Live Preview: Huawei Pangu's First Open-Source Large Model Unveiled!}
Huawei releases Pangu's first open-source large models, Pangu Embedded and Pangu Pro MoE, showcasing advanced AI capabilities with high efficiency, and hosts a live technical sharing event.


This Monday, a major new player in the open-source community emerged—Huawei Pangu.
They announced the open-sourcing of two large models: the 7 billion parameter dense model Pangu Embedded and the 72 billion parameter mixture-of-experts model Pangu Pro MoE. They also released the inference technology based on Ascend chips.
Overall, these models are formidable: on the SuperCLUE May leaderboard, Pangu Pro MoE ranks jointly first among models with less than 100 billion parameters. In agent tasks, it rivals DeepSeek-R1 with 671 billion parameters, and in text understanding and generation, it leads among open-source models. Pangu Embedded also excels in disciplines, coding, math, and dialogue capabilities, outperforming similar-scale models.
They incorporate cutting-edge techniques for efficient training and inference, such as the MoGE algorithm, adaptive fast-slow thinking, and full-stack high-performance inference system optimization. These are crucial in industry applications where efficiency is paramount, and are key competitive factors in the current large model race.
Previously, AI research media have introduced some of these techniques (see further reading at the end). During the upcoming event on July 4th, Huawei Pangu’s research team will share detailed technical insights and live demonstrations of Pangu Pro MoE, helping both academia and industry gain valuable knowledge.
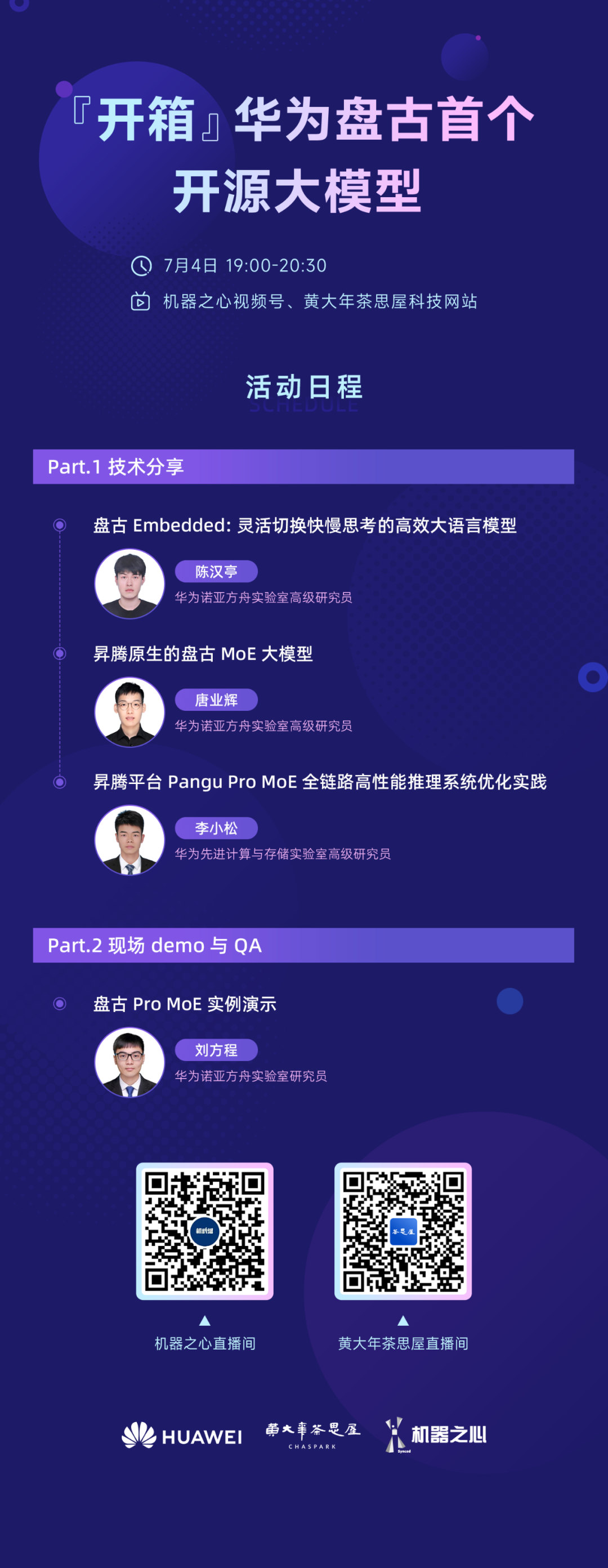
Topic 1: Pangu Embedded — Efficient Large Language Model with Fast and Slow Thinking
Overview
This research introduces Pangu Embedded, a flexible and efficient reasoning LLM trained on Ascend NPUs, capable of alternating between rapid and deep thinking modes.
To address high computational costs and latency issues in existing reasoning LLMs, the team developed a multi-dimensional optimization framework, integrating three core techniques: iterative distillation fine-tuning, a delayed synchronization scheduling framework combining SSP and distributed priority queues, and a dual-system fast-slow thinking architecture with manual/automatic mode switching. Experiments show Pangu Embedded reduces inference latency significantly while maintaining high reasoning accuracy, especially suitable for resource-constrained mobile devices. This work pioneers a unified approach to enhance edge-side LLM inference capabilities.
Speakers
Chen Hanting, Senior Researcher at Huawei Noah’s Ark Lab, PhD from Peking University, focuses on LLM architecture, compression, acceleration, and reasoning. He has published over 50 papers, cited over 8,000 times, and served as session chair at top conferences like NeurIPS. He was runner-up at CVPR24 best student paper and listed among Stanford’s top 2% global scholars.

