Is the Era Without Tokenizers Coming? Mamba Author Releases Disruptive Paper Challenging Transformers}
A new hierarchical model called H-Net proposes replacing tokenization with dynamic chunking, potentially revolutionizing end-to-end language modeling and reducing reliance on traditional tokenizers.

Tokenization has long been the final obstacle to achieving truly end-to-end language models.
Are we finally free from tokenization?
The answer is: possibilities are endless.
Recently, one of the authors of Mamba, Albert Gu, published a new research paper titled Dynamic Chunking for End-to-End Hierarchical Sequence Modeling. It introduces a hierarchical network called H-Net, which replaces tokenization with a dynamic chunking process within the model, enabling automatic discovery and manipulation of meaningful data units.

"This research indicates that tokenizers are on the way out, and smart byte chunks are taking center stage. Perhaps the era of training without tokenizers is truly coming—endless possibilities," said well-known blogger Rohan Paul on X.

Currently, tokenization remains an indispensable part of language models and other sequential data because it compresses and shortens sequences. However, it has many drawbacks, such as poor interpretability and reduced performance on complex languages (like Chinese, code, DNA sequences).
So far, no end-to-end models without tokenization have surpassed token-based models under comparable computational budgets. Recent research efforts aim to break this tokenization barrier in autoregressive sequence models.
Researchers from CMU, Cartesia AI, and other institutions have proposed new techniques that use dynamic chunking mechanisms for content and context-adaptive segmentation, which can be jointly learned with other model components. Integrating this mechanism into explicit hierarchical networks (H-Net) allows the entire traditional "tokenization–LM–detokenization" pipeline to be replaced by a single end-to-end model.
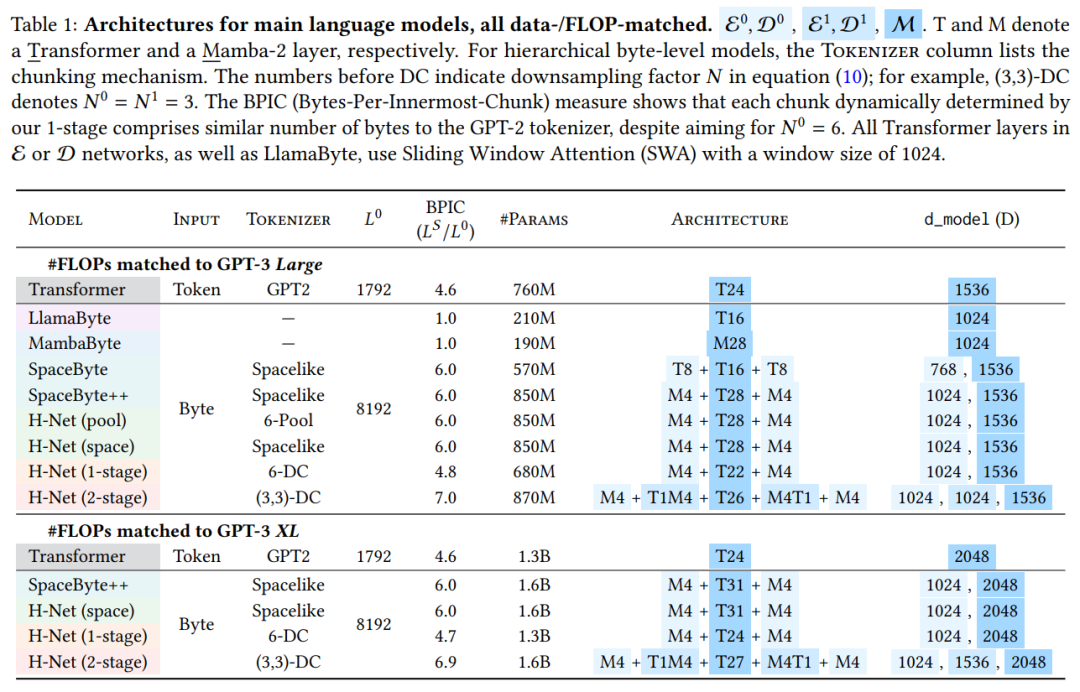
In resource- and data-equivalent conditions, a single-layer byte-level hierarchical H-Net model outperforms strong BPE-based Transformer models. Multi-level hierarchical iteration further improves performance—showing better data scaling effects and rivaling twice the size of token-based Transformers.
