Humanoid Robot's Hamburger Making Goes Viral! Berkeley and Others Launch New ViTacFormer for Steady Robot Manipulation}
New ViTacFormer models from Berkeley and partners enable humanoid robots to make hamburgers with high precision, stability, and multi-stage control, revolutionizing robotic dexterity.


Recently, a video of a humanoid robot making hamburgers went viral online!
This robot, equipped with active vision, high-precision tactile sensors, and highly dexterous hands, achieved 2.5 minutes of continuous autonomous control, starting from raw materials to produce a complete burger and deliver it to your plate.
Truly enabling robots to “see,” “touch,” and “move skillfully,” the future kitchen might really no longer need humans!
Dexterous control is key for humanoid interaction, especially in multi-stage, delicate tasks requiring high control precision and response timing. Although vision-driven methods have rapidly advanced, they often fail under occlusion, lighting changes, or complex contact environments.
Tactile sensing provides direct feedback for environment interaction, crucial for contact state and force timing judgments. However, most current methods treat tactile info as static input, lacking effective multimodal joint modeling. More critically, they often ignore future tactile changes, leading to poor stability and strategy in sequential tasks requiring temporal perception and force judgment.
Despite some research incorporating tactile info, they mainly rely on simple concatenation or auxiliary channels, lacking structural design to fully exploit vision-tactile synergy.
To address these challenges, researchers from UC Berkeley, Peking University, and Sharpa propose ViTacFormer, a unified framework that fuses visual and tactile info and introduces future tactile prediction mechanisms, designed to improve control accuracy, stability, and continuous manipulation capabilities.
The paper’s authors include renowned UC Berkeley experts Pieter Abbeel and Jitendra Malik, along with their student, Peking University alumnus and UC Berkeley PhD candidate Geng Haoran (project lead).

- Paper Title: ViTacFormer: Learning Cross-Modal Representation for Visuo-Tactile Dexterous Manipulation
- Project Homepage: https://roboverseorg.github.io/ViTacFormerPage/
- GitHub Repository: https://github.com/RoboVerseOrg/ViTacFormer
This research has received high recognition from industry experts, including discussions and shares by prominent scholars and entrepreneurs, such as GPT-4 author Lukasz Kaiser.
Introduction to ViTacFormer
Method Design: Cross-Modal Attention and Tactile Prediction
ViTacFormer’s core idea is to build a cross-modal representation space that dynamically fuses visual information and tactile signals at each step of the policy network through multi-layer cross-attention modules, enabling joint modeling of contact semantics and spatial structure.
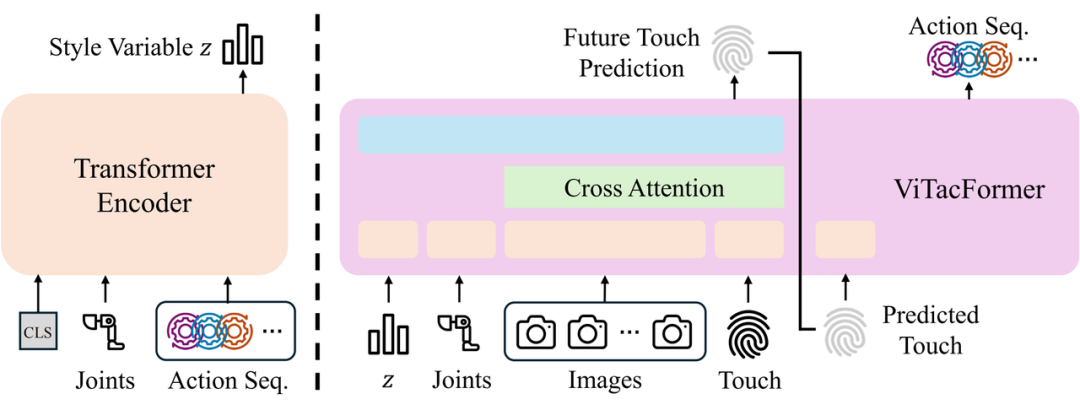
Unlike traditional methods relying solely on current tactile observations, ViTacFormer introduces an autoregressive tactile prediction branch to enhance future contact state modeling. This module shares a representation space encoding predictive tactile dynamic features, allowing the policy to not only “see” and “touch” but also “predict the next tactile change.”
During inference, the model first predicts future tactile feedback based on current observations, then uses it to guide action generation, achieving a crucial shift from “perceiving now” to “predicting future.” Experiments show that this forward-looking modeling based on future tactile signals significantly improves the stability and accuracy of action strategies.
System Architecture: Dual-Arm Dexterous Hands and Visual-Tactile Data Collection
ViTacFormer is based on a dual-arm robotic system for data collection and policy evaluation. The system consists of two Realman robotic arms, each equipped with a SharpaWave dexterous hand (development version) with 5 fingers and 17 degrees of freedom, supporting high-degree finger movements. Each fingertip is fitted with a 320×240 resolution tactile sensor for real-time contact feedback.
Visual perception includes two perspectives: a fisheye camera on the wrist for close-up local views and a ZED Mini stereo camera on top for global scene capture. Visual and tactile data are synchronized to cover key state changes during operation.
