Meta Spends $200 Million on Pang Ruoming, Showcases Latest Paper from Apple}
Pang Ruoming, former Apple AI engineer and now a new Meta executive, published his latest research paper, highlighting advancements in large-scale model training and infrastructure.


This may be the last paper Pang Ruoming contributed to Apple. Pang Ruoming, head of Apple's foundational model team and distinguished engineer, is about to join Meta's newly formed super-intelligence team. He graduated from Shanghai Jiao Tong University and worked at Google for 15 years before joining Apple. According to Bloomberg, Meta offered a staggering $200 million to recruit him.

Although about to start a new chapter, Pang Ruoming is still working hard for Apple. On July 9, he promoted his latest research on X, titled AXLearn: Modular Large Model Training on Heterogeneous Infrastructure. This research forms the core codebase for building Apple Foundation models.
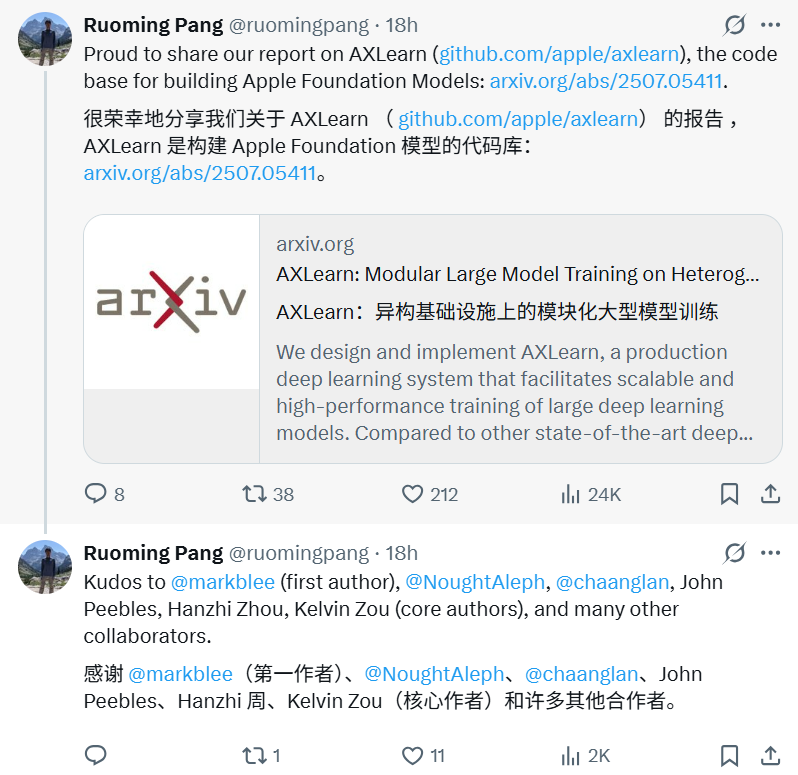
Specifically, the paper designs and implements AXLearn, a production-level system for large-scale deep learning model training, characterized by high scalability and performance. Compared to other advanced systems, AXLearn’s advantages include high modularity and comprehensive support for heterogeneous hardware infrastructure.
AXLearn’s software components follow strict encapsulation principles, allowing flexible component combination for rapid model development and experimentation in diverse computing environments. It also introduces a new metric called LoC-complexity to measure modularity, showing that AXLearn maintains constant complexity as it scales, unlike other systems that grow linearly or quadratically.
For example, integrating features like Rotary Position Embeddings (RoPE) into hundreds of AXLearn modules requires only about 10 lines of code, whereas other systems might need hundreds of lines. AXLearn also maintains competitive training performance.

