Fivefold Acceleration of Reasoning: Unlocking Autoregressive Potential with Apple’s New Work to Predict the Future}
Apple’s latest research introduces a framework that enables large language models to perform multi-token predictions, significantly boosting inference speed and efficiency in incomplete information scenarios.

In recent years, the remarkable progress of language models has been largely driven by the availability of large-scale text data and the effectiveness of autoregressive training methods.
Within this autoregressive framework, each token is predicted based on its preceding context.
This approach does not require explicit annotations, giving autoregressive models a clear advantage during training, and making it the dominant paradigm.
However, during inference, autoregressive generation is inherently sequential, leading to high computational costs because each decoding step requires running the model once. In contrast, humans often organize their thoughts at the sentence level before outputting word by word.
So, can large models break free from the bottleneck of sequential token prediction and, like humans, consider output content from a broader perspective during inference?
If this can be achieved, it would create a "time-jumping" capability for LLMs, as some netizens have suggested.

Inspired by this idea, Apple researchers have developed a framework that allows pre-trained autoregressive large language models to perform multi-token prediction. This not only maintains high generation quality but also achieves up to 5.35 times inference acceleration for code and math tasks, and about 2.5 times for general tasks.
AI engineer Jackson Atkins considers this a groundbreaking work, stating, "The most exciting part is that all of this can be achieved through fine-tuning existing models with LoRA."
Imagine reducing AI operational costs by several times or running powerful real-time assistants smoothly on lightweight devices—this would be a revolutionary change in inference optimization.
If you had a large language model with 5x faster speed, what would be the first thing you'd do?

- Paper Title: Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential
- Paper Link: https://www.alphaxiv.org/abs/2507.11851
First, explore a fundamental question: can language models generate multiple tokens in a single inference step?
Encouragingly, the answer is yes.
Existing speculative decoding research has explored this direction to accelerate generation. It uses a draft model to generate multiple tokens, then a verifier checks their consistency with standard autoregressive outputs. While this provides speedup, it still fundamentally relies on autoregressive generation.
In this work, researchers pose a deeper question: can we train truly non-autoregressive language models?
They explore this by designing fully non-autoregressive training algorithms, such as diffusion-based language models. However, these methods often require entirely new modeling and training processes.
Therefore, they further ask: can we adapt existing autoregressive training and inference frameworks with minimal modifications? The goal is to achieve efficient multi-token generation while preserving the core advantages of autoregressive models.
They observe that, although autoregressive models are not explicitly trained for future tokens, they implicitly encode information about upcoming tokens.
For example, given the prompt “what is two plus two?”, a pretrained model typically generates “two plus two equals four” during standard decoding. To test whether the model perceives future tokens, researchers add placeholder tokens (represented by arrows) after the prompt and analyze the output logits, as shown in Figure 1 (left).
Surprisingly, the correct sequence of future tokens appears within the top 200 logits, indicating that the model has implicitly grasped the upcoming token information.

Figure 1: Autoregressive models can implicitly predict future tokens.
Based on this observation, researchers investigate whether they can guide the model to better organize its predictions of future tokens.
They introduce several mask tokens at the end of the prompt and fine-tune the model to directly predict these tokens. As shown in Figure 1 (middle), the fine-tuned model can elevate the correct tokens into the top 10 logits.
Finally, to generate coherent multi-token outputs, they incorporate a lightweight sampling module: a two-layer perceptron that conditions each token prediction on previously sampled tokens, as shown in Figure 1 (right).
Unlike previous methods, this approach trains the model to fill mask tokens, leveraging its full depth and contextual understanding during inference, significantly outperforming existing multi-token prediction techniques.
Moreover, by applying a simple yet effective technique—gated LoRA adaptation—the method maintains no loss in generation quality.
With lightweight supervised fine-tuning, they achieve acceleration effects comparable to retraining from scratch. As shown in Figure 2, fine-tuning Tulu3-8B to predict 8 additional tokens yields substantial performance gains.
