Elon Musk Unveils Grok 4! Tops All Rankings with Over $20,000 Annual Fee}
Grok 4, the latest AI model from xAI, surpasses all benchmarks, achieving human-level performance across disciplines, with an annual fee exceeding $20,000, marking a new era in AI development.

All subjects are at a postdoctoral level.
After long anticipation, the next-generation large model from xAI—Grok 4—has finally been released! Its capabilities are beyond our imagination.
At around noon Beijing time today, the highly awaited xAI launch event began. Elon Musk appeared live, saying: "This is the best AI in the world. Let’s show you."

Elon Musk stated that Grok 4 can score full marks on the SAT (U.S. college entrance exam) without seeing the questions beforehand. It can also approach perfect scores in GRE across all disciplines, surpassing all graduate-level standards worldwide. Its strongest feature is its reasoning ability, which has already exceeded human levels.
Musk believes Grok 4 could achieve scientific breakthroughs within this year.

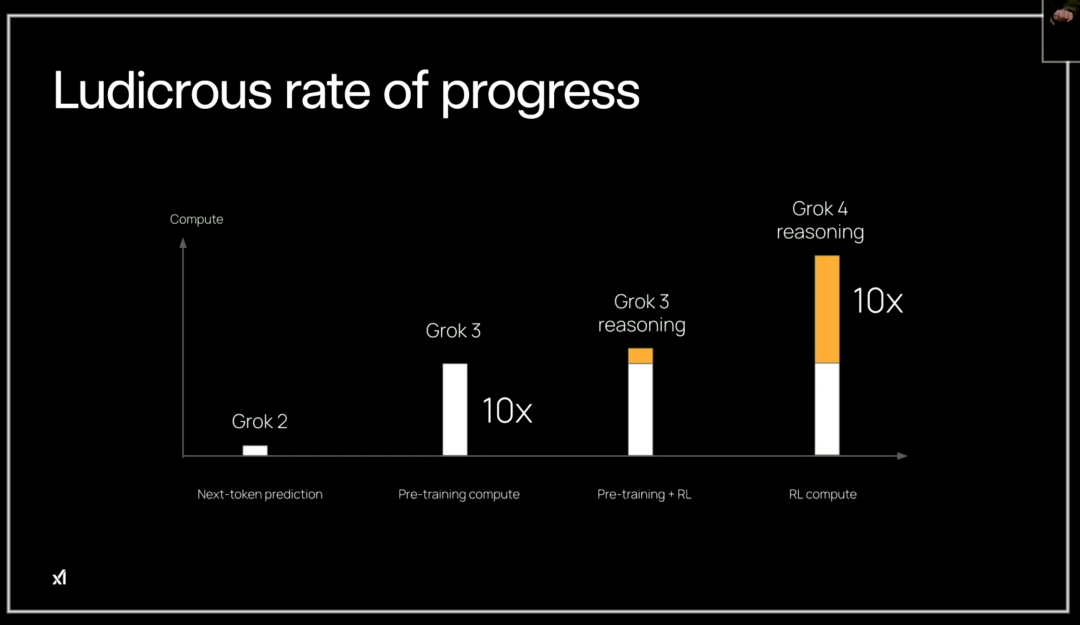
Thanks to enhanced computational power and reinforcement learning training, Grok 4’s reasoning ability has improved tenfold compared to previous versions. From Grok 2 to Grok 4, different technological paradigms were used: next token prediction, pretraining computation, pretraining + RL, and RL computation.
Specifically, the pretraining computation increased tenfold from Grok 2 to Grok 3, with reasoning capabilities first introduced via RL fine-tuning. The reasoning power of Grok 4 has been further boosted by another tenfold increase in computation, indicating a significant leap in reasoning ability.
Additionally, with improved tool invocation capabilities, Grok 4 has further amplified its intelligence, achieving performance far beyond SOTA on various challenging benchmarks.
Next, let’s look at Grok 4’s benchmark results.