Topic 2: Ascend-native Pangu MoE — Full-Stack High-Performance Inference Optimization
Overview
With the evolution of scaling laws, MoE architectures are favored for their dynamic sparsity, enabling larger, more effective models at the same compute scale. However, deployment challenges like high memory usage, low inference efficiency, and unbalanced routing hinder practical use. This research proposes the Pangu Pro MoE, a 72B parameter Ascend-native MoE model, achieving top-tier performance in SuperCLUE’s 100-billion-parameter category. It introduces MoGE, a novel routing architecture ensuring balanced expert distribution across devices, and employs system-level optimizations like hybrid parallelism, operator fusion, quantization, and inference system tuning on Ascend 910 and 310 chips, greatly boosting inference efficiency. Trained on over 4,000 Ascend NPUs, the model demonstrates superior generalization in knowledge, math, and reasoning tasks, with detailed technical report available at https://arxiv.org/pdf/2505.21411.
Speakers
Tang Yehui, Senior Researcher at Huawei Noah’s Ark Lab, specializes in deep learning and large models, leading training of Pangu models including Pro MoE and Ultra MoE. He has published over 50 papers, cited over 8,000 times, and served as area chair at NeurIPS and ICML.

Topic 3: Full-Stack Optimization of Pangu Pro MoE on Ascend Platform
Overview
As scaling laws evolve, MoE models with dynamic sparsity are key to building more capable AI. However, deployment issues like memory overhead and routing imbalance require system-level optimization. This research presents a comprehensive solution, including hierarchical hybrid parallelism, topology-aware communication, multi-stream fusion, and operator fusion techniques, to maximize inference performance on Ascend 910 and 310 chips. These optimizations enable the Pangu Pro MoE to achieve unprecedented inference efficiency, supporting large-scale, high-performance AI applications.
Speakers
Li Xiaosong, Senior Researcher at Huawei, specializes in inference system optimization and AI architecture. He has published over 10 papers in top conferences and journals, contributing to the high-performance deployment of large models.

Topic 4: Pangu Pro MoE Live Demonstration
Overview
Focusing on tasks like general Q&A, complex reasoning, and financial scenarios, the live demo will showcase Pangu’s capabilities and provide in-depth analysis of its features.
Speakers
Fang Cheng, Researcher at Huawei Noah’s Ark Lab, with expertise in pretraining and inference acceleration of language models. He has published extensively in ICML, NeurIPS, and won the CVPR2021 ImageNet adversarial attack challenge.

Additional Reading: