Innovative Mid-Training Paradigm Unveils RL Secrets, Llama Finally Matches Qwen!}
A groundbreaking mid-training approach narrows the RL performance gap, enabling Llama to rival Qwen, marking a significant breakthrough in large language model development.


The recent groundbreaking research from Shanghai Chuangzhi Institute and Shanghai Jiao Tong University has attracted widespread attention in AI. The paper explores why foundational language models like Llama and Qwen perform differently during reinforcement learning (RL) training. It introduces an innovative mid-training strategy that transforms Llama into a highly RL-compatible inference backbone, significantly closing the performance gap with Qwen, which is naturally adept at RL. This work provides a crucial scientific foundation and technical pathway for developing next-generation reasoning AI systems.
The paper’s release sparked extensive discussion on social media. Meta AI researcher and soon-to-be assistant professor at UMass Amherst, Wenting Zhao, praised: “Truly impressed by how an academic lab just figured out a lot of mysteries in mid-training to close the RL gap between Llama and Qwen.” Other experts like Carnegie Mellon University Associate Professor Graham Neubig, MIT CSAIL/Databricks researcher Omar Khattab, and AI2 data lead Loca Soldaini also recognized the systematic analysis’s importance. Independent experiments by Pleias AI Lab’s Alexander Doria confirmed that with proper data preprocessing, any model can significantly improve RL performance, demonstrating the method’s universality.
Meanwhile, the MegaMath-Web-Pro-Max dataset, released alongside OctoThinker, has seen a surge in downloads, used by top universities like MIT, EPFL, UW, Columbia, NUS, CMU, Princeton, THU, HKUST, and leading companies such as Apple, Microsoft, TII, Moonshot, DatologyAI, AI2, IBM, Cohere, Tencent, highlighting high academic and industrial interest.

- Paper link: https://arxiv.org/abs/2506.20512
- Code repository: https://github.com/GAIR-NLP/OctoThinker
- Open-source models & data: https://huggingface.co/OctoThinker
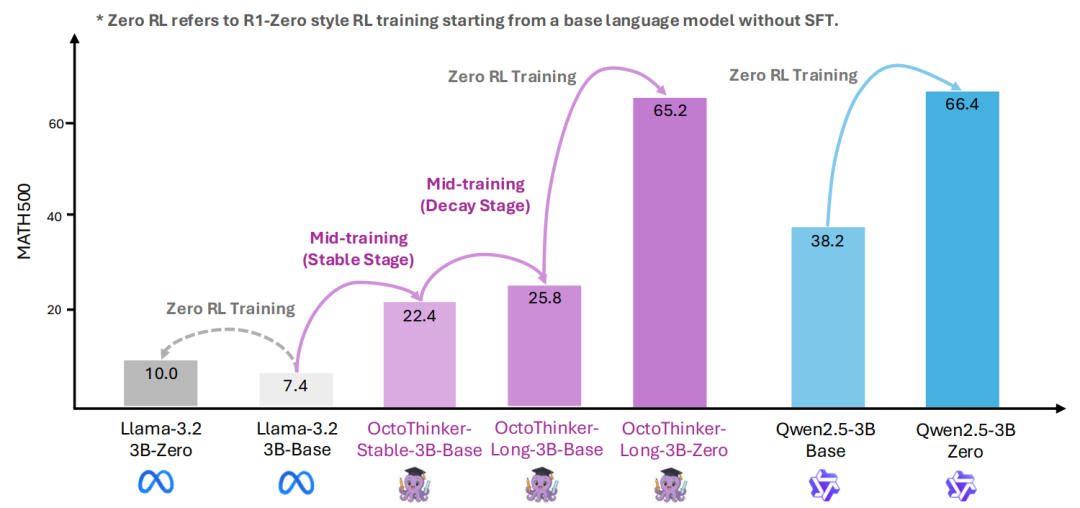
研究团队通过大规模 mid-training 成功将 Llama 模型改造成 highly RL-compatible 的推理基础模型,在数学推理上可以与 Qwen 媲美。
研究背景
引入大规模强化学习(RL)显著提升了语言模型的复杂推理能力,尤其在数学竞赛题解等高难度任务中表现突出。然而,近期研究发现:(i) 只有 Qwen 系列模型表现出“魔法般”的 RL 提升;(ii) 关键“顿悟”时刻主要出现在数学场景;(iii) 不同评测设置存在偏差,影响 RL 成效判断;(iv) RL 在下游任务中表现平平,但高度依赖上游的预训练和中期训练质量^[1]。
同时,团队和其他研究者发现,尽管 Qwen 在 RL 扩展上表现稳健,Llama 经常出现提前给出答案和重复输出,难以获得同等性能提升。这引发了核心科学问题:哪些基础特性决定模型对 RL 扩展的适应性?中期训练是否能作为干预手段,弥合不同模型在 RL 中的表现差距?
