Farewell to Transformers! Peking University, Beijing University of Posts and Telecommunications, and Huawei Open-Source Pure Convolutional DiC: 3x3 Convolution Achieves SOTA Performance, 5x Faster Than DiT}
Researchers from Peking University, Beijing University of Posts and Telecommunications, and Huawei developed DiC, a pure convolution diffusion model that surpasses DiT in performance and is five times faster.

When the entire AI visual generation field is dominated by Transformer architectures, a recent study from Peking University, Beijing University of Posts and Telecommunications, and Huawei takes a different approach by re-examining the fundamental and classic module—3x3 convolution.
Their proposed DiC (Diffusion CNN), a purely convolutional diffusion model, not only outperforms the popular Diffusion Transformer (DiT) in performance but also achieves an astonishing speed-up in inference. This work demonstrates that, with careful design, simple convolutional networks can still reach the pinnacle in generative tasks.

Introduction
From Stable Diffusion to Sora, diffusion models based on Transformer architectures have become the mainstream in AI-generated content (AIGC). Their powerful scalability and excellent quality come with high computational costs and slow inference, becoming bottlenecks in practical applications.
Is it necessary to follow the Transformer path to the end?
This paper provides a definitive answer: no. The researchers boldly abandon complex self-attention mechanisms and return to the purest form—3x3 convolution—and build a new diffusion architecture that balances speed and performance—DiC.
Why Choose 3x3 Convolution?
Supported by AI hardware and frameworks like cuDNN, 3x3 convolution is one of the most optimized operators, benefiting from algorithms like Winograd that significantly accelerate computation, making high throughput possible.
However, 3x3 convolution has a critical weakness: limited receptive field. This makes it inherently weaker than Transformers in tasks requiring global information, which was previously believed to be the key to large-scale generative models.
The authors of DiC challenge this conventional wisdom.
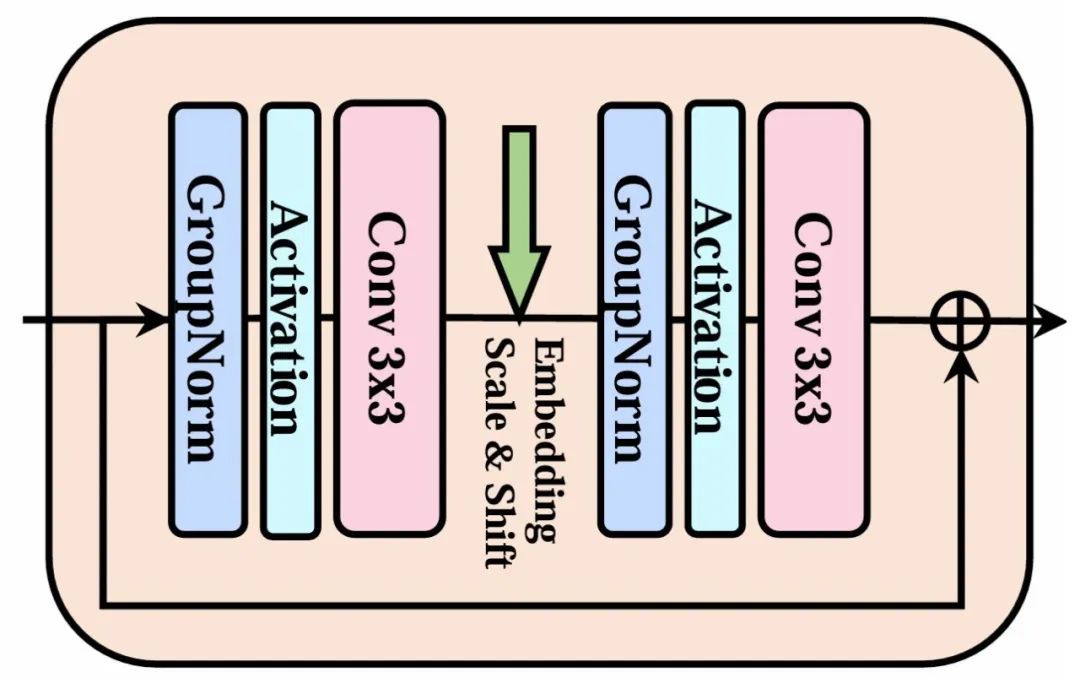
The basic modules of DiC mainly consist of two Conv3x3 layers.
Evolution of DiC: From Mediocre to Outstanding
The researchers did not simply stack convolution layers. Instead, through a series of clever designs, they transformed a mediocre convolution network into a performance monster. The roadmap of this process is clearly illustrated in the paper:
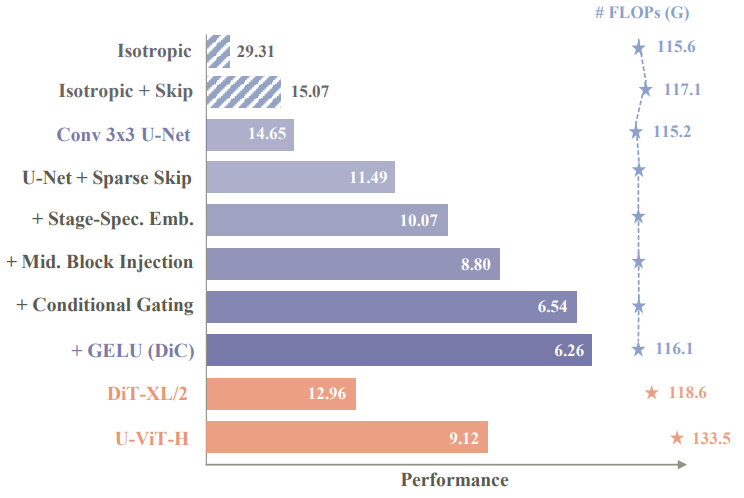
Architecture Choice: U-Net Hourglass is Key
It was found that for pure convolution models, the traditional U-Net hourglass architecture is more effective than the common straight stack of Transformers. Through encoder down-sampling and decoder up-sampling, the model can cover larger areas of the original image with the same 3x3 kernels, effectively compensating for the limited receptive field. On this basis, DiC reduces the frequency of skip connections, lowering computational redundancy.
