ICML 2025 Oral! Peking University and Tencent Youtu Breakthrough in Generalizing AI-Generated Image Detection via Orthogonal Subspace Decomposition}
Researchers from Peking University and Tencent Youtu present a novel orthogonal subspace decomposition method at ICML 2025, significantly improving the generalization of AI-generated image detection.


As OpenAI launched GPT-4o's image generation capabilities, AI-generated images (AIGI) reached new heights. But behind the scenes, there are serious security challenges: how to distinguish generated images from real ones? Despite many efforts, the deep generalization problem remains largely unexplored. Is the simple binary classification of real vs. fake really sufficient?
Recently, researchers from Peking University, Tencent Youtu, and other institutions conducted in-depth studies on this challenge. Their findings show that detecting AI-generated images is far more complex than a straightforward real-fake binary classification. They propose a new approach based on orthogonal subspace decomposition, enabling the detection model to shift from "memorization" to "understanding and generalization," significantly enhancing the model's ability to generalize across different types of generated images. This work was accepted as an oral presentation at ICML 2025 (top ~1%).

- Paper title: Orthogonal Subspace Decomposition for Generalizable AI-Generated Image Detection
- Code repository: https://github.com/YZY-stack/Effort-AIGI-Detection
Abstract
We introduce a novel, efficient fine-tuning method based on orthogonal decomposition that preserves pre-trained knowledge while learning new AIGI-related features. Our analysis reveals why current detection models fail to generalize and offers key insights for improvement.
What problem does this solve?
With the rise of AI-generated content, distinguishing real from fake images is crucial for security and content integrity. Unlike standard binary classification, AIGI detection is asymmetric: models tend to overfit to fixed fake patterns, limiting their ability to detect unseen attacks, as shown in Figure 1.
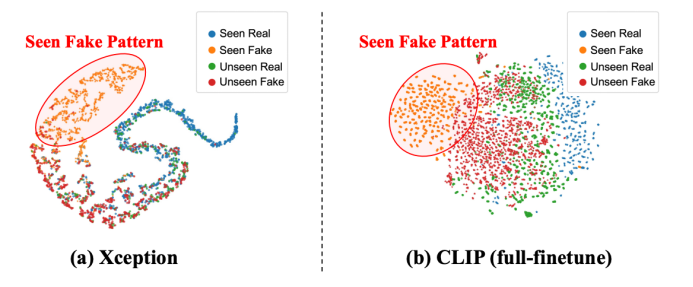
Overfitting to fake patterns causes the feature space to become low-rank and highly constrained, as confirmed by t-SNE analysis in Figure 2, which shows that unseen fake and real images are indistinguishable.
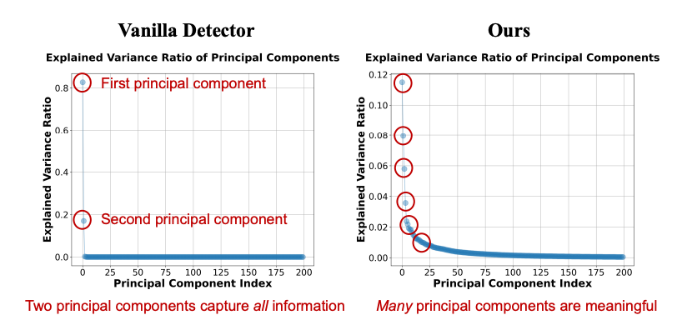
Quantitative analysis using PCA (Figures 3 and 4) shows that traditional models' feature spaces are highly limited, with most variance explained by just two principal components, indicating severe overfitting and loss of pre-trained knowledge.
Our analysis further shows that fine-tuning methods like LoRA or full fine-tuning significantly reduce the effective dimension of the feature space, leading to catastrophic forgetting of pre-trained knowledge, as shown in Figure 4.
Proposed Solution and Methodology
We propose an explicit orthogonal subspace decomposition based on SVD, constructing two orthogonal subspaces: the principal component space (retaining pre-trained knowledge) and the residual space (learning new AIGI-specific features). These subspaces are strictly orthogonal under SVD constraints (Figure 5).
