Mobile AGI Assistant: Progress, Benchmark, and System for Long-Horizon Tasks Released}
A new benchmark and scheduling system for mobile multimodal agents tackling complex long-horizon tasks have been released, advancing towards practical mobile AGI assistants.


Author Guo Yuan, a third-year undergraduate at Shanghai Jiao Tong University’s Department of Computer Science, specializing in autonomous agents and agent safety. This work was completed jointly with Shanghai Jiao Tong University and LanZhou Technology.

- Paper Title: Atomic-to-Compositional Generalization for Mobile Agents with A New Benchmark and Scheduling System
- Project Homepage: https://ui-nexus.github.io/
- Paper Link: https://arxiv.org/abs/2506.08972
From Atomic Tasks to System-Level On-Device Intelligence
Multimodal large models (MLLM) driven OS agents show promising results in single-screen actions (e.g., ScreenSpot) and short-chain tasks (e.g., AndroidControl), marking initial maturity in on-device automation.
However, real-world user needs often involve complex, long-horizon tasks, such as comparing prices across platforms or browsing and summarizing news, requiring multi-application operations, cross-source information collection, and integrated reasoning. Transitioning from simple ordered tasks to complex, unordered tasks is essential for evolving from individual models to AI operating systems. Current training methods improve atomic task performance but face new challenges like long-chain management, information transfer, and combined reasoning.
Researchers focus on system-level studies of mobile GUI agents. Experiments reveal existing mobile GUI agents struggle with complex long-horizon tasks, showing significant generalization gaps from atomic to composite tasks.
To address this, they propose:
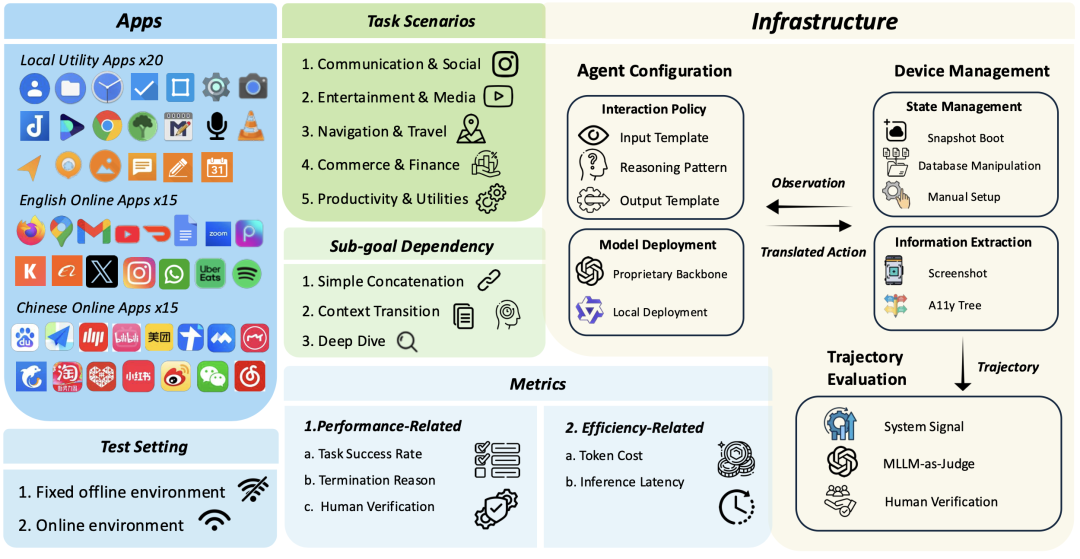
- 1. Dynamic Evaluation Benchmark UI-Nexus: A controllable platform covering complex, transfer, and deep analysis tasks, with 50 apps (20 local, 30 online), 100 instruction templates, and an average optimal step count of 14.05.
- 2. Multi-Agent Task Scheduling System AGENT-NEXUS: A lightweight framework supporting instruction dispatch, information transfer, and process management, enabling efficient multi-agent collaboration without modifying underlying models.
This work provides a challenging testing platform and development environment for mobile agents handling complex tasks, laying the groundwork for future AI-native operating systems.
Current Capabilities and Bottlenecks of Mobile Agents in Long-Horizon Tasks
With continuous improvements in foundational models and training strategies like environment perception, grounding, static trajectory fine-tuning, and reinforcement learning, multimodal device control models are increasingly capable of end-to-end automation, including network searches.
However, real user instructions often involve long-horizon and dependent tasks. The paper classifies common composite task types into:
- Independent Concatenation: Sequential atomic sub-tasks with no dependencies, e.g., “Enable Do Not Disturb for 8 hours and set an alarm for 7:00 AM.”
- Context Transition: Tasks that inherit and utilize intermediate results or states, e.g., search weather and send a message based on results.
- Deep Dive: A special case of context transition involving complex reasoning and information processing, e.g., summarizing news articles while navigating multiple pages.