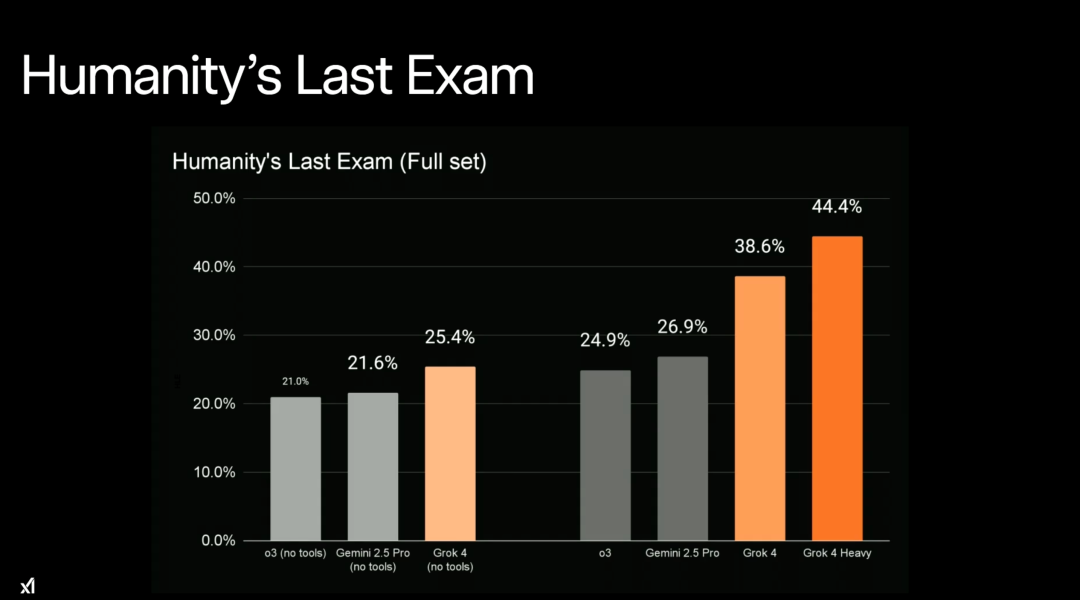
First is HLE (Humanities Last Exam), including math, chemistry, and logic. In the leaked results from last Saturday, Grok 4 scored 35% on HLE, which increased to 45% with reasoning techniques, though many netizens remain skeptical.
During today’s live broadcast, xAI researchers said that previous SOTA models with tool use could reach a maximum of 41.0%.
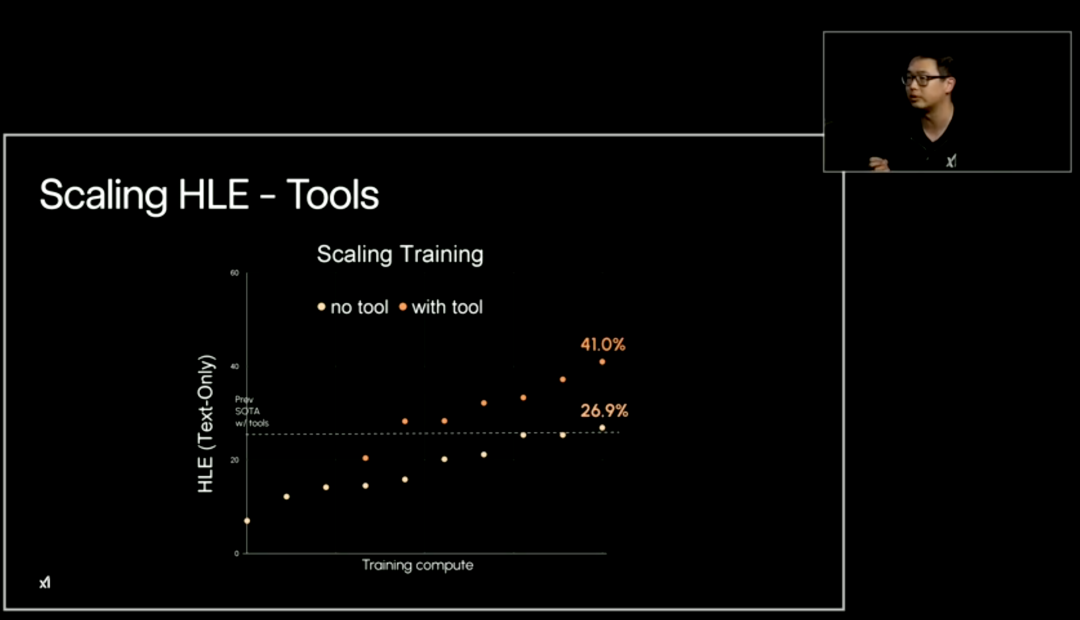
Now, Grok 4 has further improved this benchmark.
