Human-AI Collaboration Filters 26 Million Data Points, Seven SOTA Benchmarks Achieved, Kunlun Wanwei’s Open-Source Reward Model Breakthrough}
Kunlun Wanwei’s latest reward model, trained with human-AI collaboration on 26 million data points, sets new records across seven benchmarks, advancing open-source AI capabilities.

Large language models (LLMs) are renowned for their generative abilities, but making them “obedient” is a complex challenge.
Reinforcement learning from human feedback (RLHF) is used to address this, with the Reward Model (RM) playing a crucial role in scoring generated content, guiding the model towards aligned and ethical outputs.
Therefore, the RM is vital for large models: it must accurately evaluate, be versatile across knowledge domains, possess flexible judgment, handle various inputs, and be scalable.
On July 4th, Kunlun Wanwei released the new generation of reward models, Skywork-Reward-V2 series, pushing the technology’s limits further.
The Skywork-Reward-V2 series includes 8 models based on different base models and sizes, ranging from 600 million to 8 billion parameters, all achieving first place on seven major benchmark leaderboards.

Performance of Skywork-Reward-V2 models on mainstream benchmarks.
These models demonstrate broad applicability, excelling in general alignment with human preferences, objectivity, correctness, safety, style bias resistance, and N-best extension capabilities. The series is now open source.
- Research Paper: https://arxiv.org/abs/2507.01352
- HuggingFace: https://huggingface.co/collections/Skywork/skywork-reward-v2-685cc86ce5d9c9e4be500c84
- GitHub: https://github.com/SkyworkAI/Skywork-Reward-V2
Since its first open-source release in September last year, Skywork-Reward models and datasets have been widely adopted by the AI community, with over 750,000 downloads on Hugging Face, and have contributed to top results in RewardBench and other evaluations.

Now, the open-sourcing of this reward model may attract even greater attention.
Building Tens of Millions of Human Preference Data
Aligning large models’ outputs with human preferences is a complex task.
Due to the complexity and diversity of real-world tasks, reward models often serve as imperfect proxies for true preferences, risking over-optimization and deviation from human values.
Current state-of-the-art open-source reward models still struggle to capture the nuanced features of human preferences, especially in multi-dimensional feedback, often overfitting to specific benchmarks and lacking transferability.
Efforts to improve performance include optimizing objective functions, model architectures, and recent generative reward models, but overall results remain limited.
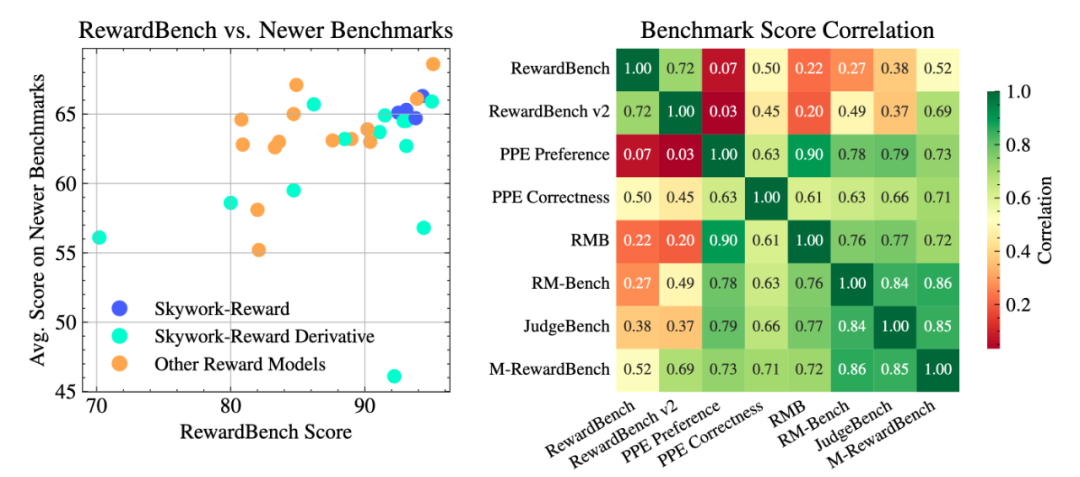
Left: comparison of 31 top open-source reward models on RewardBench; Right: correlation of scores—many models improve on RewardBench but plateau elsewhere, indicating overfitting.
