ByteDance's Astra Dual-Model Architecture Empowers Robot Navigation: 'Where Am I? Where To Go? How To Get There?'}
ByteDance introduces Astra, a dual-model architecture for robot navigation, tackling core challenges with innovative multimodal models, promising safer and more efficient indoor navigation.


In today's rapidly advancing technological era, robots are increasingly integrated into various fields, from industrial production to daily life. However, modern navigation systems face significant challenges in complex indoor environments, with traditional methods showing limitations.
1. Traditional Navigation Bottlenecks and the Birth of Astra
In real-world scenarios, mobile robots must address three core questions: Where am I?, Where am I going?, and How do I get there?
—the key issues of target localization, self-positioning, and path planning. Target localization may involve natural language or image prompts, requiring systems to understand and locate targets on maps. Self-positioning demands accurate localization within maps, especially in repetitive, landmark-scarce environments like warehouses, often relying on manual markers like QR codes. Path planning involves global route generation and local obstacle avoidance.
Traditional systems typically consist of multiple modules or rule-based systems. Recent advances in foundation models have led to integrating smaller models into larger ones, but effective integration remains a challenge.
To overcome these bottlenecks, ByteDance has developed an innovative dual-model architecture called Astra.
- Paper Title: Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
- Website: https://astra-mobility.github.io/
By employing two sub-models—Astra-Global and Astra-Local—the system bridges environment understanding and real-time planning, laying the foundation for next-generation intelligent navigation. Astra follows the System 1/System 2 paradigm: Astra-Global handles low-frequency tasks like target and self-localization; Astra-Local manages high-frequency tasks such as local path planning and odometry estimation. This architecture offers new hope for indoor robot navigation, potentially transforming how robots operate in complex environments.
图1: Astra模型概述
2. Astra双模型架构揭秘,赋能机器人高效导航
1. Astra-Global:全局定位的智慧大脑
Astra-Global acts as the 'brain' of Astra, responsible for low-frequency tasks such as self-localization and target localization. It is a multimodal large language model (MLLM) capable of processing visual and language inputs to achieve precise global localization. It uses a hybrid topological semantic graph as context, enabling accurate position identification based on query images or text prompts.
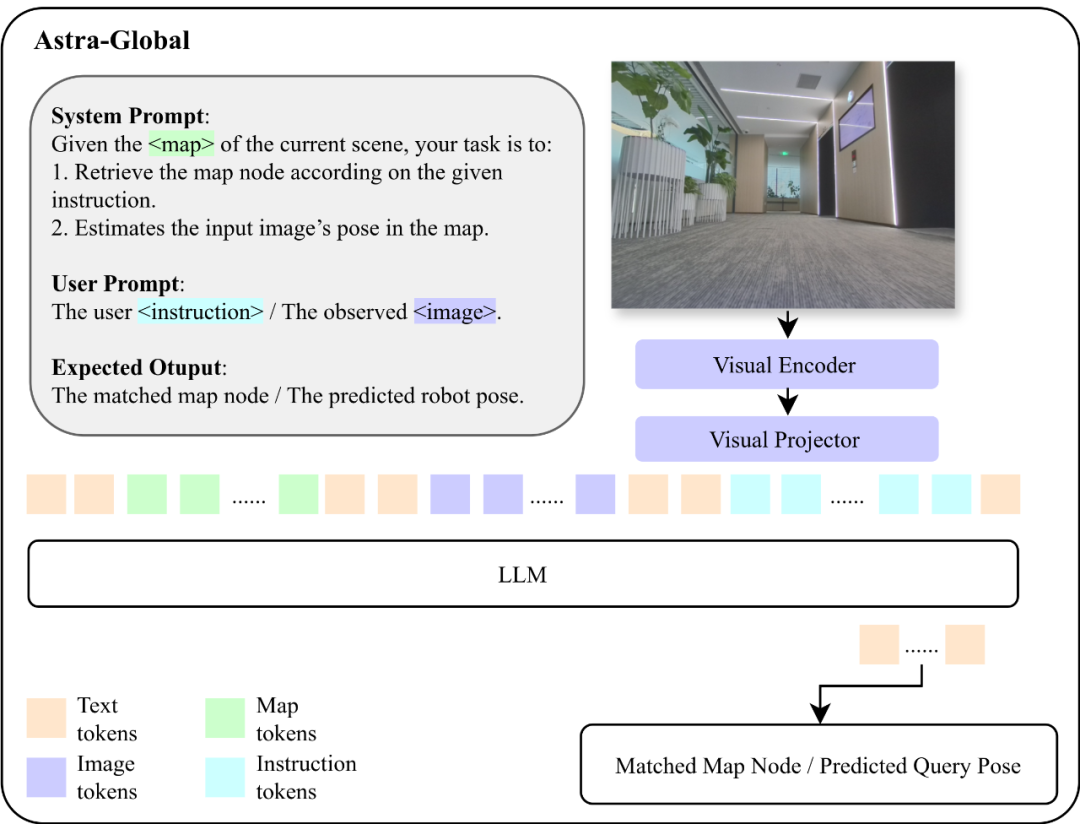
Constructing this robust localization system involves offline mapping. The team proposed a method to build a hybrid topological semantic graph G=(V, E, L), where V represents nodes (keyframes sampled from video with SfM-estimated camera poses), E encodes geometric connectivity, and L stores semantic landmarks extracted from visual data. This map captures scene structure and semantic attributes, such as 'conference room' or 'office area,' enabling accurate and robust localization even with viewpoint changes.