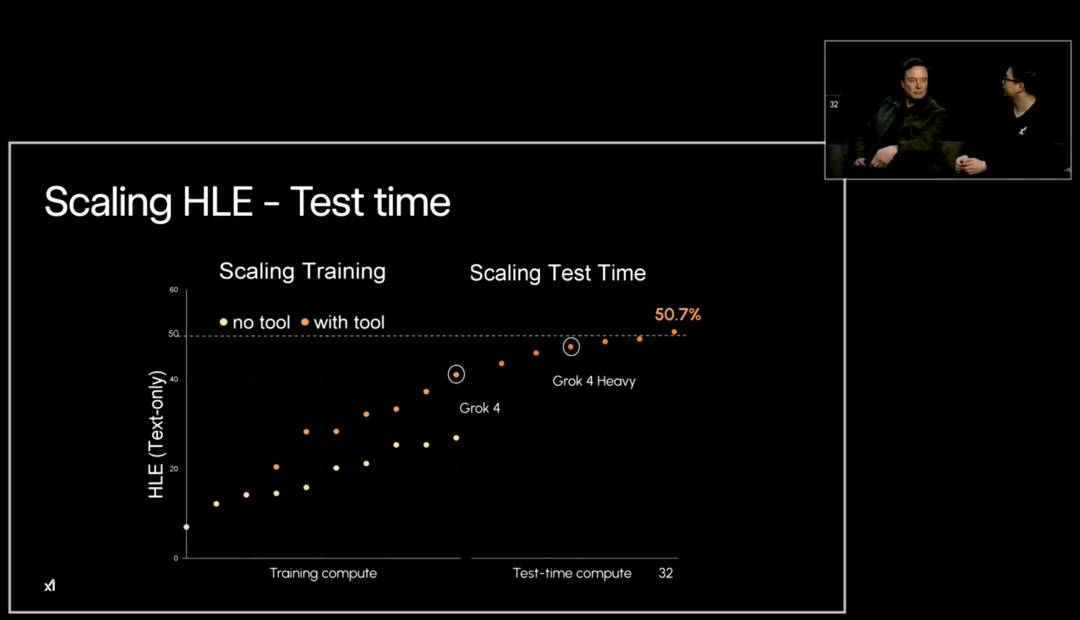
Specifically, compared to other SOTA models (o3, Gemini 2.5 Pro), Grok 4’s score with tool use is 38.6%, and Grok 4 Heavy’s score skyrocketed to 44.4%. If the model spends more time thinking and uses more external tools during testing, the HLE score can further rise to 50.7%.
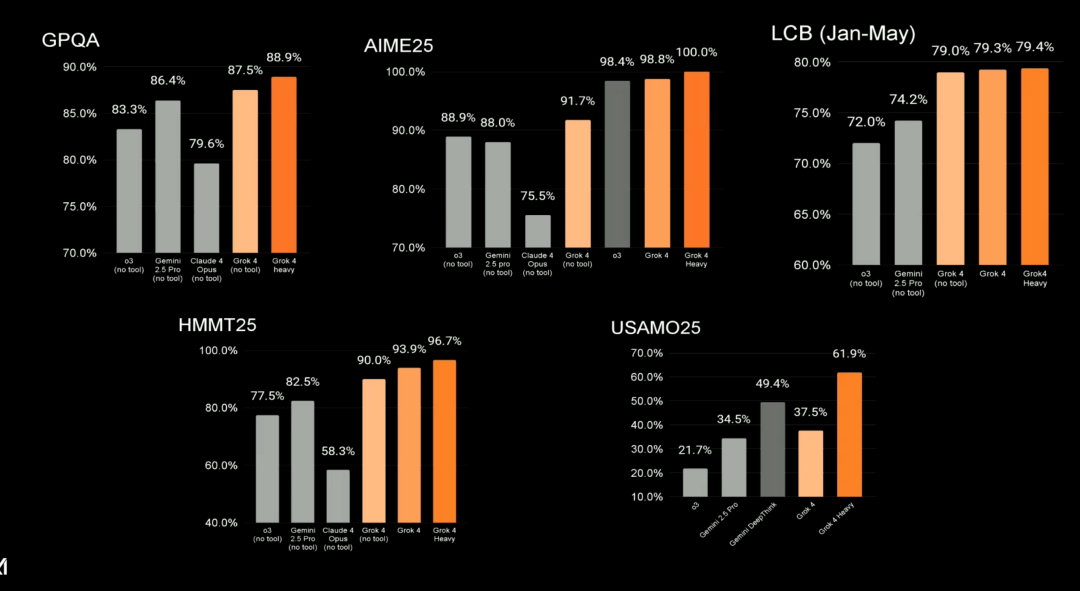
Regarding other benchmarks, including GPQA (graduate-level Google verification Q&A), AIME25 (U.S. math competition), LCB (Jan-May, programming/algorithm contests), HMMT25 (high school math team), and USAMO25 (top U.S. high school math), Grok 4 Heavy has achieved the latest SOTA results across the board.