为此,团队提交了详尽的技术报告和开源数据方案,推出了基于 Llama的强化性能新系列模型 OctoThinker。
核心问题:为何 RL 训练在 Llama 上频频失效?
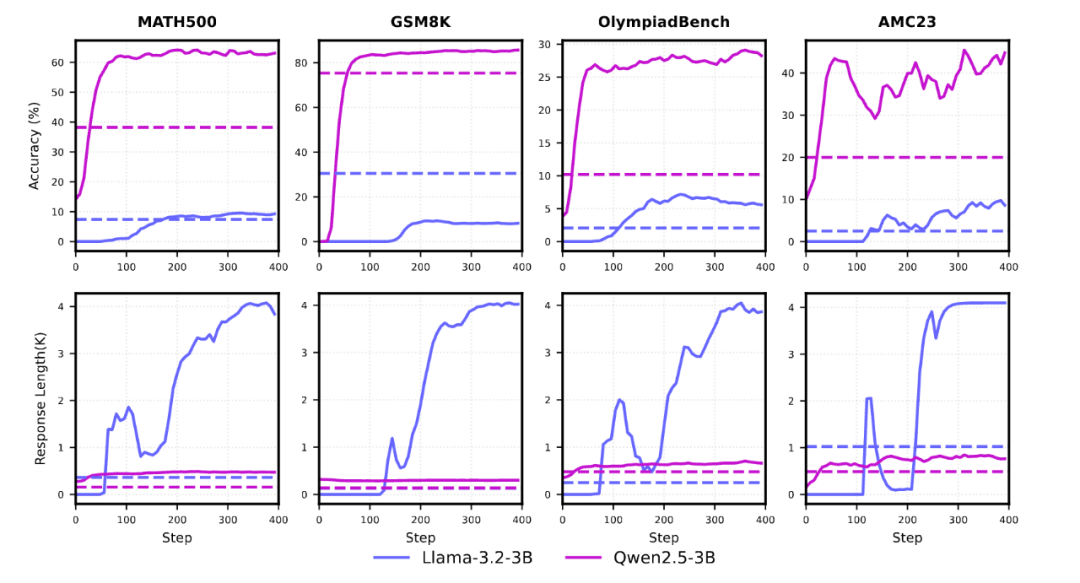
当 Qwen 通过强化学习(如 PPO、GRPO)在数学推理任务中取得显著提升时,Llama 模型常陷入重复输出或过早答题的困境。如下图所示,Llama 在直接RL训练中遇到Reward Hacking和性能提升有限的问题。
深入挖掘:通过可控的中期训练探索关键因素
研究团队对 Llama-3.2-3B 进行大量可控中期训练(每次20B tokens),并观察RL训练的动态表现。
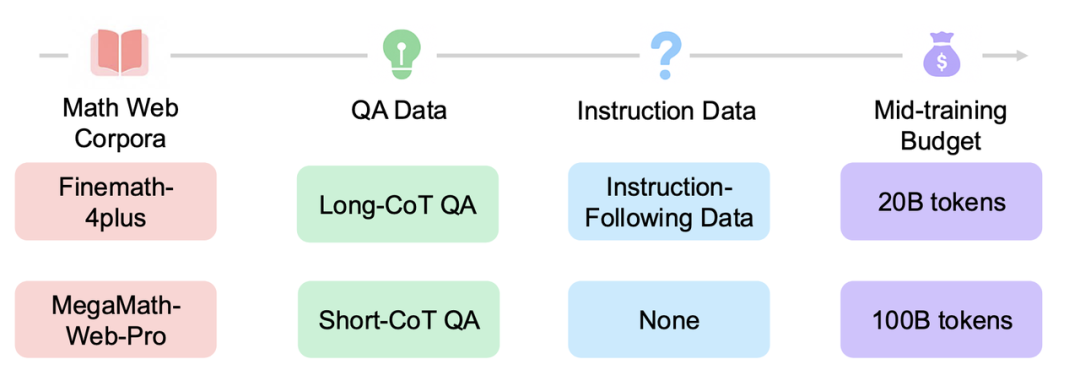

中等训练策略的关键发现
- 高质量数学语料库的重要性:如 MegaMath-Web-Pro 这类高质量数学语料库,显著优于现有方案(如 FineMath-4plus),提升基础模型和RL性能。例如,使用 MegaMath-Web-Pro时,模型在RL任务中的表现优于使用 FineMath-4plus。
- QA格式数据与指令数据的增益:在高质量数学预训练语料基础上,加入QA样式(尤其长链推理)数据,能增强RL效果。少量指令数据的引入也能进一步释放QA数据潜力,帮助模型更好理解任务,从而在RL阶段表现更佳。
- 长链推理的双刃剑效应:长链推理虽能提升推理深度,但也可能引发响应冗长和训练不稳定。研究团队通过设计指令增强提示模板和渐进响应长度调度器,缓解训练不稳定问题。
增加中等训练数据量也能带来更强的RL性能提升,即使在基础模型评估中未明显体现。这表明,中期训练的扩展对最终RL表现至关重要。
自建高质量数学语料库 MegaMath-Web-Pro-Max