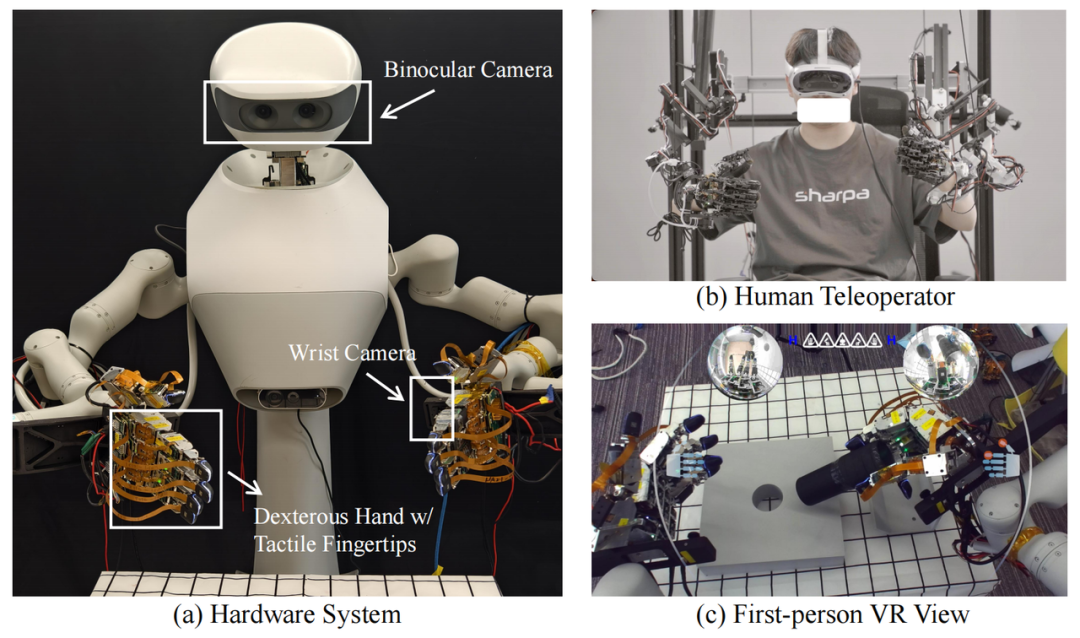
During expert demonstrations, a remote operation system based on mechanical exoskeleton gloves was used. Operators control the robot via gloves linked to mechanical joints, with VR headsets providing immersive first-person feedback. The interface integrates stereo top views, dual-arm local views, and real-time tactile overlays, supporting natural, intuitive control and improving demonstration quality for contact-intensive tasks.
Experimental Evaluation: Real-World Task Performance
Baseline Comparison: Short-Range Dexterous Tasks
The team evaluated ViTacFormer on four real short-range manipulation tasks: Peg Insertion, Cap Twist, Vase Wipe, and Book Flip, each requiring precise contact and fine control.
Each task was trained with only 50 expert trajectories and tested with 10 independent inferences to assess the model’s learning and stability under limited data.
The team compared ViTacFormer with four current state-of-the-art imitation learning baselines: Diffusion Policy (DP), HATO, ACT, and ACTw/T. DP and ACT are mainstream visual imitation strategies without tactile info; HATO and ACTw/T incorporate tactile signals but rely on simple concatenation or token fusion, lacking deep modeling.
In contrast, ViTacFormer uses cross-modal attention and autoregressive prediction, fully exploiting the dynamic dependencies between vision and tactile data.
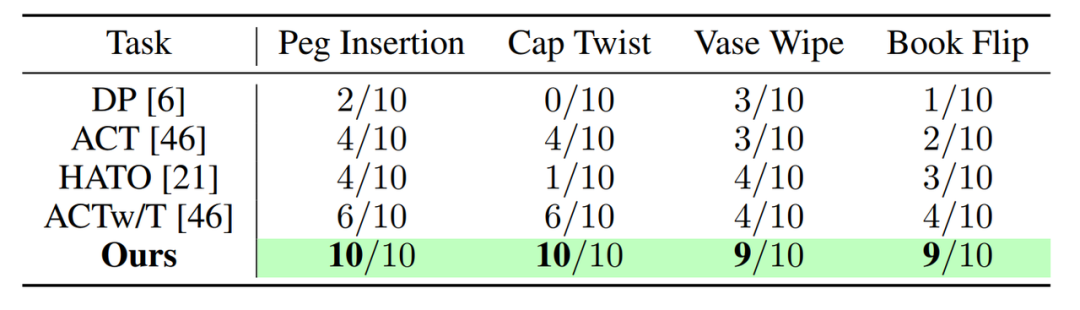
Results show that ViTacFormer outperforms existing methods in all short-range manipulation tasks, with success rates increasing by over 50% compared to models using only vision or simple tactile fusion. This highlights the importance of cross-modal attention and future tactile prediction for stability and precision.
Long-term Task Evaluation Stable Completion of 11-Stage Sequential Operations
To further validate ViTacFormer’s performance in complex tasks, the team tested it on a long-term manipulation task involving 11 consecutive stages, simulating burger-making, requiring multi-finger coordination, fine contact, and sustained control.
The results showed that ViTacFormer could reliably complete the entire sequence, maintaining about 2.5 minutes of continuous operation with over 80% success rate. Its performance in multi-stage, long-duration tasks demonstrates the advantages of visual-tactile fusion strategies in complex scenarios.