmax, without retraining or architecture changes, as shown in Figure 5-(c).
Experiments and Results
The authors tested ARC-AGI, Sudoku, and maze benchmarks, with results shown in Figure 1:
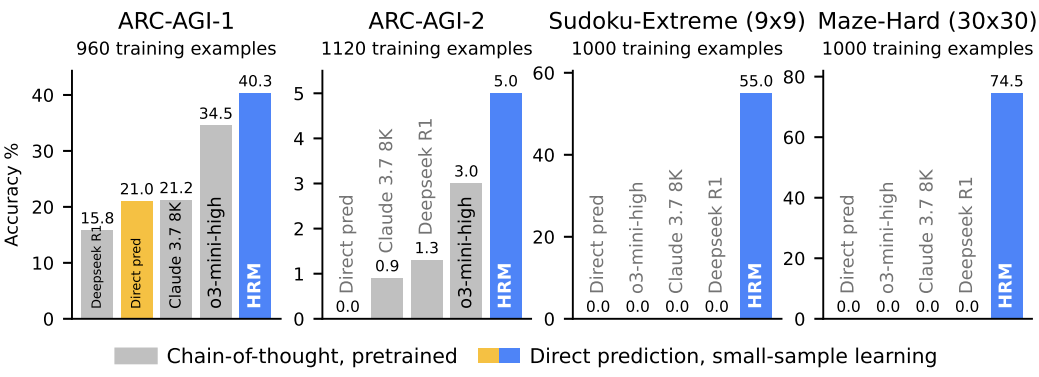
HRM performs excellently on complex reasoning tasks, but raises an intriguing question: what underlying algorithms does HRM implement? Visualizations of HRM’s reasoning process show that, in maze tasks, it initially explores multiple paths, then prunes blocked or inefficient ones, builds a preliminary solution outline, and iterates. In Sudoku, it resembles depth-first search, exploring solutions and backtracking upon dead ends. For ARC tasks, it iteratively adjusts the grid until a solution is found, following a more consistent, hill-climbing approach. Unlike traditional models requiring frequent backtracking, HRM’s solutions are more progressive, akin to mountain climbing.
Furthermore, HRM can adapt to different reasoning strategies and may select effective approaches for specific tasks. Further research is needed to fully understand these strategies.
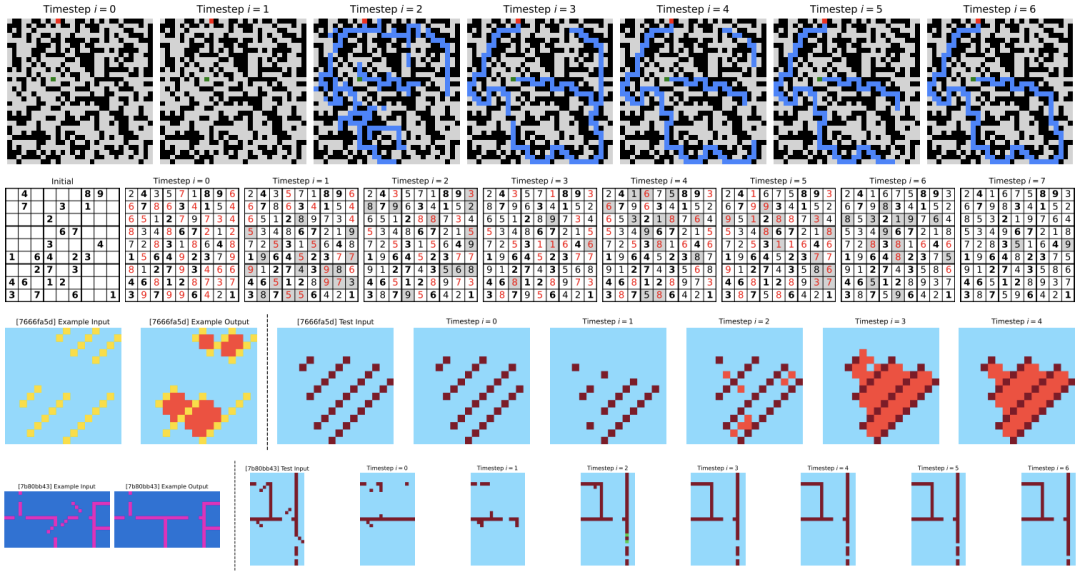
Visualization of HRM’s intermediate predictions on benchmark tasks. Top: MazeHard—blue cells indicate predicted paths. Middle: Sudoku-Extreme—bold cells are initial clues; red cells violate Sudoku constraints; gray shading shows changes over steps. Bottom: ARC-AGI-2—input-output pairs and intermediate steps.