Based on these task classifications, researchers built representative test tasks on popular apps, testing mainstream GUI agents like OS-Atlas, UI-TARS, Mobile-Agent series, and M3A. Results show significant performance gaps in complex long-horizon tasks.
Analysis of failure cases indicates issues such as:
- Attention Distraction: Overload of context when given complex instructions, leading to missed sub-tasks.
- Information Transfer Failure: Lack of effective info management causes errors in transfer tasks.
- Progress Management Confusion: Repeatedly jumping between unfinished sub-tasks.
UI-NEXUS: A Comprehensive Benchmark for Mobile Agent Complex Tasks
To provide a scientific testing platform, researchers propose UI-NEXUS, an interactive benchmark covering 50 apps, 100 tasks, and three dependency types, with detailed metrics like success rate, token cost, and latency.
Experiments with five representative mobile agents based on GUI operations show that all face challenges in complex tasks, with success rates below 50%. Notably, Agentic Workflow significantly improves robustness over simple models, but at high inference costs.
Agent-NEXUS’s hierarchical scheduling reduces failure rates from 11% to 60%, with only about 8% increase in inference overhead, demonstrating effective management of complex tasks.
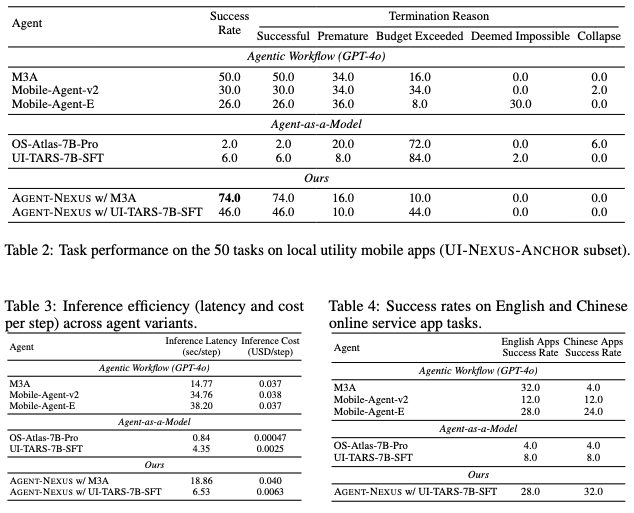
Further analysis shows that:
- Online services with dynamic info and complex UI are more challenging.
- GPT-4o-based workflows excel in complex reasoning but are costly and limited in GUI-specific tasks.
- Open-source models like Agent-as-a-Model are faster and more efficient but struggle with complex logical dependencies.
Memory mechanisms are crucial for long-horizon tasks. Current approaches include:
- No memory: e.g., OS-Atlas-Pro, which predicts next actions based solely on history.
- Partial memory: e.g., UI-TARS, which uses recent screens but limited in cross-source info integration.
- Active memory: e.g., Mobile-Agent series, which actively decide what to store at each step.
Active memory improves performance but adds computational overhead. Agent-NEXUS explicitly manages info collection and processing in high-level scheduling, balancing cost and capability.
Future Outlook: Towards Next-Generation AI Operating Systems
This work not only explores the urgent need to handle complex long-horizon tasks but also envisions the prototype of future AI operating systems.
In the future, we aim to develop systems that can coordinate and manage complex tasks efficiently, transforming mobile devices into intelligent personal assistants with OS-level capabilities, opening new horizons for human-AI collaboration.