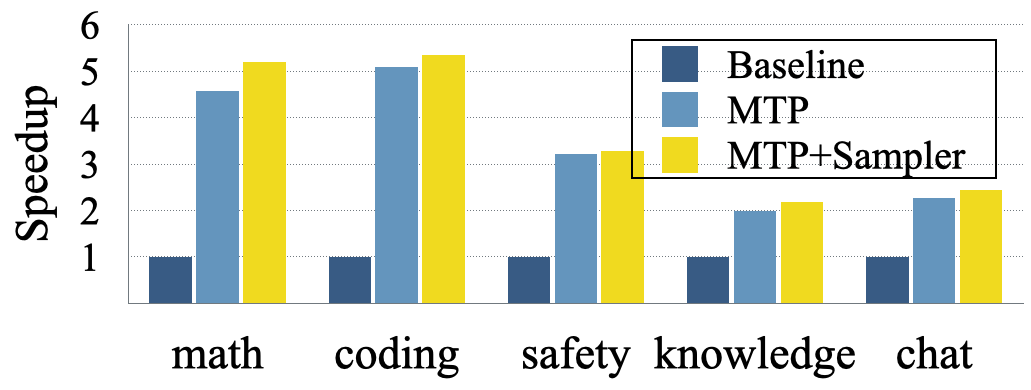
Figure 2: Acceleration achieved through supervised fine-tuning of gated LoRA and sampling head.
Methodology
To enable multi-token generation with minimal retraining, a special token called mask is introduced. Given an original sequence X = [x1, ..., xn], an extended sequence Xm = [x1, ..., xn, m1, ..., mk] is constructed by appending k unique mask tokens, initialized with random vectors and added to the embedding table.
In this framework, predicting the next token is called NTP (Next Token Prediction), while predicting mask tokens is called MTP (Mask Token Prediction).
The overall architecture of the MTP model is shown in Figure 3, where the sequence with k=2 masks is used during inference. The extended sequence Xm is input to the decoder, producing latent representations where [z1, ..., zn] correspond to NTP tokens, and [zn+1, ..., zn+k] correspond to MTP tokens.
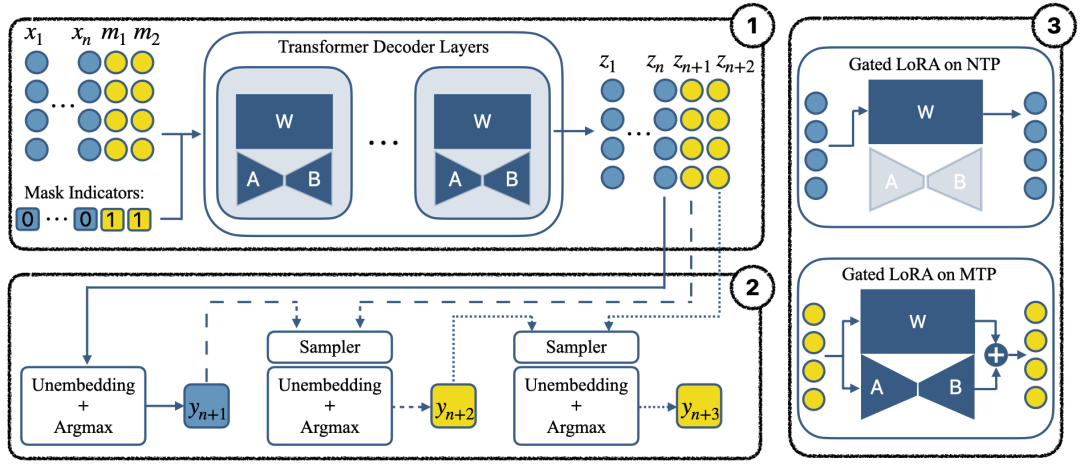
Figure 3: Components of the MTP model, including the autoregressive model with gated LoRA, the sampler head, and the gated LoRA module diagram.
The sampler head (bottom left) generates tokens sequentially. The first token (NTP) is generated via a standard unembedding layer autoregressively, predicting y_{n+1} from z_n. The remaining tokens (MTP) are generated by the sampler module, which predicts each subsequent token conditioned on previous tokens and the latent representation, ensuring effective utilization of the model’s full capacity.
To preserve the pretrained behavior during fine-tuning, researchers introduce a gated LoRA module in the decoder layer. Only LoRA parameters and the sampler head are updated, while the original decoder weights remain frozen. The gated LoRA module routes computations differently for NTP and MTP tokens, ensuring the original autoregressive behavior is maintained, as shown in the right part of Figure 3. This is achieved by an additional binary mask input to the decoder.
Details of the training process are described in the original paper.
Experiments
Researchers conducted experiments on the Tulu3-8B SFT model, part of the LLaMA-3 series, fine-tuned on the Tulu3 dataset.