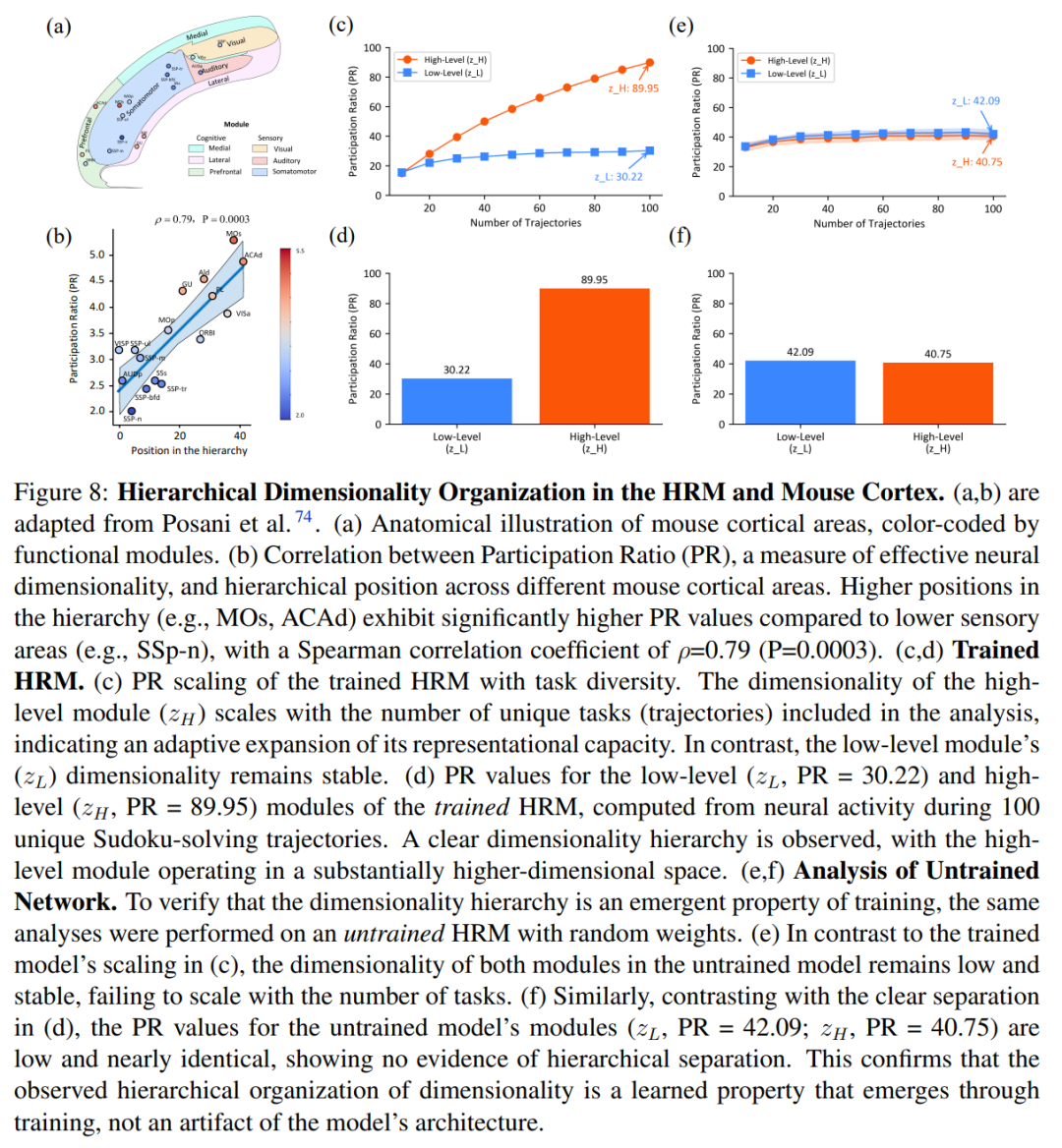
Additionally, a comparison of HRM’s hierarchical organization with the cortical layers of a mouse brain shows that, like the brain, HRM exhibits a layered structure with increasing participation ratio (PR) from sensory to association areas, supporting the link between dimensionality and complexity (Figure 8a, b).
Figures 8(e,f) reveal that untrained models lack hierarchical differentiation, with low PR values across modules. This indicates that the hierarchical structure emerges naturally as models learn complex reasoning, not as an inherent architectural feature.
Further discussion suggests that HRM’s Turing completeness is similar to early neural reasoning algorithms (including Universal Transformer). Given sufficient memory and time, HRM can perform general computation, effectively overcoming the computational limits of standard Transformers and approaching practical Turing completeness.
Besides CoT fine-tuning, reinforcement learning (RL) has been widely used recently. However, recent evidence indicates RL mainly unlocks existing CoT capabilities rather than exploring new reasoning mechanisms. RL training for CoT is known for instability and low data efficiency, requiring extensive exploration and reward design. In contrast, HRM learns from dense gradient-based feedback rather than sparse rewards, operating naturally in continuous space, which is biologically plausible and avoids inefficient resource allocation per token.
For more details, please refer to the original paper.