During localization, Astra-Global performs a two-stage process: coarse localization by matching input images and prompts to the map, filtering by visual similarity; then, fine localization by sampling candidate nodes and estimating precise pose via comparison, such as identifying a 'printer' in a scene based on natural language commands.
Training Astra-Global involves supervised fine-tuning (SFT) and rule-based optimization (GRPO). SFT uses diverse datasets for coarse and fine localization, while GRPO employs reward functions based on format, landmark extraction, map matching, and additional landmarks, significantly improving zero-shot generalization, achieving 99.9% accuracy in unseen environments.
2. Astra-Local:本地规划的智能助手
Astra-Local handles high-frequency tasks like local path planning and odometry estimation. It includes a 4D spatiotemporal encoder, a planning head, and an odometry head. The 4D encoder replaces traditional perception modules, encoding environment states from multiple views using ViT and Lift-Splat-Shoot, trained via self-supervised learning with pseudo-depth labels.
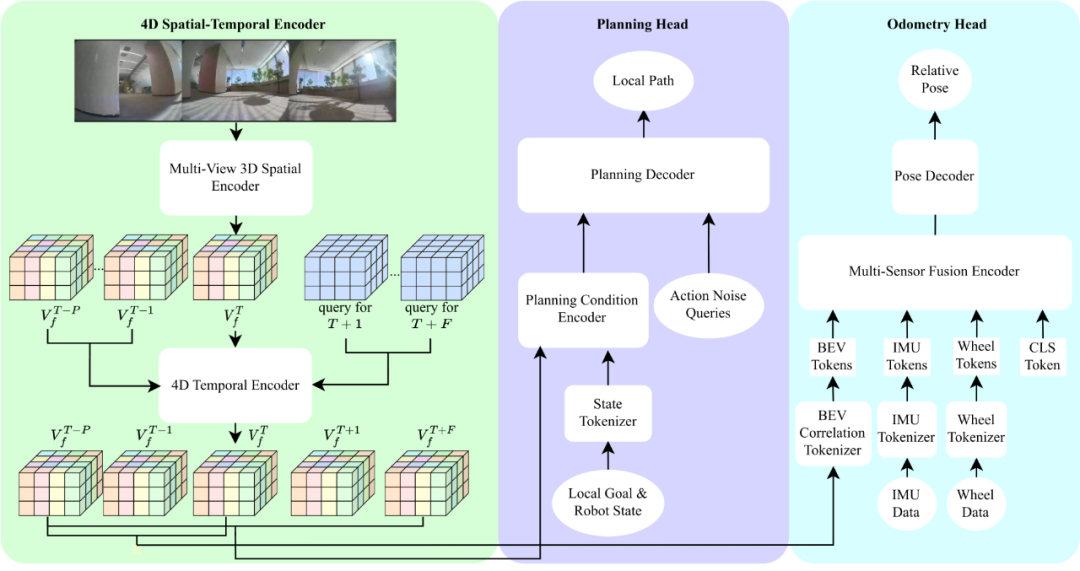
The planning head generates trajectories based on the environment features and task goals, using transformer-based flow matching and mask ESDF loss to avoid obstacles. The odometry head fuses sensor data (IMU, wheel encoders) with environment features for accurate pose estimation, achieving about 2% trajectory error with multi-sensor fusion.

图5: 通过掩码esdf loss可以显著降低规划头的碰撞率
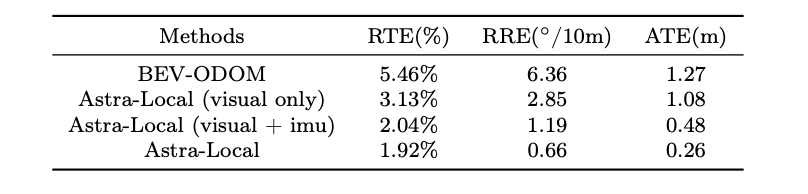
图6: 里程计任务头通过transformer有效的融合多传感器信息
3. 未来展望
Astra has broad prospects for deployment in more complex indoor environments like malls, hospitals, and libraries, assisting with navigation, logistics, and customer service. Future work includes improving map representations, active exploration, and integrating natural language commands for more natural human-robot interaction.
In local navigation, enhancing robustness against out-of-distribution scenarios and integrating instruction-following capabilities are key future directions to make robots more adaptable and user-friendly.