Compared to humans, who can hardly answer these questions, Musk repeatedly emphasizes: “Grok now reaches postdoctoral levels in all subjects, with no exceptions.” It has not yet discovered new science or physical laws, but that’s only a matter of time.
“If Grok doesn’t discover practical new scientific or technological breakthroughs this year, I’d be surprised,” Musk said.
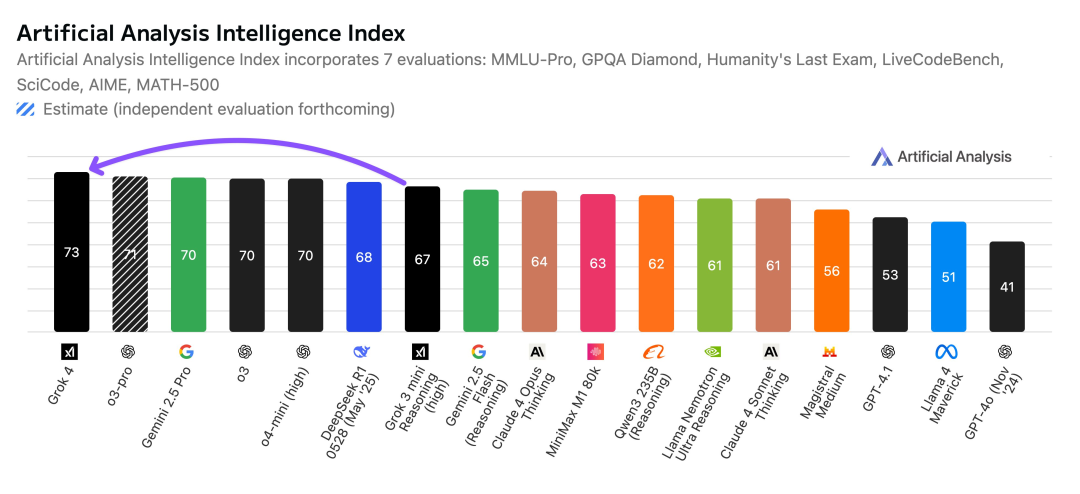
According to the comprehensive benchmark platform Artificial Analysis, Grok 4 has become the leading AI model with a total score of 73, surpassing models like o3, Gemini 2.5 Pro, Claude 4 Opus, and DeepSeek R1 0528.

Imagine the current position: we are in the midst of an unprecedented explosion of AI development. It’s time to see what Grok 4 can do.