Meanwhile, models like OpenAI’s o series and DeepSeek-R1 are advancing “Verifiable Reward Reinforcement Learning” (RLVR), using character matching, systematic unit tests, and multi-rule mechanisms to verify if outputs meet predefined criteria. While offering high controllability and stability in specific scenarios, these methods struggle to fully capture complex human preferences, limiting their effectiveness in open-ended, subjective tasks.
In response, Kunlun Wanwei is working on data and foundational models.
First, they built the largest preference-annotated dataset, Skywork-SynPref-40M, containing 40 million preference pairs, using a novel “human-AI, two-stage iterative” data selection pipeline.
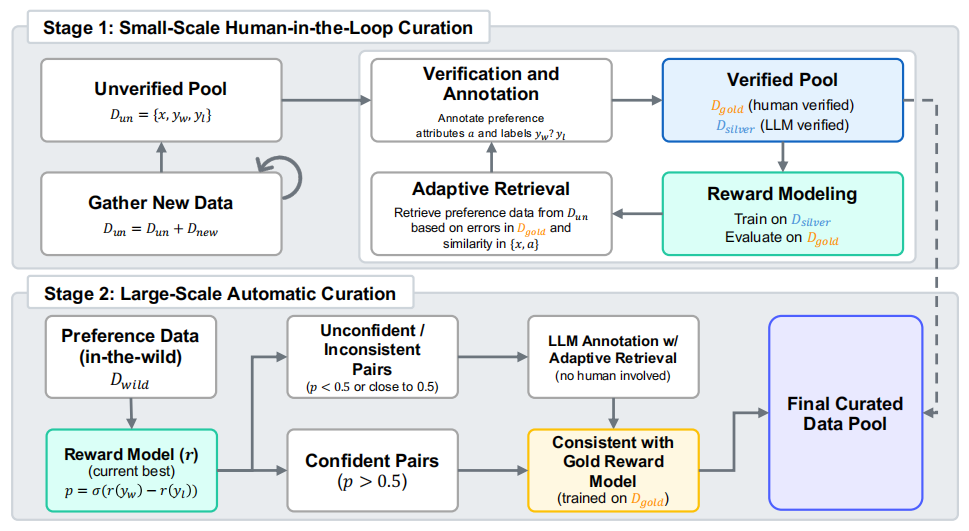
Two-stage preference data processing pipeline.
This process has two phases:
Phase 1: Human-guided high-quality preference construction. To break the vicious cycle of “low-quality data → weak models → poor generated data,” researchers use a “gold standard anchor + silver standard expansion” dual-track approach, combining manual precision with model-driven scaling.
Specifically, human and large models annotate “gold” and “silver” preferences, train reward models on silver data, evaluate against gold data, and iteratively re-annotate underperforming samples for next training rounds, repeated multiple times.
Phase 2: Fully automated large-scale preference data expansion. The trained reward model, combined with a “gold” reward model trained on verified human data, filters data through consistency checks, enabling expansion to millions of preference pairs without manual supervision.
This process balances quality and scale, significantly reducing manual annotation while maintaining high data quality.
Breaking Volume Limits: Parameter Differences by Dozens Still Matter
Skywork-Reward-V2 models trained with human-AI data surpass expectations.
Compared to last September’s Skywork-Reward, the V2 series trained models based on Qwen3 and LLaMA 3, covering a broader parameter range.
In benchmarks like RewardBench v1/v2, PPE Preference & Correctness, RMB, RM-Bench, and JudgeBench, Skywork-Reward-V2 set new records.
