Breaking: Grok4 Benchmark Scores Leak — Achieves 45% on 'Humanity’s Last Exam', Twice Gemini 2.5, but Skepticism Remains}
Grok4 reportedly scores 45% on Humanity’s Last Exam, double Gemini 2.5’s, sparking debate over authenticity amid skepticism about the leaked results and model capabilities at ICCV 2025.

Did Elon Musk’s late-night tent work? With such high scores, why isn’t Grok4 officially released yet?
Recently, benchmark results for Grok4 and Grok4 Code have allegedly leaked.
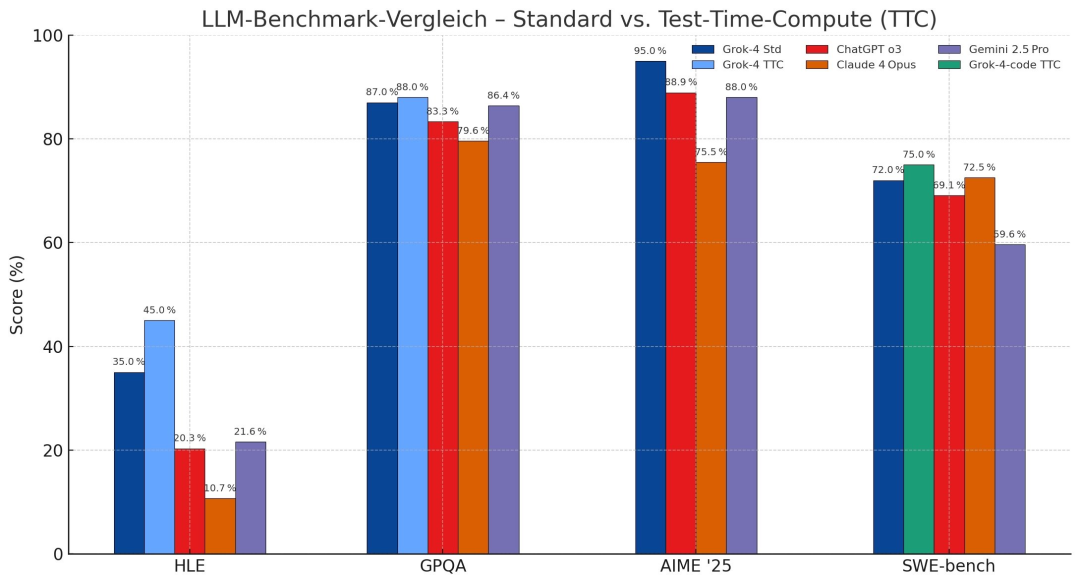
Tech blogger @legit_api posted that Grok4 scored 35% on HLE (Humanities Last Exam), which increased to 45% with reasoning techniques; on GPQA, it scored 87-88%; Grok4 Code scored 72-75% on SWEBench.

What does this score mean? Some netizens compared it with models like OpenAI o3 and Claude Opus 4.
Grok4’s 45% on HLE is nearly twice the performance of Gemini 2.5 Pro. Since HLE is a free-response test with a random guess accuracy of about 5%, each percentage point increase is extremely difficult.
On GPQA (graduate-level physics and astronomy questions), Grok4 scored 87-88%, comparable to OpenAI o3 and significantly surpassing Claude 4 (~75%).
In AIME ’25 (2025 US Math Olympiad), Grok4 scored 95%, far exceeding Claude 4’s 34% and slightly outperforming OpenAI o3’s 80-90% depending on reasoning mode. Additionally, Grok4 Code scored 72-75% on SWEBench, close to Claude Opus 4’s 72.5%, and slightly above OpenAI o3’s 71.7%. On Terminal-Bench, Claude 4 Opus leads with 43%, while xAI has not yet released Grok4 data.
The most discussed point is Grok4’s 45% on HLE, nearly twice Gemini 2.5 Pro’s score. If the leak is genuine, it indicates Grok4 has passed one of the toughest AI benchmarks.
Some suggest paying attention to the “standard” scores, considering these are benchmarks for open models, and inference scores might involve experimental configurations.
Others express skepticism, doubting Grok4’s 45% HLE score, suspecting issues with the results.

The reason given is that previous reports from xAI showed results for other models with a single attempt, but Grok4’s report used a different method.

Replying, @legit_api confirmed these scores are real, but the configurations are unknown.

