ICCV 2025 | Reducing Spatiotemporal Redundancy in Diffusion Models with Shanghai Jiao Tong’s EEdit for Zero-Training Image Editing Acceleration}
Shanghai Jiao Tong University’s EEdit framework accelerates image editing by eliminating training, significantly reducing spatiotemporal redundancy in diffusion models, showcased at ICCV 2025.


First authors: Yan Zexuan and Ma Yue, graduate students at Shanghai Jiao Tong University and Hong Kong University of Science and Technology, respectively, researching efficient models and AIGC, under Prof. Zhang Linfeng’s guidance at EPIC Lab.
This paper introduces the latest work from Prof. Zhang’s team: EEdit⚡: Rethinking the Spatial and Temporal Redundancy for Efficient Image Editing.
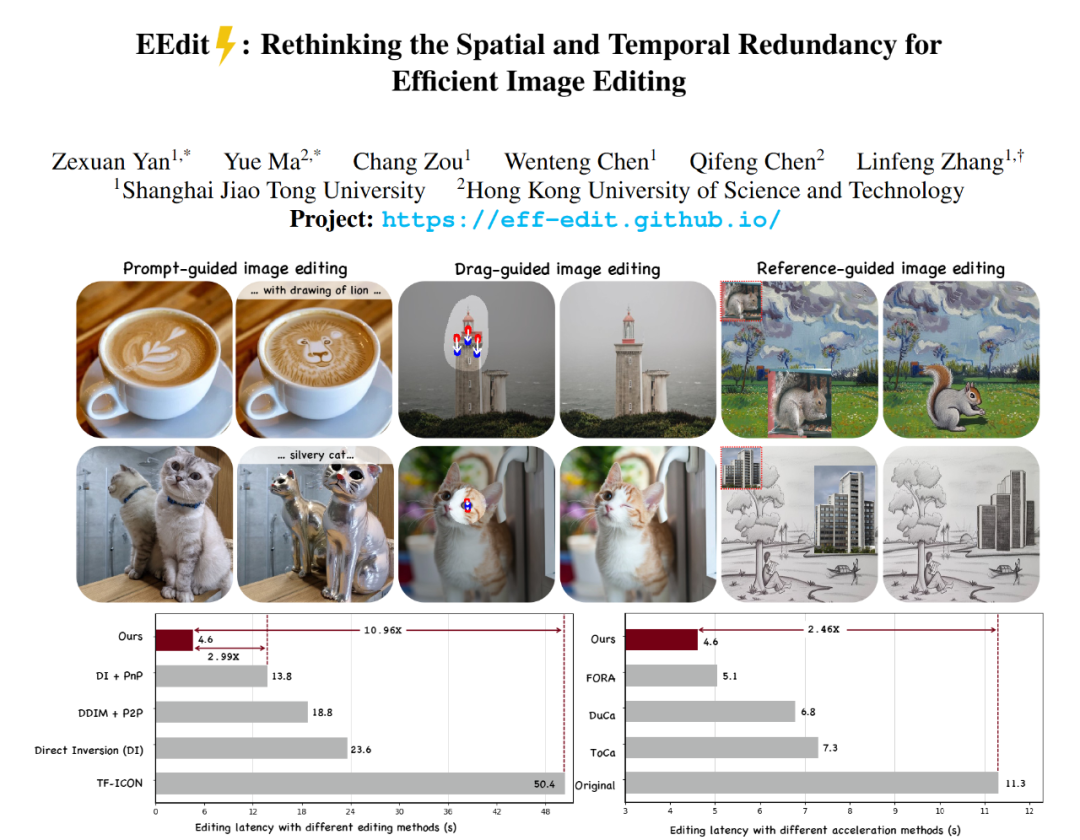
This is the first framework designed to accelerate matching flow models supporting multiple guidance schemes. It achieves a speedup of 2.4× over the original workflow, with flexible input guidance including reference images, region dragging, and prompt-based editing. The framework uses a training-free acceleration algorithm, requiring no fine-tuning or distillation.
The paper has been accepted at ICCV 2025.
- Paper link: https://arxiv.org/pdf/2503.10270
- Open source: https://github.com/yuriYanZeXuan/EEdit
Recently, flow matching-based diffusion training has become a hot topic due to its elegant mathematical form and short-step generation ability. Notably, Black Forest Lab’s FLUX series surpasses previous SD models, reaching SOTA in performance and quality.
However, diffusion models still face challenges in image editing, including high step counts, costly inversion processes, and unnecessary computation in non-edit regions, leading to resource waste. Currently, there is no unified acceleration scheme for flow matching models in editing tasks, making this a blue ocean for research.
To address this, Shanghai Jiao Tong’s EPIC Lab proposes EEdit, a training-free, cache-based acceleration framework.
The core idea is to use feature reuse during the diffusion inversion-denoising process to compress the number of steps by exploiting temporal redundancy; and to control region updates via regional reward, reusing features in non-edit regions while updating editing regions more frequently for efficiency.
EEdit’s key highlights include:
- Training-free, high-speed acceleration: Based on open-source FLUX-dev, it achieves over 2.4× inference speedup without any training or distillation, and over 10× faster than other editing methods.
- First to explore and solve the computational waste caused by spatiotemporal redundancy: Through feature reuse and regional reward control, it reduces unnecessary computation in non-edit regions.
- Supports multiple input guidance types: Including reference image guidance, prompt-based editing, and region dragging.
Let’s explore the details of this research.
Research motivation