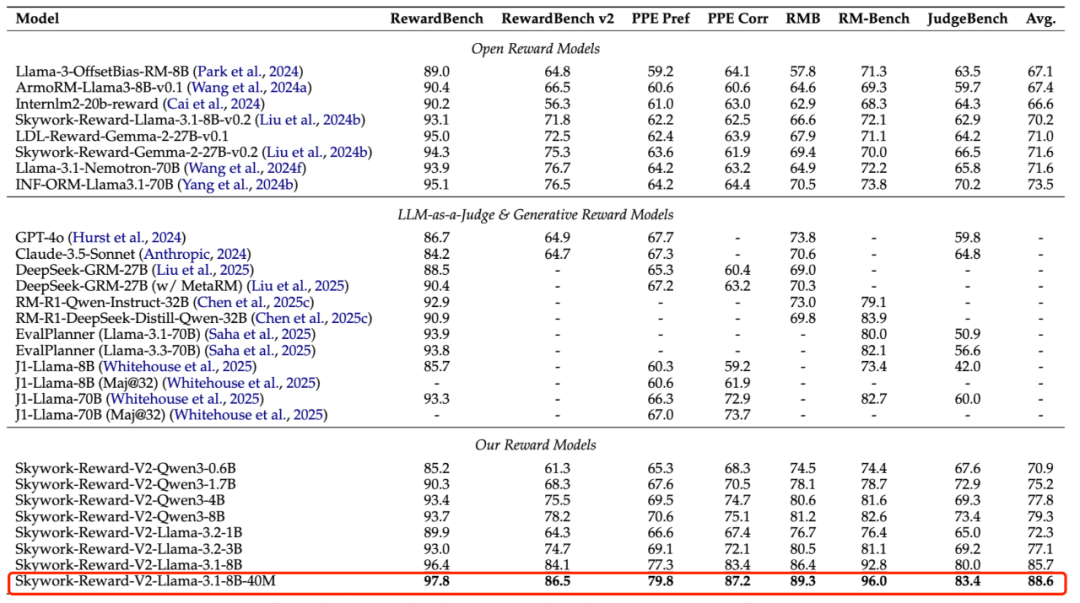
Key insights behind these SOTA results include:
First, improving data quality and richness greatly offsets parameter scale limitations, enabling small expert models to excel in specific tasks.
For example, on RewardBench v2, Skywork-Reward-V2 models, even as small as Skywork-Reward-V2-Qwen3-0.6B, significantly close the gap with the previous top model Skywork-Reward-Gemma-2-27B, which has 45 times more parameters.
Furthermore, Skywork-Reward-V2-Qwen3-1.7B performs comparably to the open-source SOTA INF-ORM-Llama3.1-70B, surpassing in some metrics like Precise IF and Math. The largest models, Skywork-Reward-V2-Llama-3.1-8B and 8B-40M, learn pure preference representations, outperforming closed-source models like Claude-3.7-Sonnet and recent generative reward models, achieving comprehensive SOTA across benchmarks.
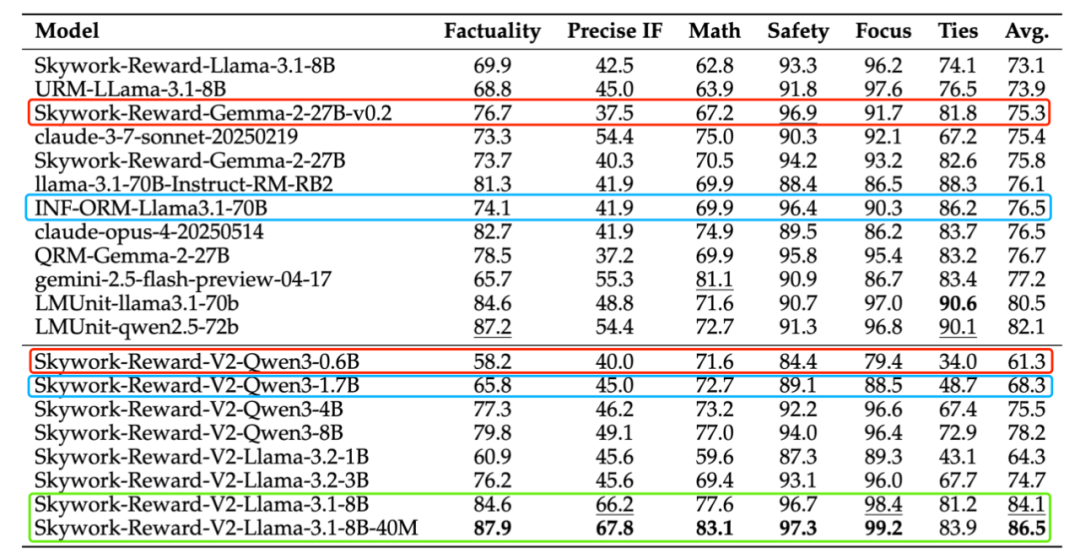
RewardBench v2 benchmark results.
These results highlight that:
- Targeted, high-quality training data can support “small but expert” models, offsetting the need for massive parameters.
- Data-driven and structure-optimized training can rival parameter scaling, emphasizing meticulous data engineering.
Second, as the ability to model human values structurally improves, reward models are evolving from “weak supervision scorers” to “robust, generalized value models.”
On the objective correctness benchmark JudgeBench, Skywork-Reward-V2 performs well in knowledge, reasoning, math, and coding tasks, surpassing many models focused on reasoning and programming, including GPT-4o.