In English pretraining, H-Net demonstrates significantly enhanced character-level robustness and can qualitatively learn meaningful, data-dependent chunking strategies without heuristic rules or explicit supervision.
Moreover, in languages and modalities where tokenization heuristics are weak (such as Chinese, code, or DNA sequences), H-Net’s advantages over tokenization processes are even more pronounced, with data efficiency nearly quadrupling the baseline. This highlights the potential of truly end-to-end models to learn and scale from unprocessed data.

Paper link: https://arxiv.org/pdf/2507.07955v1
End-to-End Sequence Modeling Without Tokenization
This paper proposes a hierarchical network (H-Net) that uses recursive, data-dependent dynamic chunking (DC) to compress raw data (see Figure 1). H-Net significantly improves modeling capacity by replacing heuristic segmentation with learned, content-aware, context-dependent segmentation, while maintaining the efficiency of tokenization.
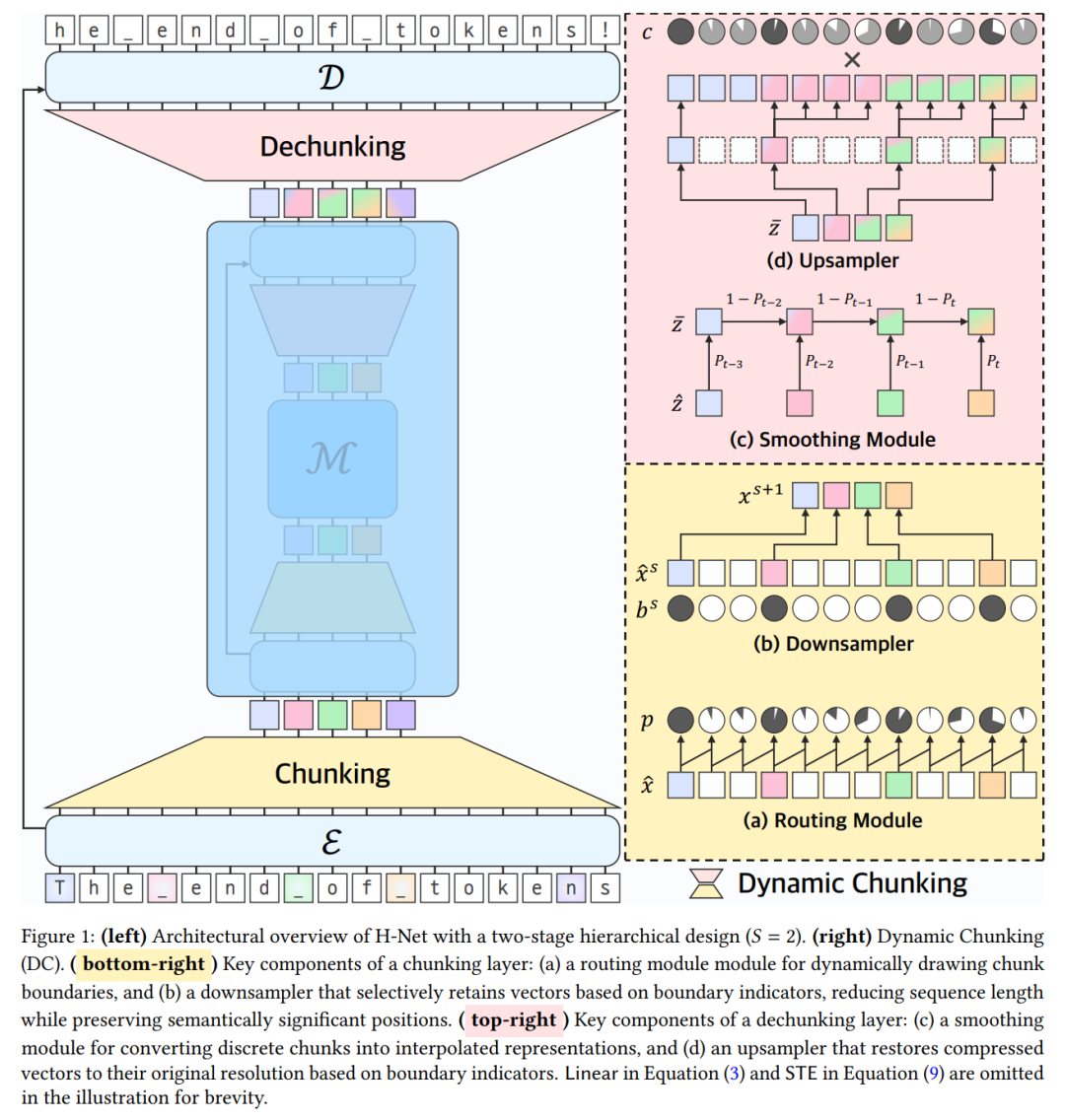
Hierarchical Processing
H-Net employs a layered architecture with three steps:
- Fine processing: a small encoder processes raw data (byte/character level);
- Compression and abstraction: data is downsampled and handled by the main network (the core of the model);
- Restoration: upsampling and decoding to original resolution.
