How to Align DNNs with Human Perception: Pixels or Concepts?}
This article explores the differences between how deep neural networks and humans perceive the world, focusing on whether they rely on pixels or abstract concepts for recognition and understanding.

Editor: %
Humans focus on the meaning of objects, while AI emphasizes visual features.
Many previous studies comparing human and AI representations relied on global scalar metrics to quantify their alignment. However, without clear assumptions, these metrics only indicate the degree of alignment, not the underlying reasons.
This raises a critical question: "How similar are the 'perception' judgments of AI and the human brain?"
Researchers from the Max Planck Institute and Nijmegen Institute proposed a universal framework to compare human and AI representations.
The study, titled "Dimensions underlying the representational alignment of deep neural networks with humans", was published on June 23, 2025, in Nature Machine Intelligence.

Playing Find the Difference with AI and Humans
Previous experiments mainly focused on behavior strategies like classification, revealing limitations in DNN generalization. While correlation coefficients or explained variance are used to compare representations, they lack interpretability without assumptions about bias sources.
The framework, inspired by recent cognitive science research, reveals multiple interpretable dimensions in DNNs that reflect visual and semantic attributes, showing substantial alignment with human performance.
Participants and DNNs (VGG-16) were asked to select the "least similar" image among three (e.g., cat, dog, cage), a task akin to human object recognition, suitable for comparing object representations.
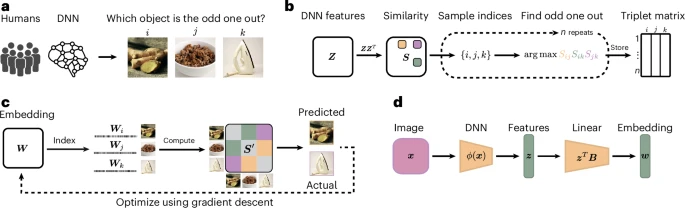
Analysis of 4.7 million human judgments and 24,000 AI responses used variational embedding techniques (VICE) to extract "thought dimensions": 68 semantic brain circuits in humans and 70 visual codes in AI.
These dimensions captured 84.03% of the total variance in image similarity for DNNs, 82.85% for humans, and 91.20% of the explainable variance based on dataset noise ceiling.
Differences in Dimensions
Participants labeled each dimension to verify observations. The interpretability of DNN dimensions mainly reflects semantic and visual attributes (semantic classification, knowledge, perception), whereas human dimensions are more semantic-driven with fewer mixed dimensions.
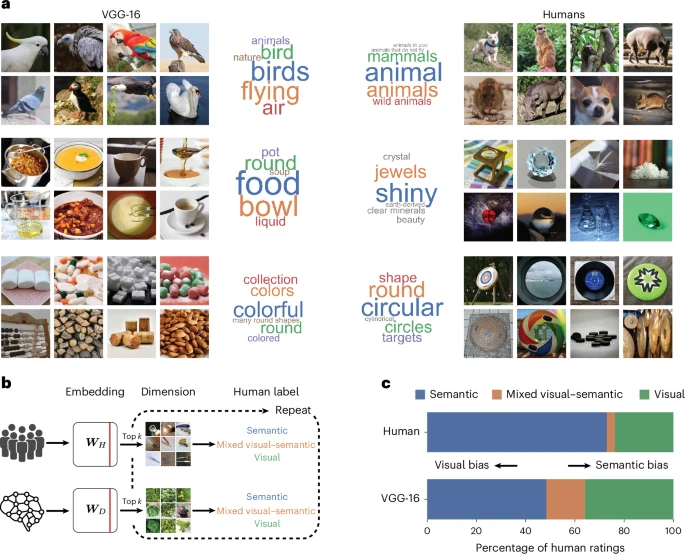
Using Grad-CAM to generate heatmaps, the study revealed which image regions drive DNN dimensions. While Grad-CAM locates visual focus areas, it remains a "visual feature patchwork," unlike human semantic encoding.
Although Grad-CAM can identify AI attention regions, it fundamentally differs from human semantic abstraction. For example, the "animal" dimension responds consistently across animal images for humans, but varies with background in AI.
Summary
Compared to humans, DNNs primarily rely on visual or mixed visual-semantic dimensions, with less interpretability in their representations. They approximate human semantic understanding but through different embedded features.
The significance of this research lies in understanding the differences in representations and behaviors between humans and AI, guiding future work to improve alignment and training strategies.