Counterintuitive AI Programming Research Draws 3 Million Views! Developers Expect 20% Speedup but Experience 19% Slowdown}
A recent study reveals that AI programming tools unexpectedly slow down experienced developers, challenging assumptions and sparking widespread discussion online.


With the rise of large models, AI programming is undergoing revolutionary changes.
Various coding large models and tools have emerged, offering features like auto-completion and debugging, greatly easing developers' daily work and improving efficiency to some extent.
But the question remains: Are these tools truly effective?
Recently, a non-profit AI research organization, METR, conducted a randomized controlled experiment to understand how AI programming tools impact the productivity of experienced open-source developers.
The results were surprising: Developers believed that using AI tools would boost their speed by 20%, but in reality, their speed decreased by 19% compared to not using AI tools. This conclusion went viral on social media platform X, with nearly 3 million views.

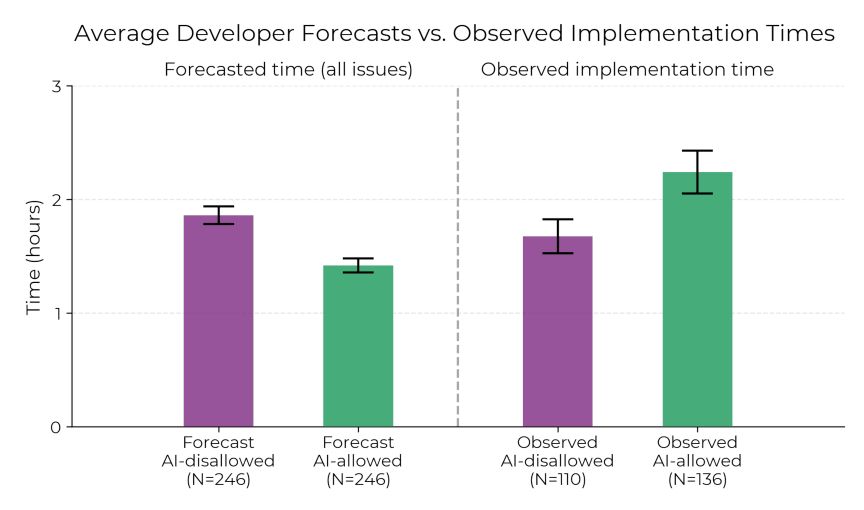
As shown below: Contrary to experts' predictions and developers' intuition, early 2025 AI programming tools will slow down experienced developers. In this RCT, 16 developers with about 5 years of experience completed 246 complex projects.

Reactions on social media vary. Some resonate with the findings, expressing agreement.

Others question METR's measurement metrics, arguing that "task completion time" does not equate to "productivity," and that testing with moderate AI experience on complex projects is a poor setup.

Some suggest it would be better to study how much faster ordinary people (non-developers) can write software with AI.
Research Motivation
While coding/AI benchmarks help understand AI capabilities, they often sacrifice realism for scale and efficiency—these tasks are isolated, do not require understanding prior context, and are evaluated algorithmically, which may overestimate AI abilities.
Since benchmarks run without real-time human interaction, models may make progress but fail in real scenarios, such as small bottlenecks easily fixed by humans. Converting benchmark scores directly to real-world impact is challenging.
METR argues that evaluating AI's impact on developer productivity can supplement benchmarks, providing a more comprehensive understanding of AI's overall influence on research acceleration.
Methods, Results, and Analysis
To directly measure AI tools' real-world impact, METR recruited 16 experienced developers from large open-source repositories (average 22k+ stars, 1 million+ lines of code, with years of contribution).
They provided a list of 246 real problems relevant to their repositories—bug fixes, feature development, and refactoring tasks.
Problems were randomly assigned, with developers either allowed or prohibited from using AI tools (mainly Cursor Pro with Claude 3.5/3.7 Sonnet). Developers recorded their time and reported completion durations.
Participants were paid $150/hour (~1080 RMB).