This design creates a natural cognitive hierarchy—outer layers capture fine patterns, inner layers handle abstract concepts. The main network contains most parameters and can adapt to standard architectures like Transformers or SSMs.
Dynamic Chunking
The core of H-Net is the dynamic chunking (DC) mechanism, placed between the main network and encoder/decoder, learning how to segment data via differentiable methods. It includes:
- Routing modules that predict boundaries based on similarity scores;
- Smoothing modules that interpolate boundary representations, improving learning ability.
Combined with a new auxiliary loss and modern gradient-based discrete learning techniques, DC enables fully end-to-end learning of data compression strategies.
Signal Propagation
The paper also introduces techniques to improve training stability and scalability, such as carefully designed projection and normalization layers, and parameter adjustments based on layer dimensions and batch size.
Overall, H-Net learns segmentation strategies jointly optimized with the backbone, dynamically compressing input vectors into meaningful chunks based on context.
H-Net as the First Truly End-to-End, Tokenizer-Free Language Model
By a dynamic chunking stage, byte-level H-Net with over 1 billion parameters achieves perplexity and downstream performance comparable to strong BPE Transformer models. It naturally learns meaningful boundaries without external supervision or heuristics, with chunks typically 4.5–5 bytes.
Experiments and Results
The main language model architectures used include MambaByte, a homogeneous model with pure Mamba-2 layers.
Training curves show validation BPB metrics across training for both large and XL models.
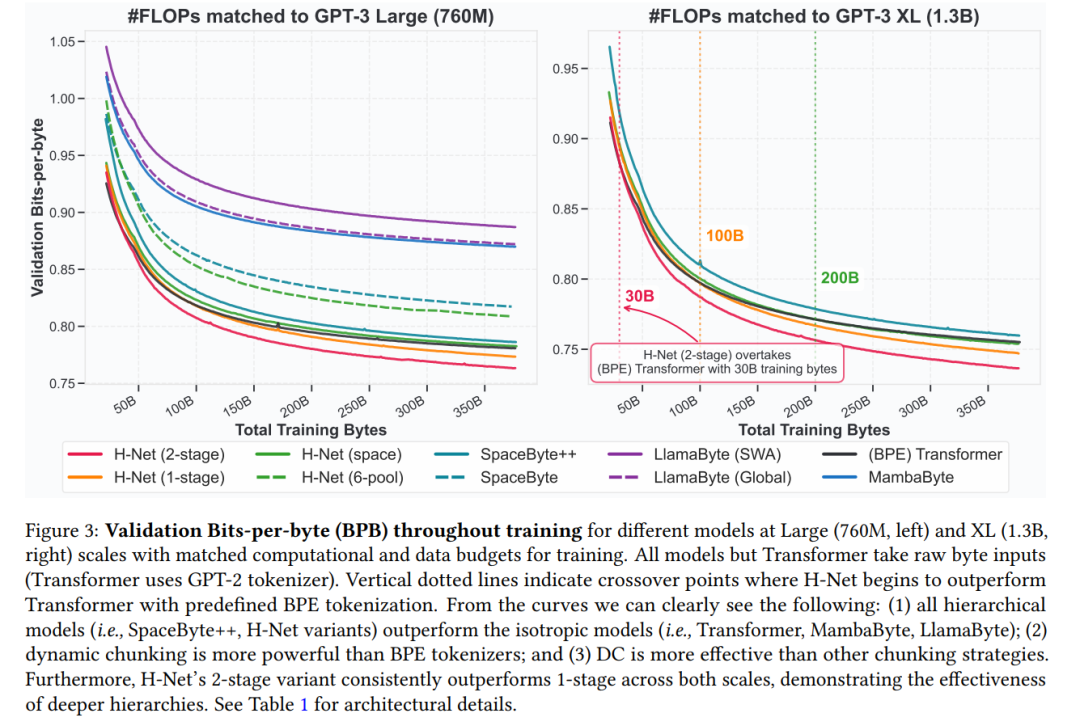
In larger scales, the study finds:
- All homogeneous models perform worse than hierarchical models; MambaByte outperforms LlamaByte;
- SpaceByte is inferior to SpaceByte++, validating the effectiveness of the proposed data-dependent segmentation and hierarchical architecture;
Table 2 shows zero-shot accuracy on various benchmarks, with SpaceByte++, H-Net (space), and H-Net (1-stage) matching or slightly surpassing BPE Transformer at XL scale.