Let’s look at a couple of demos, such as “HTML animation based on physical principles, simulating two black holes colliding and producing gravitational waves in a 30-second visualization”:
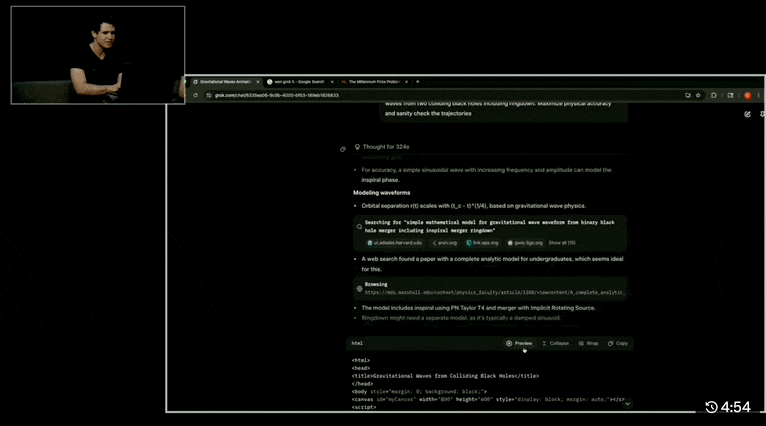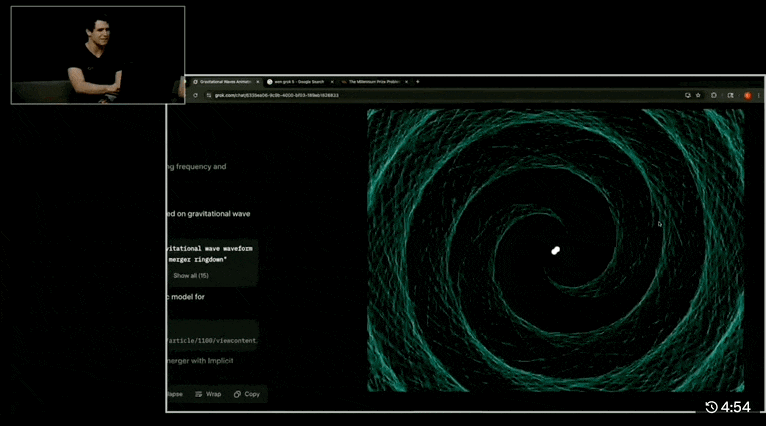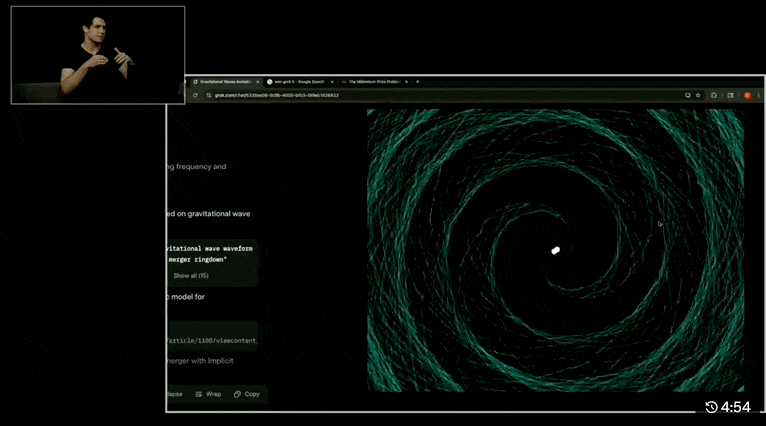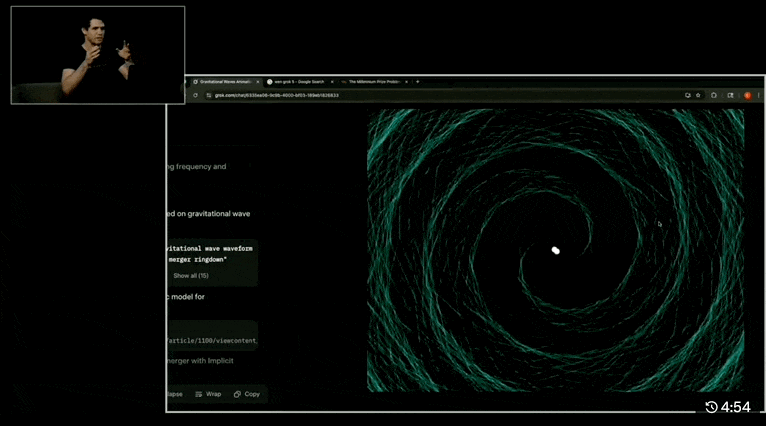
Grok 4 almost perfectly reproduces the gravitational wave simulation from two approaching black holes to their final merger. The GIF shows the reasoning process, calculation steps, and links to the referenced papers.
Grok 4’s versatility is even stronger now
Besides improvements in language benchmarks, Grok 4 has also been enhanced in other aspects.
Its speech capabilities are twice as fast as the previous generation, with lower latency; it supports five languages; and daily user engagement has increased tenfold.

The new Grok characters Eve and Sal are now available on the iOS version. Sal supports multiple personalities, while Eve can sing and whisper.

