Meta Continues Expansion: Poaches 2 OpenAI Multimodal AI Researchers and Acquires Voice Startup PlayAI}
Meta CEO Mark Zuckerberg continues aggressive talent acquisition, poaching OpenAI researchers and acquiring voice AI startup PlayAI, intensifying competition in AI development.


Author team introduction: The first author is Zhou Xin, and the co-first author is Liang Dingkang, both PhD students at Huazhong University of Science and Technology, supervised by Professor Bai Xiang. Collaborators include researchers from Huazhong University of Science and Technology (Chen Kaijin, Feng Tianrui, Lin Hongkai), Megvii Technology (Chen Xiwu, Ding Yikang, Tan Feiyang), and Assistant Professor Zhao Hengshuang from the University of Hong Kong.
On HunyuanVideo, EasyCache maintains the appearance consistency with the original video in complex scenes while significantly accelerating the process.
1. Background and Motivation
With the widespread application of diffusion models (Diffusion Models) and diffusion Transformers (DiT) in video generation, the quality and coherence of AI-synthesized videos have improved dramatically. Large models like OpenAI Sora, HunyuanVideo, Wan2.1 can generate structured, detailed, and highly coherent long videos, revolutionizing digital content creation, virtual worlds, and multimedia entertainment.
However, slow inference and high computational costs are increasingly problematic. For example, generating a 5-second, 720P video with HunyuanVideo takes about 2 hours on a single H20 GPU. This resource-intensive process limits real-time interaction, mobile deployment, and large-scale production.
The core reason is that diffusion models require multiple denoising iterations, each involving full neural network inference, leading to redundant computations. How to significantly improve inference efficiency without sacrificing video quality is a critical challenge.

- Paper title: Less is Enough: Training-Free Video Diffusion Acceleration via Runtime-Adaptive Caching
- Paper link: https://arxiv.org/abs/2507.02860
- Code (open source): https://github.com/H-EmbodVis/EasyCache
- Project homepage: https://h-embodvis.github.io/EasyCache/
2. Method Innovation: Design and Principles of EasyCache
This paper proposes EasyCache, a training-free, model-structure-agnostic, offline-statistics-free inference acceleration framework. Its core idea is to dynamically detect the "stability period" during inference and reuse previous computations to reduce redundant steps.
2.1 Transformation rate in the diffusion process
The diffusion process can be viewed as "gradual denoising": each step predicts noise and updates the latent, gradually restoring clear video content. Treating all DiT blocks in a step as a function, the "directional derivative" approximation of a step’s change rate is considered.
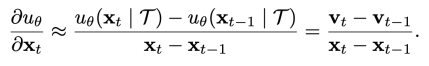
To simplify analysis, the mean and norm of this rate are used to define the "transformation rate".
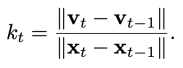
Analysis of internal features of diffusion transformers reveals:
- Early denoising stages involve rapid output changes, requiring full inference to capture global structure;
- Later stages exhibit near-linear behavior with stable transformation rates, mainly fine-tuning details.
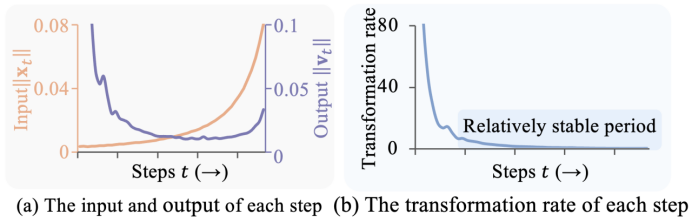
This "stability" means many steps’ outputs can be approximated by previous results, skipping redundant computations.
2.2 Adaptive caching mechanism of EasyCache
The implementation process of EasyCache is as follows:
(1) Transformation rate measurement
Define the "transformation rate" for each step, measuring the sensitivity of output to input changes. Surprisingly, despite large variations in input-output at the timestep level, the rate remains relatively stable in later denoising stages.

(2) Adaptive criterion and cache reuse
- Set an accumulated error threshold, dynamically summing output change rates (error metric Et). When Et is below a threshold, reuse previous inference results; otherwise, recompute and refresh cache.
- Initial R steps perform full inference to ensure structural information is retained.
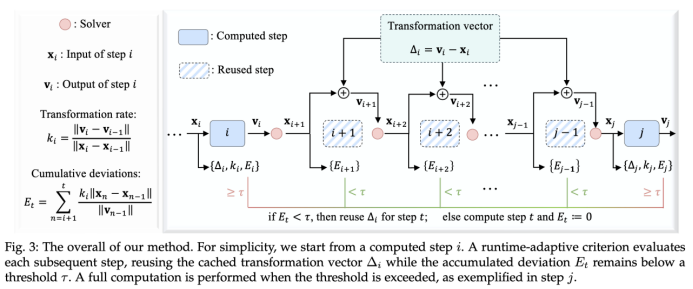
(3) No training or model modification needed
EasyCache works entirely during inference, requiring no retraining or structural changes, making it plug-and-play.
3. Experimental Results and Visual Analysis
The paper conducted systematic experiments on popular video models like OpenSora, Wan2.1, and HunyuanVideo, examining the trade-off between inference speed and quality.
3.1 Quantitative Results
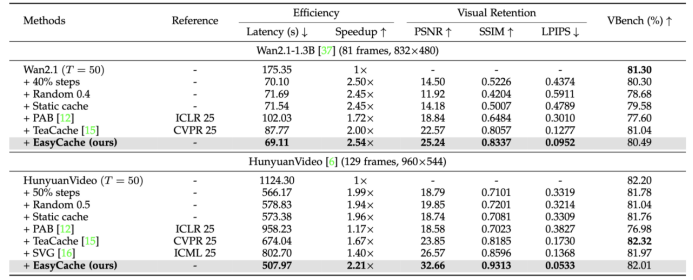
- On HunyuanVideo, EasyCache achieves 2.2x speedup, 36% PSNR improvement, 14% SSIM increase, and significant LPIPS reduction, with almost no quality loss. On Wan2.1, it exceeds 2x acceleration.
- For image generation tasks (e.g., FLUX.1-dev), it provides 4.6x speedup and improves FID scores.
- Combining EasyCache with sparse attention techniques like SVG yields an average 3.3x acceleration, reducing total inference time from 2 hours to 33 minutes.
3.2 Visual Comparison
The paper shows comparisons of generated video frames:
- Methods like static caching and TeaCache cause detail, structure, and clarity loss;
- EasyCache produces videos nearly identical to the original, with excellent detail preservation and no obvious blurring or structural errors. More visualizations are available at: https://h-embodvis.github.io/EasyCache/
In Wan2.1-14B, EasyCache successfully preserves text.
EasyCache can further improve acceleration to over three times on SVG-based methods.
4. Summary and Future Outlook
EasyCache provides a simple, efficient, training-free paradigm for inference acceleration of diffusion models. It leverages intrinsic diffusion process patterns to achieve significant speedups with minimal quality loss, paving the way for practical deployment. Future work aims to approach real-time video generation as models and acceleration techniques continue to improve.