在准备语料时,团队发现开源高质量语料缺乏。MegaMath-Web-Pro 仅含不到20B tokens,混合低质量语料易引发训练不稳定。为支持大规模研究,团队创建了 MegaMath-Web-Pro-Max,通过分类器筛选和大模型精炼,构建了更大规模、更高质量的数学语料库,约为原始的5.5倍,具备成为中期训练基础的潜力。
团队还尝试引入长链推理数据以增强模型推理能力,但因数据规模不足未采用。最终,团队采用启发式方法,从文档中提取评分,筛选出高质量数据,确保训练效果。
如下图所示,团队评估了不同召回阈值下的语料质量,选择0.4作为最佳阈值,平衡数据质量与数量。预训练实验证明,MegaMath-Web-Pro-Max在保持高质量的同时,具备大规模中期训练的潜力。
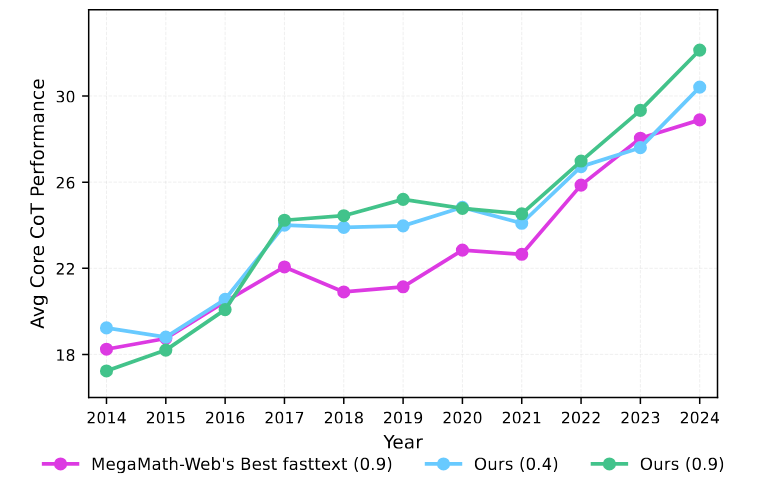
图:研究团队重新召回的数据与 MegaMath-Web 按照年份逐年数据质量对比(不同的 fasttext 阈值)。
考虑到许多文档噪声大、结构差,团队用 Llama-3.1-70B-instruct对文本进行精炼,提示设计借鉴MegaMath-Web-Pro。最终构建的 MegaMath-Web-Pro-Max包含的tokens约为原始的5.5倍,表现出成为大规模中期训练语料的潜力。
团队还尝试引入长链推理数据以扩充正例,但因规模不足未采纳。未来将继续优化数据采集和模型训练策略。
🛠️ 突破性方案:OctoThinker的两阶段“稳定-衰减”训练
基于上述发现,研究团队提出两阶段中等训练策略:
第一阶段:构建强推理基础(200B tokens)
使用恒定学习率对Llama模型进行200B tokens训练,依赖高质量语料(如MegaMath-Web-Pro和DCLM-Baselines),辅以少量合成数据,建立稳固推理基础,为后续RL训练打基础,产出OctoThinker-Base-Stable模型。
第二阶段:分支专业化训练(20B tokens)
采用余弦衰减学习率,加入不同类型数据(短链、长链推理),训练多个分支模型,提升模型推理能力和适应性。
三大推理分支:

OctoThinker基础模型系列的显著提升