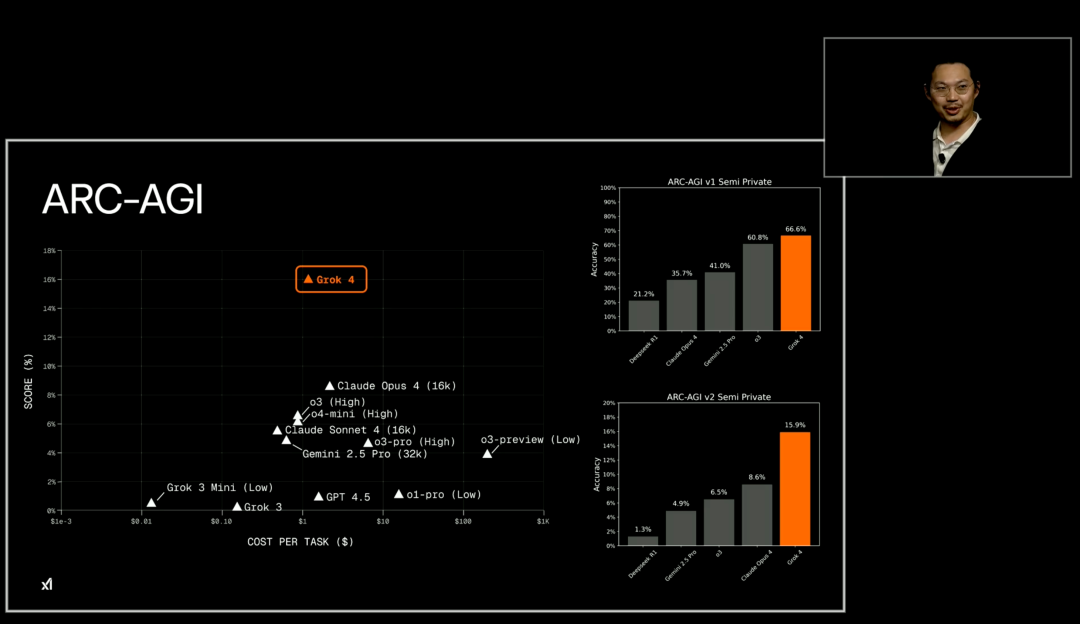
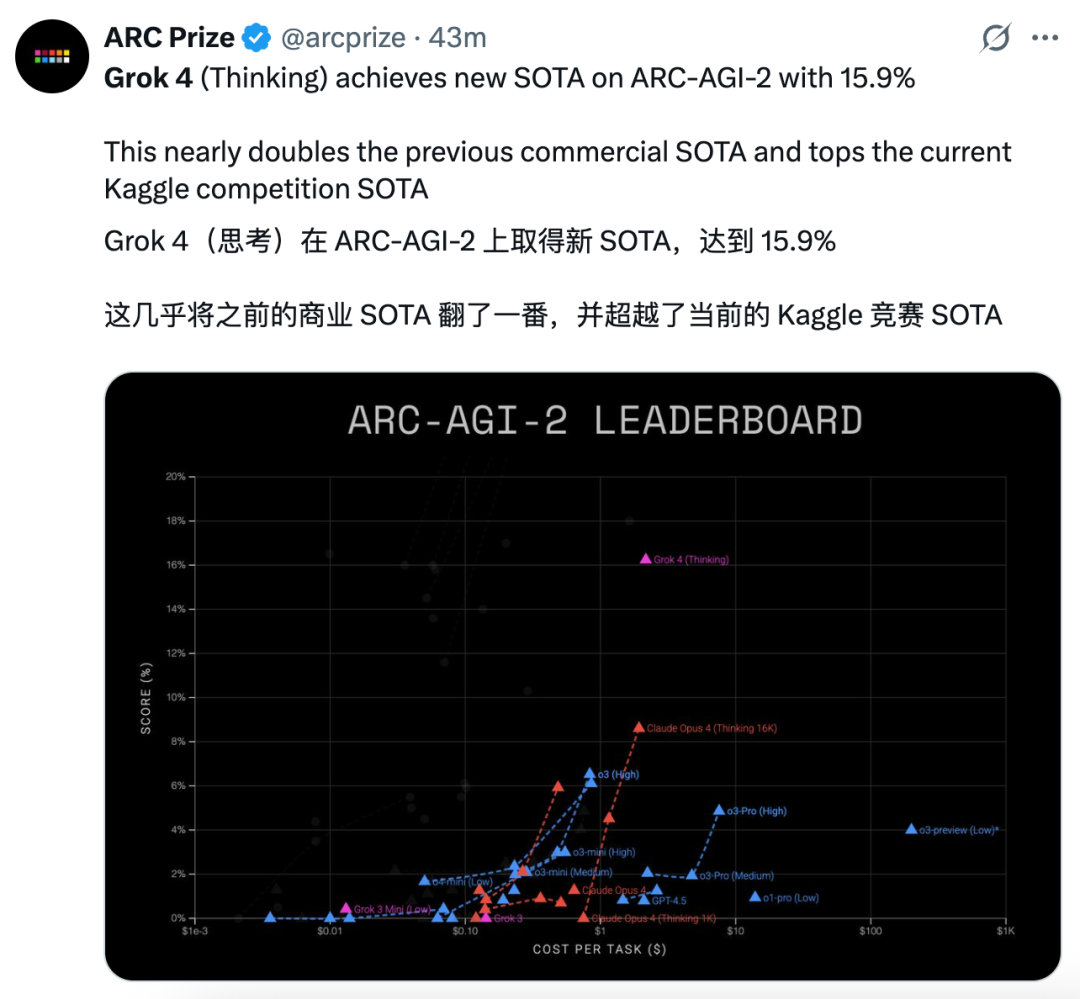
In the ARC-AGI benchmark set, designed to evaluate general reasoning ability, Grok 4 achieved a new SOTA of 15.9% on ARC-AGI-2, nearly doubling the previous best and surpassing current Kaggle competition SOTA.
In the Vending-Bench benchmark, which assesses an agent’s ability to perform complex real-world