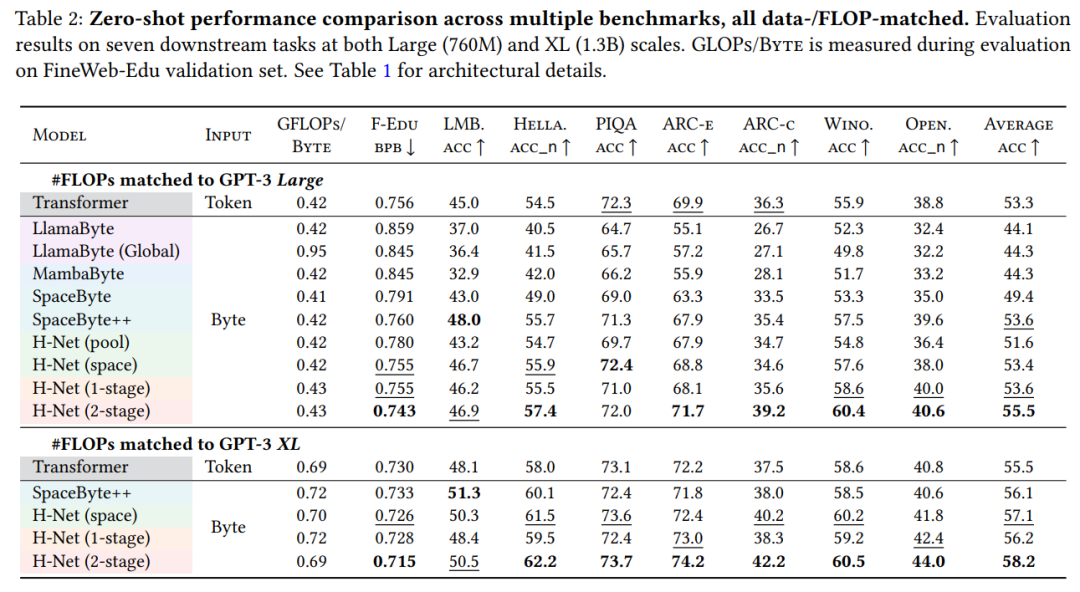
Figure 4 visualizes the dynamic boundary decisions of H-Net (1-stage) and H-Net (2-stage), providing insights into how the models determine segmentation boundaries.