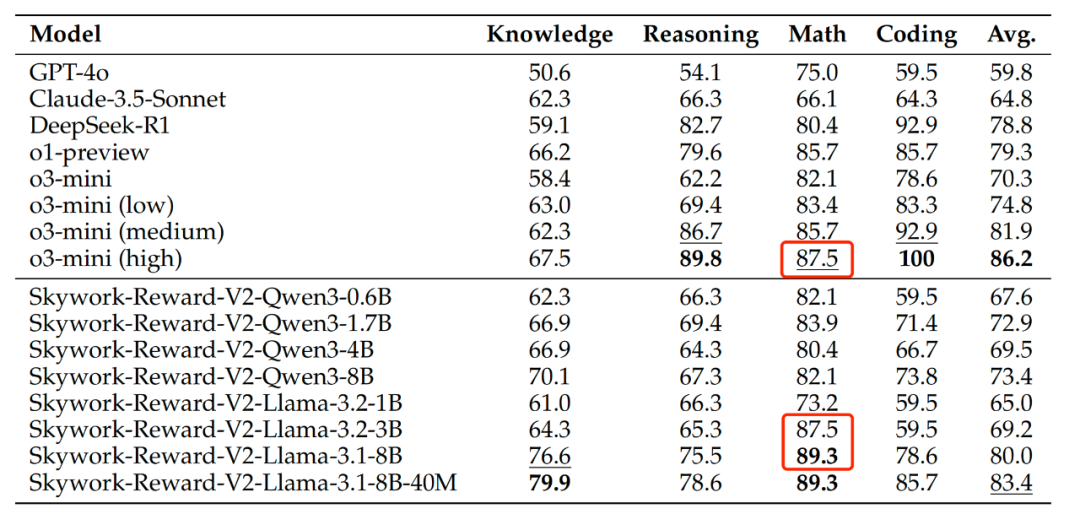
In PPE Correctness, all 8 models show strong BoN performance, surpassing GPT-4o, with the highest leading by 20 points.
Additionally, the BoN curves for five high-difficulty tasks in PPE Correctness show continuous positive expansion, with all models reaching SOTA levels.
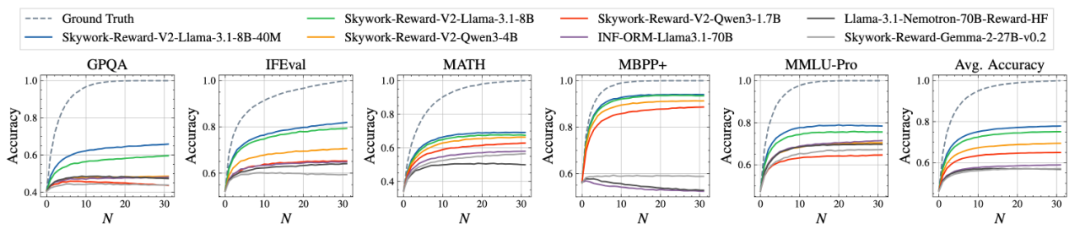
In other advanced assessments like RM-Bench (bias resistance) and RewardBench v2 (complex instruction understanding and authenticity), Skywork-Reward-V2 demonstrates strong generalization and practicality.
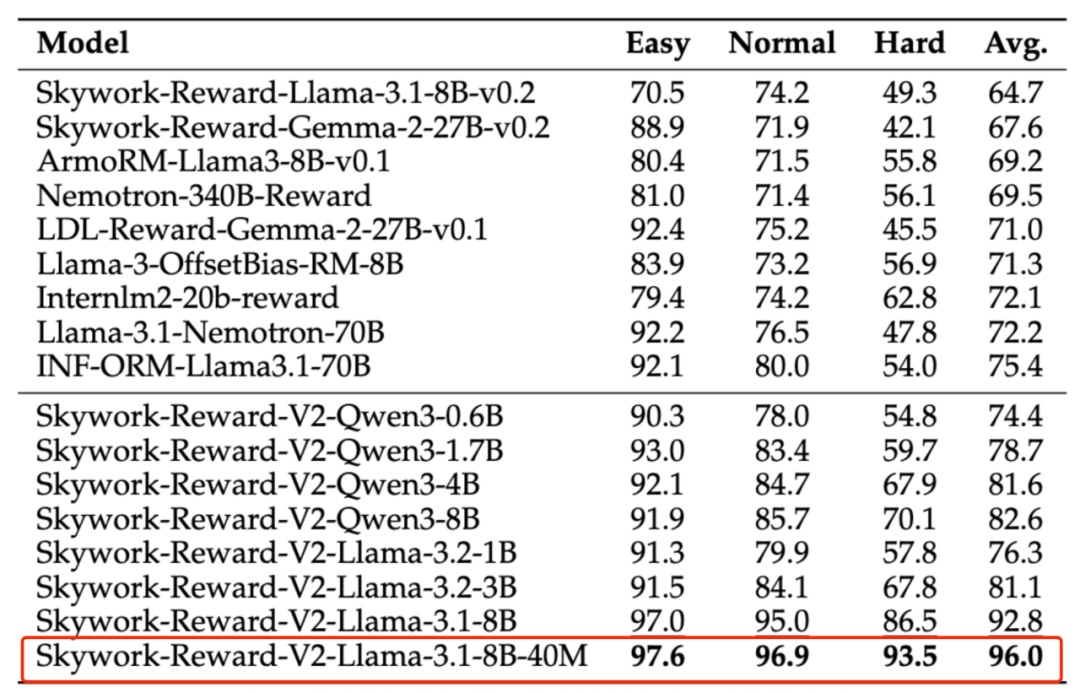
In high-difficulty, style bias resistance tests, Skywork-Reward-V2 achieves SOTA.