tasks and address the Sim2Real gap, Grok 4 outperforms models like Claude Opus 4, Human, Gemini 2.5 Pro, and o3.

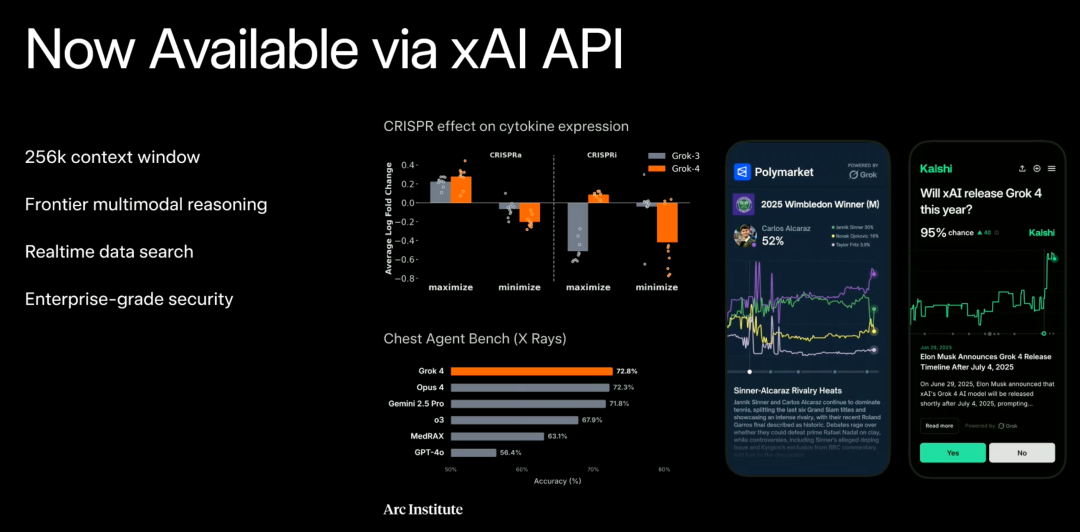
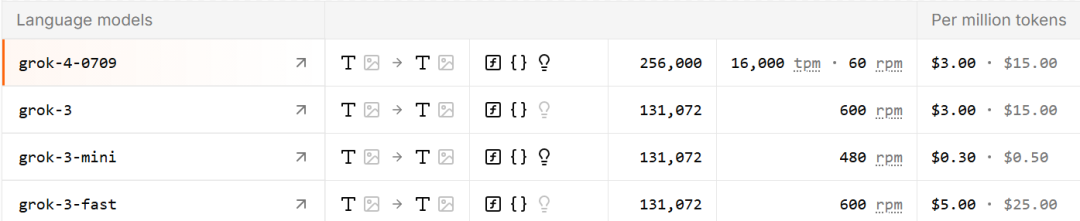
Grok 4 can be accessed via API, offering a 256K token context window. The current version, grok-4-0709, is available for use at the same price as Grok 3.
- Official website: https://grok.com/