- Paper link: https://arxiv.org/pdf/2507.05411
- Open source: https://github.com/apple/axlearn
- Paper title: AXLearn: Modular Large Model Training on Heterogeneous Infrastructure
Introduction to AXLearn
Today, chatbots like ChatGPT and Gemini are driven by large models, prioritizing performance and scalability. Apple, as a leading tech giant, has integrated many AI models into its products for billions of users.
Beyond training performance, Apple emphasizes two additional requirements: empowering model engineers with minimal coding and supporting heterogeneous hardware like GPUs, TPUs, and AWS Trainium.
AXLearn was developed to meet these needs. Its core design enforces strict encapsulation, and it supports features like RoPE and MoE, demonstrating consistent code complexity and high efficiency.
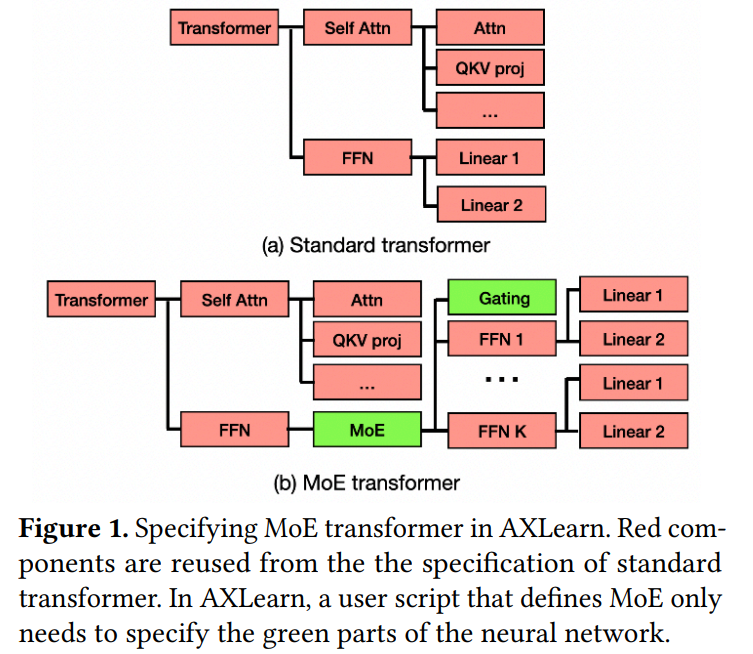
Figure 2 illustrates AXLearn’s architecture and workflow, which includes two key components: (1) AXLearn Composer and (2) AXLearn Runtime. Users define training configurations using built-in and third-party layers, which are then compiled into full JAX programs.
This process involves selecting grid shapes, applying sharding annotations, tuning XLA options, choosing attention kernels, and applying recomputation strategies, all crucial for efficient training. The JAX program is then compiled by XLA into hardware-specific code, scheduled on distributed hardware like Kubernetes, and managed by AXLearn’s runtime, which also offers checkpointing, monitoring, and fault tolerance.
Experimental Evaluation
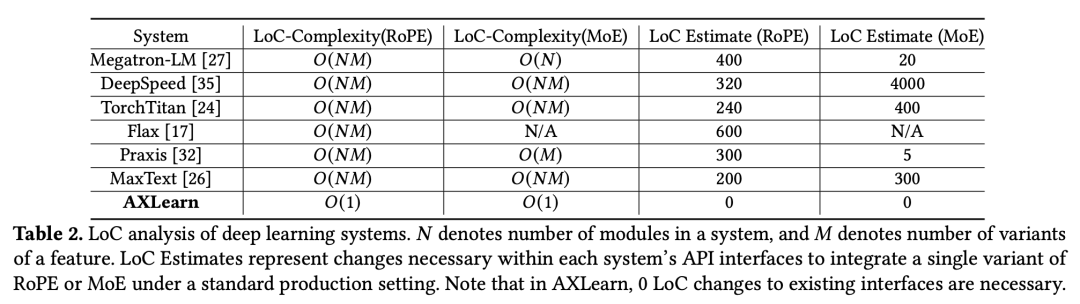
The table below summarizes code complexity (LoC) across different systems. AXLearn’s modules, including RoPE and MoE, are strictly encapsulated, with integration code often just 10 lines, maintaining constant complexity even as modules grow.
AXLearn’s performance on heterogeneous hardware is comparable to leading systems like PyTorch FSDP, Megatron-LM, and MaxText. It supports over 10,000 experiments simultaneously across diverse hardware clusters.
Weak scaling experiments show near-linear scalability, and inference tests on TPU show significant latency and throughput advantages over vLLM, with 500x speedup in latency and 2.8x faster inference for 7B models.
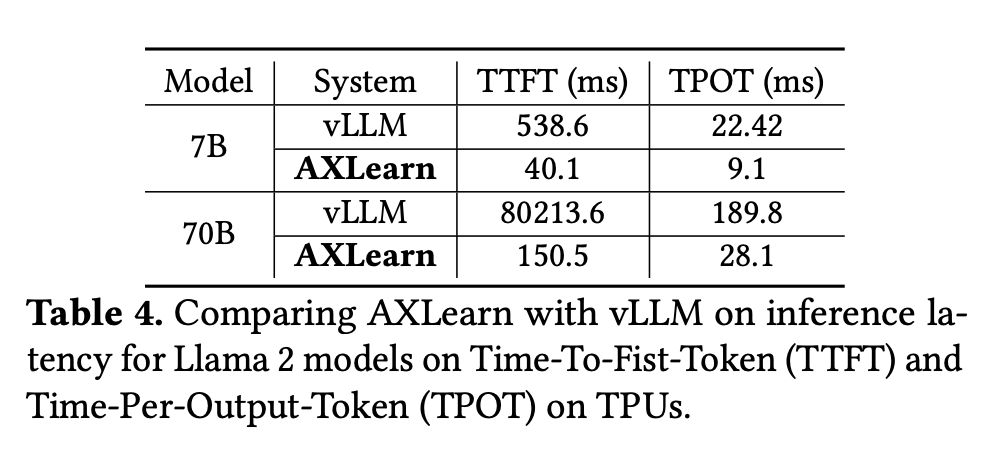
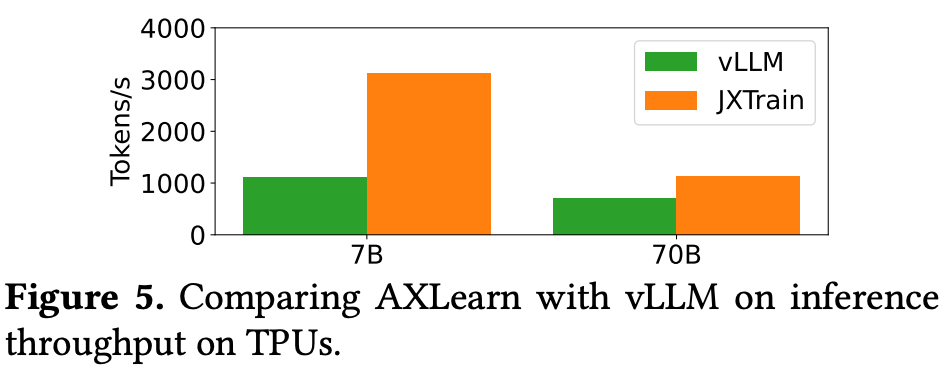
Real-world Deployment Experience
AXLearn has evolved from a tool for a few developers training million-parameter models to a large platform supporting hundreds of developers training models with billions to trillions of parameters. It can support over 10,000 experiments in parallel and is deployed on various hardware clusters.
Models trained with AXLearn are widely used in products serving over a billion users, including intelligent assistants, multimodal understanding and generation, and code intelligence.
For more details, please refer to the original paper.