In a real-world image editing case, the authors discovered spatiotemporal redundancy in diffusion-based editing tasks.
Non-edit regions exhibit higher spatial redundancy: Visualized difference maps show high variation in regions like animal faces and fur textures, while other areas remain unchanged. Reordering hidden layer states and heatmaps reveal consistent spatial redundancy: editing regions have low similarity pre- and post-inversion, while non-edit regions are highly similar.
Inversion process has higher temporal redundancy: By skipping certain diffusion steps during inversion, the authors control computation. Reducing denoising steps causes rapid quality degradation, but skipping inversion steps maintains quality, significantly speeding up editing.
Method overview
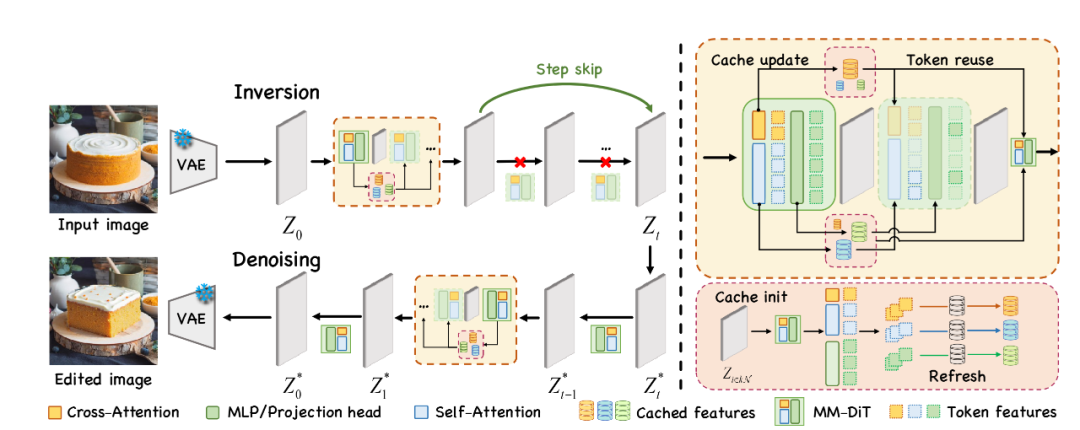
Figure 2: Cache acceleration scheme based on diffusion inversion-denoising paradigm
Using a diffusion inversion-denoising framework, the authors propose an effective, training-free cache acceleration method. The process involves fixed cycle steps for inversion and denoising, with partial computation within cycles for cache updates. They introduce Inversion Step Skipping (ISS) to reuse features and reduce computation during inversion.
For cache updates, a spatial locality caching algorithm (SLoC) is designed, leveraging the editing mask as prior knowledge to selectively update feature tokens in relevant regions. SLoC controls the update frequency based on a score map, balancing accuracy and efficiency by adaptively updating tokens in different regions.
The authors also use Token Index Preprocessing (TIP) to precompute cache indices offline, further accelerating cache updates. Overall, the spatial-aware cache reuse and update strategy enables EEdit to achieve over 2.4× speedup while maintaining image quality.
Experimental results
Experiments on FLUX models using open-source weights evaluate EEdit across PIE-bench, Drag-DR, Drag-SR, and TF-ICON datasets, demonstrating both qualitative and quantitative improvements.

Figure 4: Comparison of SLoC with existing SD series and FLUX series across various metrics
Quantitative metrics include PSNR, LPIPS, SSIM, CLIP, FLOPs, and inference time. Results show that SLoC+ISS achieves the best overall performance with significant speed and resource savings, competitive even against smaller models.

Figure 5: Performance of EEdit under various guidance conditions compared to other methods
Qualitative experiments show that EEdit offers stronger editing precision and background consistency across different guidance modes. It maintains style and object identity better than other approaches, especially in prompt-based and region-dragged tasks.
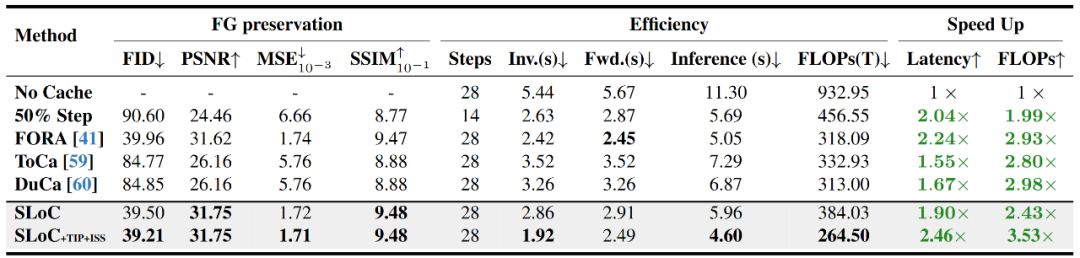
Figure 6: Spatial locality cache performance comparison with other acceleration methods
The spatial locality cache (SLoC) outperforms other cache algorithms like FORA, ToCa, and DuCa in acceleration ratio, inference delay, and foreground preservation, with over 50% improvement in some metrics.
For citation:
@misc{yan2025EEdit,
title={EEdit: Rethinking the Spatial and Temporal Redundancy for Efficient Image Editing},
author={Zexuan Yan, Yue Ma, Chang Zou, Wenteng Chen, Qifeng Chen, Linfeng Zhang},
year={2025},
eprint={2503.10270},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.10270},
}