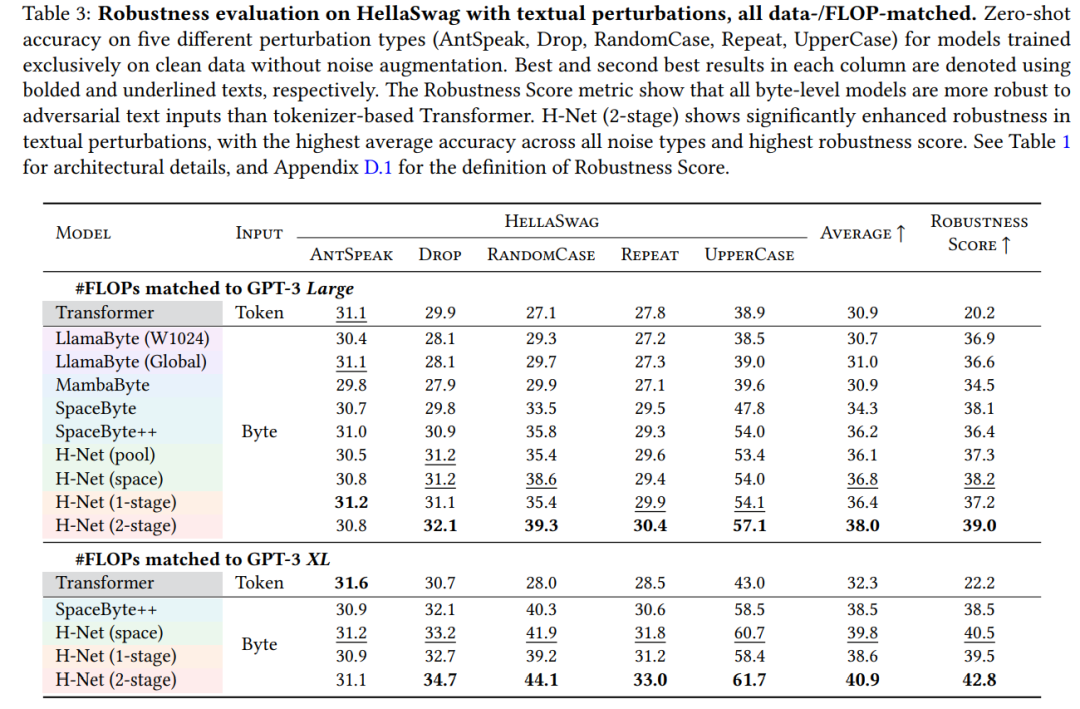
These visualizations reveal how the models decide boundaries, offering interpretability into the segmentation process.
Even with Llama3 tokenizer, H-Net (2-stage) shows better scalability in Chinese and code processing, with lower compression rates during degradation phases (see Table 4). Prior research indicates SSM outperforms Transformers in DNA modeling, confirmed by experiments (Table 5): even replacing the main network with Mamba-2, SSM retains advantages.

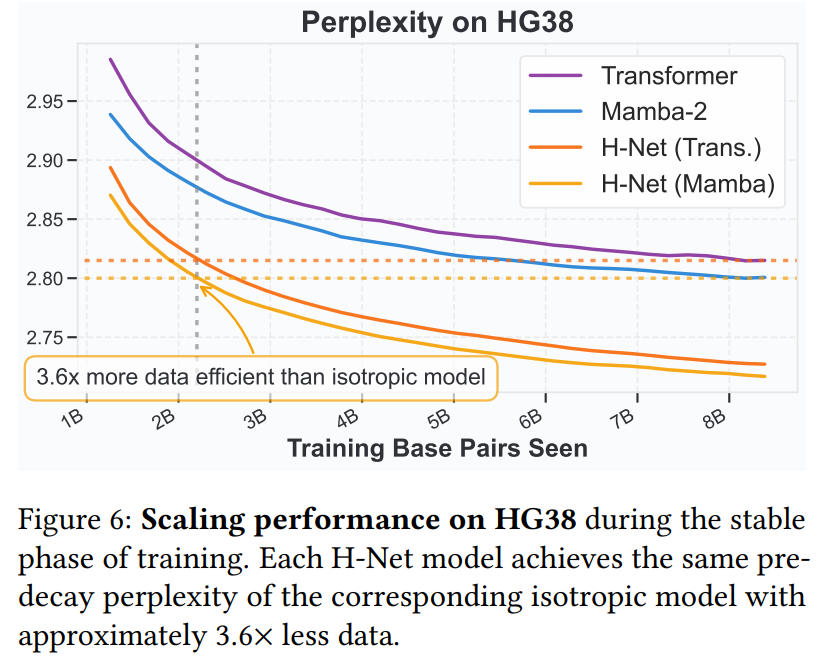
Direct comparison of perplexity curves during stable training phases shows that H-Net models achieve similar performance with only 3.6 times data, validating the effectiveness of the data-dependent segmentation approach across architectures.
Finally, Albert wrote an insightful blog post about the behind-the-scenes of H-Net, which readers can explore at: https://goombalab.github.io/blog/2025/hnet-past/. For more details, refer to the original paper.