经过两阶段训练,OctoThinker模型在数学推理基准测试中表现优异,所有模型尺寸均比原始Llama提升10%-20%,为RL扩展奠定坚实基础。例如,在GSM8K和MATH500等基准中,准确率和推理深度均有明显提升。

图:OctoThinker中期训练后数学榜单表现,1B模型结果。
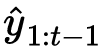
图:3B模型规模的OctoThinker中期训练后数学表现。
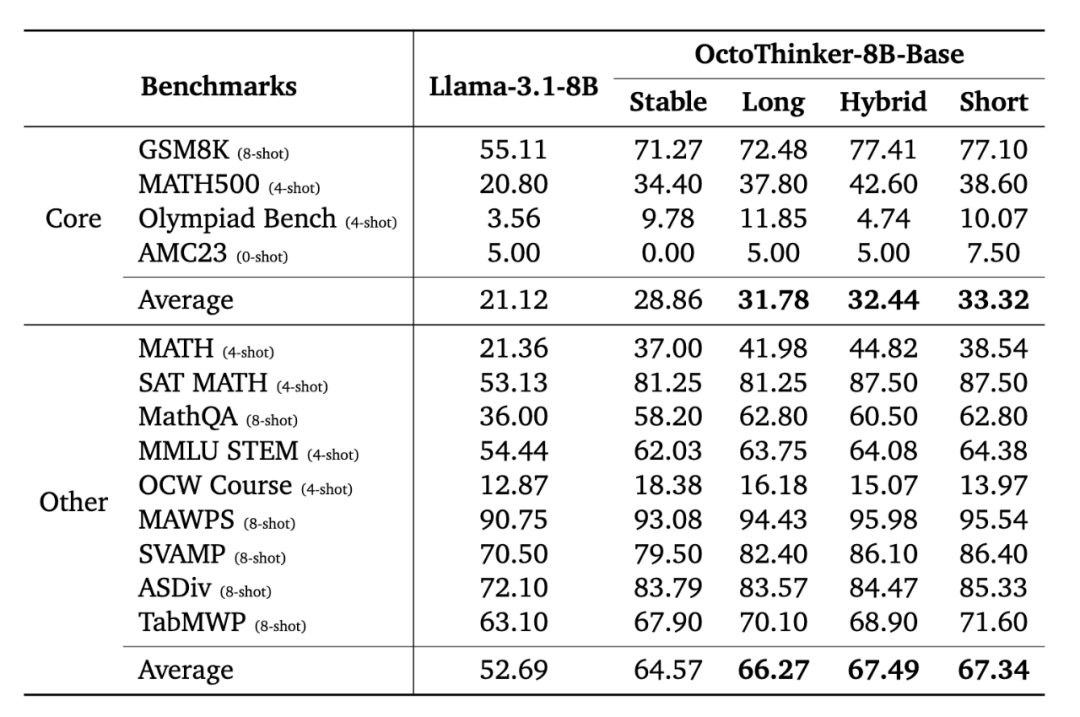
图:8B模型规模的OctoThinker中期训练后数学表现。
OctoThinker-Zero家族在RL训练中的卓越表现
进一步对OctoThinker基础模型进行RL训练后,生成的OctoThinker-Zero系列(包括短链、混合链和长链推理分支)在数学推理任务中表现出与Qwen2.5模型相当的性能。特别是OctoThinker-Long-Zero,在3B模型中,成功媲美以强大推理能力著称的Qwen2.5-3B,充分证明中等训练策略提升Llama RL兼容性的有效性。在多个数学推理基准测试中,OctoThinker-Zero表现与Qwen2.5不相上下,甚至略有超越。
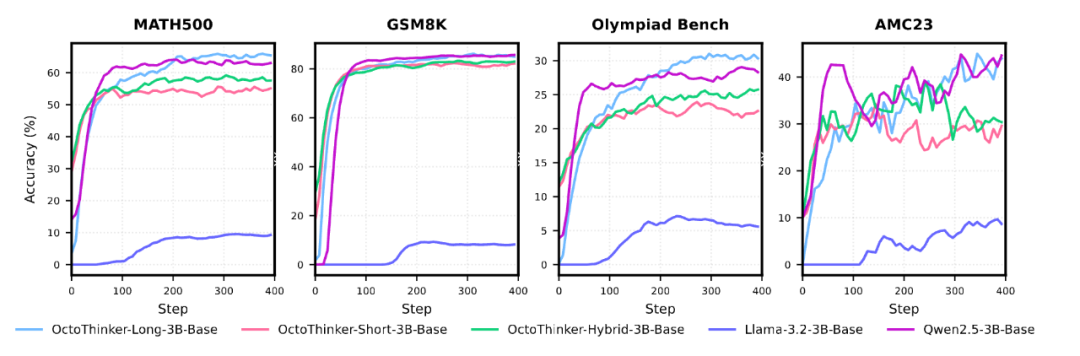
图:OctoThinker系列、Qwen-2.5、Llama-3.2在RL训练中的数学基准测试动态曲线。
未来展望
研究团队计划持续探索:一是优化数学预训练语料库以增强中等训练效果;二是采用无需蒸馏的RL友好基础模型;三是深入分析QA格式与内容的贡献;四是扩展OctoThinker家族,加入工具集成推理等新分支,为预训练与强化学习的交互机制提供更深层次的理解。
[1]: 互联网博主“AI 实话实说”总结的“RL”乱象 — https://www.xiaohongshu.com/user/profile/623bfead000000001000bf09