Conditional Injection for Better Response
To make the model respond more accurately to conditions (like class labels or text), DiC employs a sophisticated “triple attack” optimization: first, stage-specific embeddings provide dedicated, dimension-matched condition embeddings at different layers; second, optimal injection points are experimentally determined, with condition information intervening at mid-layer convolution blocks; third, a conditional gating mechanism dynamically scales feature maps for finer control of the generation process. This combination greatly enhances the quality of generated images.
Activation Function Replacement
Replacing the common SiLU with GELU yields some performance improvements.
Impressive Results: Both Performance and Speed
Outperforming DiT, with Better Results
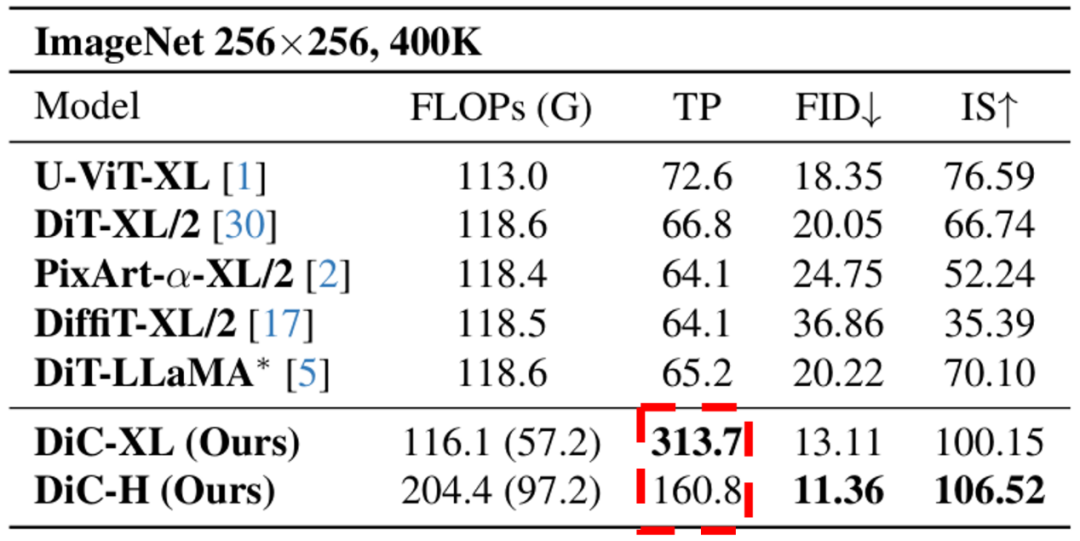
At equal FLOPs and parameter scale, DiC significantly outperforms DiT across all sizes. For example, the XL version of DiC reduces FID scores from 20 (DiT-XL/2) to 13, and improves Inception Score (IS), indicating higher quality and diversity of generated images.
DiC’s generation ability is already impressive, but its speed advantage is even more disruptive. Thanks to its fully convolutional architecture, DiC’s inference throughput far exceeds that of Transformer models. For instance, at the same parameter and compute level, DiC-XL achieves a throughput of 313.7, nearly 5 times that of DiT-XL/2 (66.8)!
Scaling Law Exploration
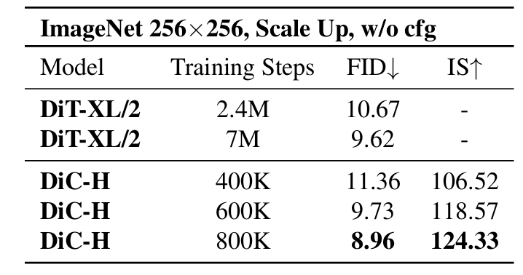
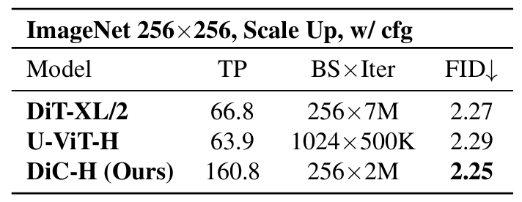
The researchers explored the upper limits of DiC’s image generation capabilities, finding rapid convergence. Without classifier-free guidance (cfg), DiC converges ten times faster than DiT under the same settings; with cfg, FID can reach as low as 2.25.
DiC produces outstanding results with highly realistic outputs
Exploration of Scaling Laws
DiC challenges the notion that “generative models must rely on self-attention.” It demonstrates that, through deep understanding and clever architecture design, simple and efficient convolutional networks can build powerful generative models. Convolution still has vast potential in visual AIGC!
Paper accepted at CVPR 2025. For more details, see the original paper.