Generation Quality Evaluation
They tracked the model’s accuracy during fine-tuning. Since the model is a supervised fine-tuned (SFT) model, it is sensitive to additional training. Figure 6 (a) shows zero-shot accuracy on the ARC-Challenge benchmark, evaluated via the Harness library.
As indicated by the dashed line in Figure 6 (a), gated LoRA maintains stable accuracy because it ensures the output of NTP tokens is unaffected by fine-tuning.
Figure 6 (b) shows that both standard LoRA and gated LoRA achieve effective convergence.
Next, Figure 6 (c) analyzes the cross-entropy loss on NTP tokens, directly related to generation quality. The standard LoRA model’s NTP loss increases over training, indicating declining quality, while the gated LoRA model maintains nearly constant NTP loss, as the gradient does not propagate to NTP tokens, avoiding interference with original generation capabilities.
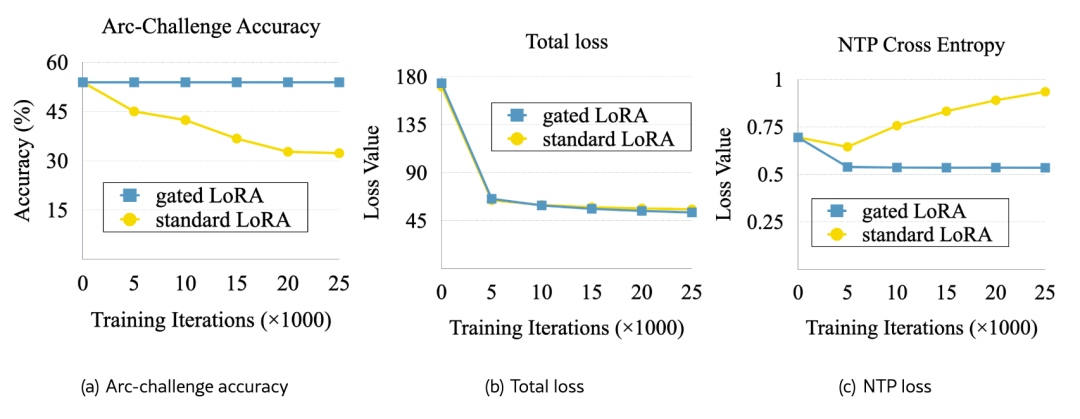
Figure 6: Convergence analysis of models trained with standard and gated LoRA adapters.
Acceleration Analysis
To evaluate the speedup, researchers used self-speculative decoding. The process terminates early if an end-of-sentence token is generated before 100 steps. The acceptance rate G/T measures how many tokens are accepted per step, reflecting the efficiency gain.
The theoretical minimum acceptance rate is 1, and the maximum is 9 (k+1=8 masks). Table 1 reports acceptance rates across five tasks: knowledge Q&A, math, programming, dialogue, and safety.
Results show the proposed multi-token generation method achieves approximately 1.5 to 5.2 times acceleration, especially in programming and math tasks where future token predictability is higher.
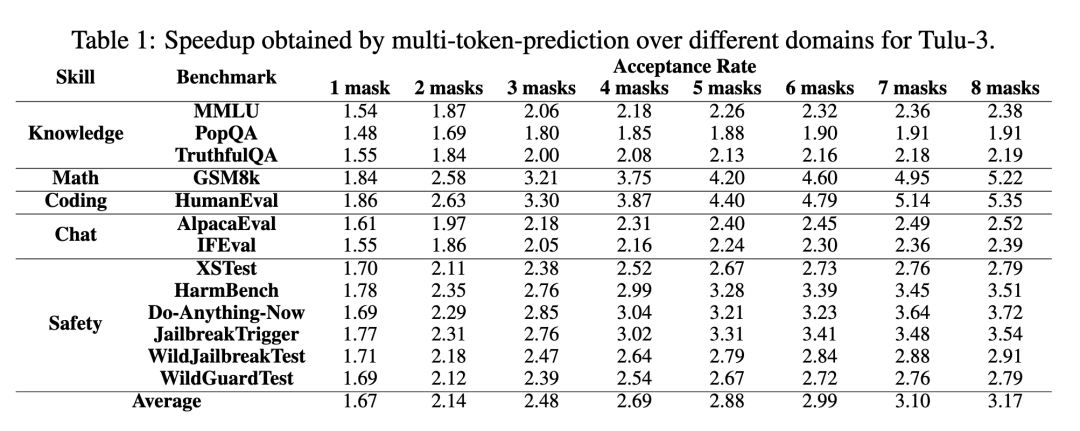
Table 1: Speedup factors across different domains using multi-token prediction.