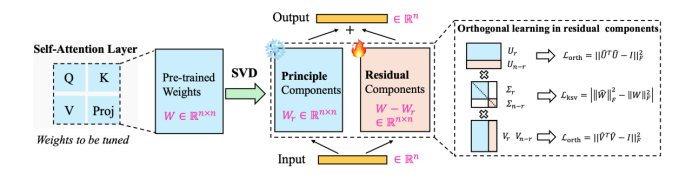
Figure 6 illustrates our algorithm: applying SVD to each ViT block's linear layers, freezing the top singular value components, and fine-tuning the residual parts, with additional regularization to control the update strength.
Our experiments show that this approach maintains high-rank feature spaces, preserves pre-trained knowledge, and improves generalization in tasks like DeepFake face detection and AIGC image authenticity detection (Tables 1 and 2).
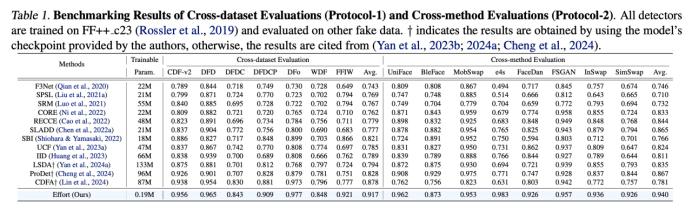
Tables 1 and 2 demonstrate the effectiveness of our method in various detection benchmarks, showing improved robustness and generalization compared to baseline models.
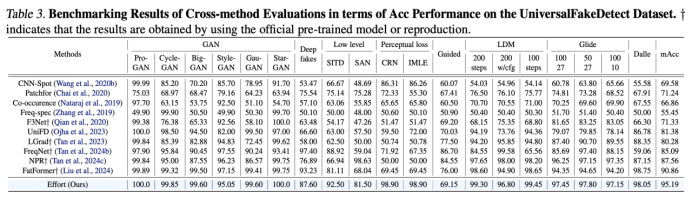
Figure 7 visualizes attention maps across different layers of CLIP, showing that our method preserves semantic information in shallow layers while orthogonalizing fake features, confirming the effectiveness of the approach.
Our insights reveal that the real-fake relationship is hierarchical: fake images are derived from real images, sharing semantic space. This prior knowledge is key to achieving good generalization, as shown in Figure 8, which illustrates semantic clustering and reduced complexity in decision boundaries.
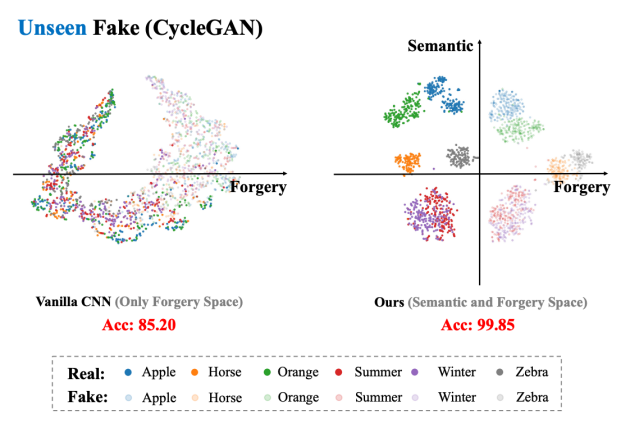
Figure 8 emphasizes that real and fake classes are not symmetric but hierarchically related, with fake derived from real. Our method retains semantic priors, enabling better generalization and robustness in detection tasks.
In the era of increasingly realistic AI-generated images, accurately distinguishing real from fake is critical. Our orthogonal subspace decomposition approach addresses the core challenge of poor cross-model generalization, and the framework can be extended to other tasks like fine-tuning large models, out-of-distribution detection, domain generalization, diffusion generation, and anomaly detection, offering a new paradigm for balancing knowledge retention and adaptation.