Finally, iterative filtering and refinement of preference data continue to effectively enhance reward model performance, reaffirming the scale and quality advantages of Skywork-SynPref dataset, embodying the “less but better” philosophy.
Experiments on a subset of 16 million high-quality data show that training an 8B model with just 1.8% (~290,000) of this data surpasses current 70B SOTA reward models.
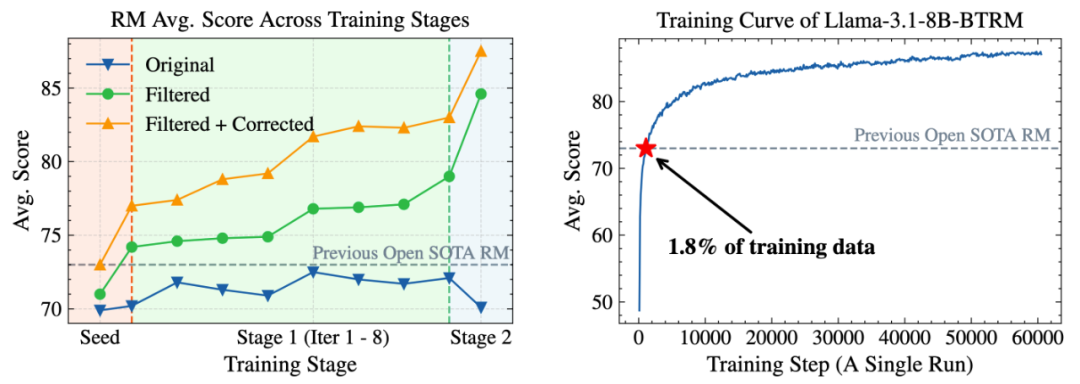
Left: the data filtering process, showing score trends across raw, filtered, and refined datasets; Right: the initial version of Skywork-Reward-V2-Llama-3.1-8B’s average score after final training.
As the reward model’s capabilities expand, it will play a more central role in multi-dimensional preference understanding, complex decision evaluation, and human value alignment in the future.
Conclusion
Skywork-Reward-V2’s empirical results suggest that data construction itself is a form of modeling, which can improve current reward models and drive future data-driven alignment techniques.
Automated annotation methods leveraging large language models can reduce costs, improve accuracy, and generate large-scale preference data, laying a foundation for enhanced model capabilities.
Kunlun Wanwei states that future data organization based on human + AI collaboration will unlock more potential of large models.
Besides open-sourcing reward models, since early 2025, Kunlun Wanwei has been one of the most prolific open-source AI companies, releasing:
- Software Engineering (SWE) autonomous code agent “Skywork-SWE”: achieving industry-leading repository-level code repair at 32B scale;
- Spatial Intelligence “Matrix-Game”: the industry’s first open-source 10B spatial intelligence model;
- Multimodal Chain-of-Thought Reasoning “Skywork-R1V”: successfully transferring strong text reasoning to visual modalities;
- Video Generation Models: SkyReels-V1 and the recent SkyReels-V2, the world’s first diffusion-based infinite-length movie generation model;
- Mathematical Code Reasoning “Skywork-OR1”: achieving industry-leading reasoning performance at similar parameter scales, breaking through the bottleneck of logical understanding and complex problem-solving.
These open-source efforts will accelerate the iteration of large model technologies.