Ablation Studies
The results above are based on the optimal configuration, which includes three key components:
(1) Sampler MLP head;
(2) LCM loss during training;
(3) Quadratic decoding during inference.
Further ablation experiments evaluate each component’s contribution.
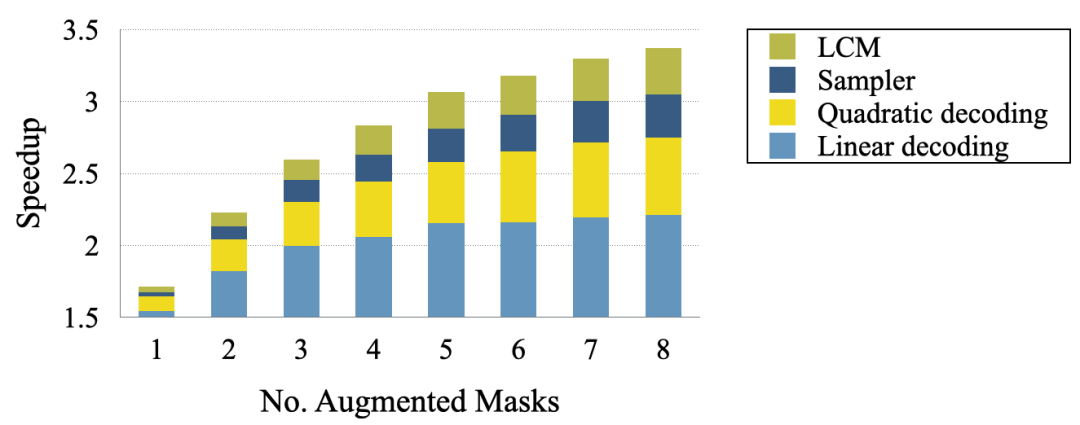
Figure 7: Performance comparison of basic and advanced configurations of the MTP model, including LCM loss, sampling head, and quadratic decoding.
Researchers trained models with different LoRA ranks to explore their effects. Figure 8 summarizes the results: the left and middle show acceptance rates without and with the sampler head, respectively; the right shows the memory overhead of LoRA and the sampler head.
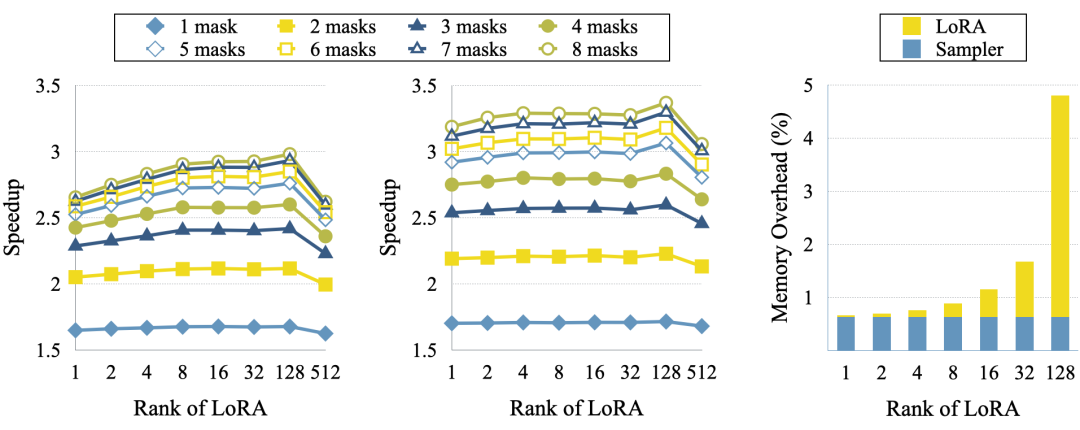
Figure 8: Impact of LoRA rank on acceleration and memory usage, with and without sampler head.
Summary
This work systematically evaluates the adaptation of autoregressive models for multi-token prediction tasks. Future directions include incorporating this method during pretraining or downstream adaptation, and exploring diffusion-based generation methods, which balance efficiency and quality between autoregressive and diffusion models.
For more details, please refer to the original paper.