The results showed that when AI tools were allowed, developers took 19% longer to solve problems—contradicting expert predictions and their own perceptions.
Developers expected AI to speed them up by 24%, and even after experiencing slower performance, still believed AI could boost their speed by 20%.
Below are the predicted vs. actual times: when AI was permitted, developers spent significantly more time.
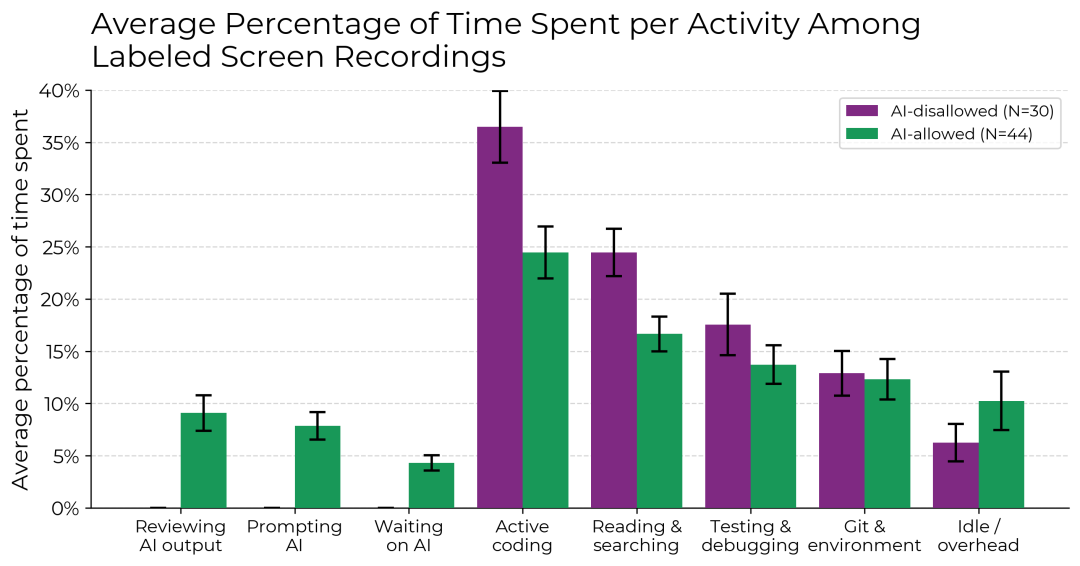
Allowing AI reduced active coding and info searching time but increased time spent on prompt writing, waiting, reviewing AI outputs, and idling. Multiple factors contributed to the slowdown.
METR examined 20 attributes in the environment, identifying 5 likely causing the slowdown and 8 with mixed or unclear effects.
Despite controlling for confounding factors like using cutting-edge models, following rules, and consistent PR submissions, the slowdown persisted across various metrics and analyses.
More detailed results are available in the original paper: https://metr.org/Early_2025_AI_Experienced_OS_Devs_Study.pdf
Limitations and Future Outlook
The study concludes two key points:
- In some scenarios, recent AI tools may not improve productivity and could even reduce efficiency.
- Self-reported productivity gains are unreliable; real environment experiments are necessary for accurate assessment.
METR notes their setup does not represent all (or most) software engineering contexts, but current models can be better utilized, and future models may perform even better.
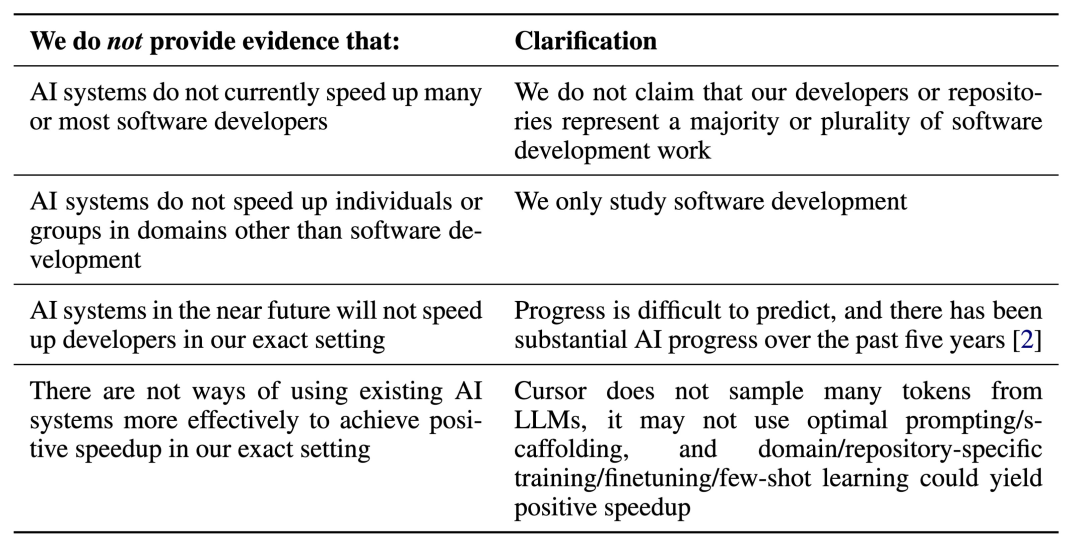
Of course, no measurement method is perfect—tasks are diverse and complex, and evaluation involves trade-offs. Developing diverse assessment methods remains crucial for understanding AI's current and future capabilities.
METR plans to continue similar research to track AI's acceleration or slowdown trends, which may be harder to manipulate than benchmark scores.
Blog post: https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/