Some conclude that aside from HLE, other leaked scores seem reasonable. But how to explain Grok4’s exceptionally high HLE score, given the complexity of the benchmark’s information retrieval?
Perhaps we must wait for the official release for definitive answers.
Back on July 1, foreign media TestingCatalog leaked that Grok4 and Grok4 Code details appeared on xAI’s developer console website, including the flagship Grok4 and programming-focused Grok4 Code.
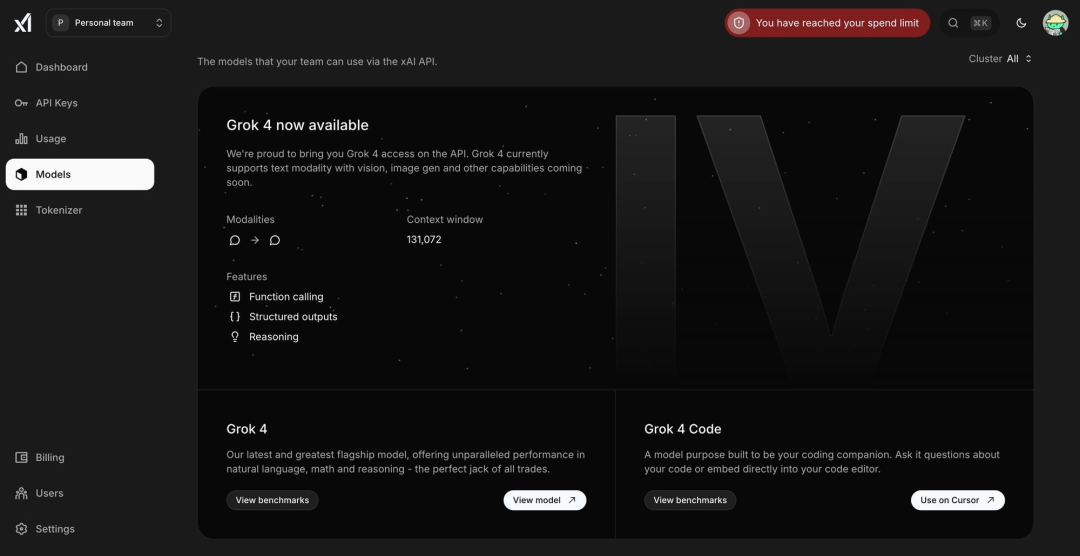
Screenshot shows Grok4 supports only text mode, with vision and image generation features coming soon. It has a context window of about 130,000 tokens, smaller than many cutting-edge competitors, indicating a focus on inference speed and real-time usability rather than maximum context length. It will include function calls, structured outputs, and reasoning capabilities.
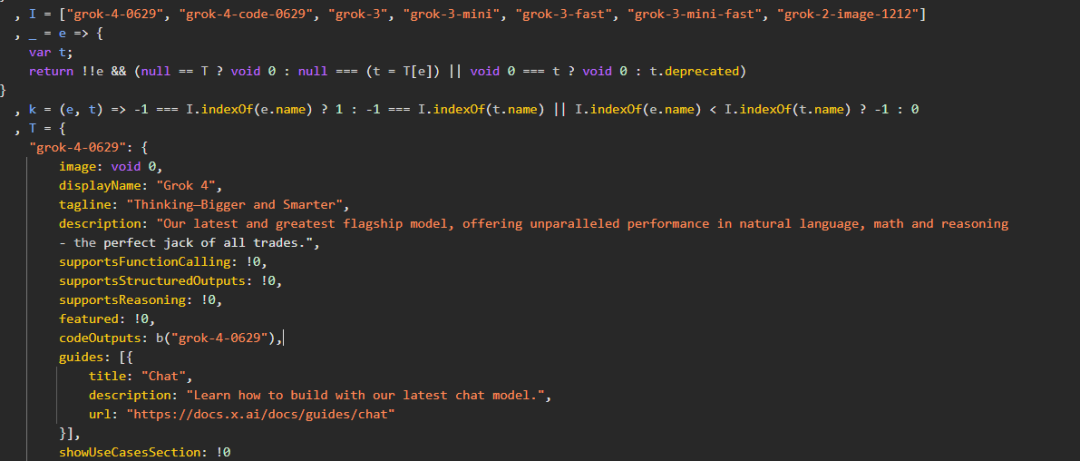
Additionally, some users found source code from xAI’s developer console, revealing Grok4 as a versatile generalist model excelling in natural language, math, and reasoning, trained on June 29 with the slogan “Think Bigger and Smarter.”
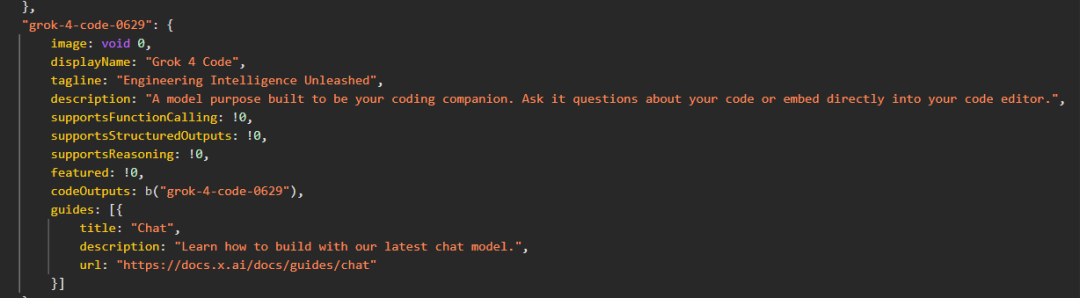
It also shows Grok4 Code as a dedicated programming model, allowing direct code questions and integration into code editors.
Last week, Elon Musk tweeted that he was “working overnight on Grok 4,” with progress “going well,” but still needing a “final large-scale training,” especially for the coding model. To this end, Musk led efforts to set up tents in the office to work around the clock.
Engineers from xAI responded to the tent rumors.
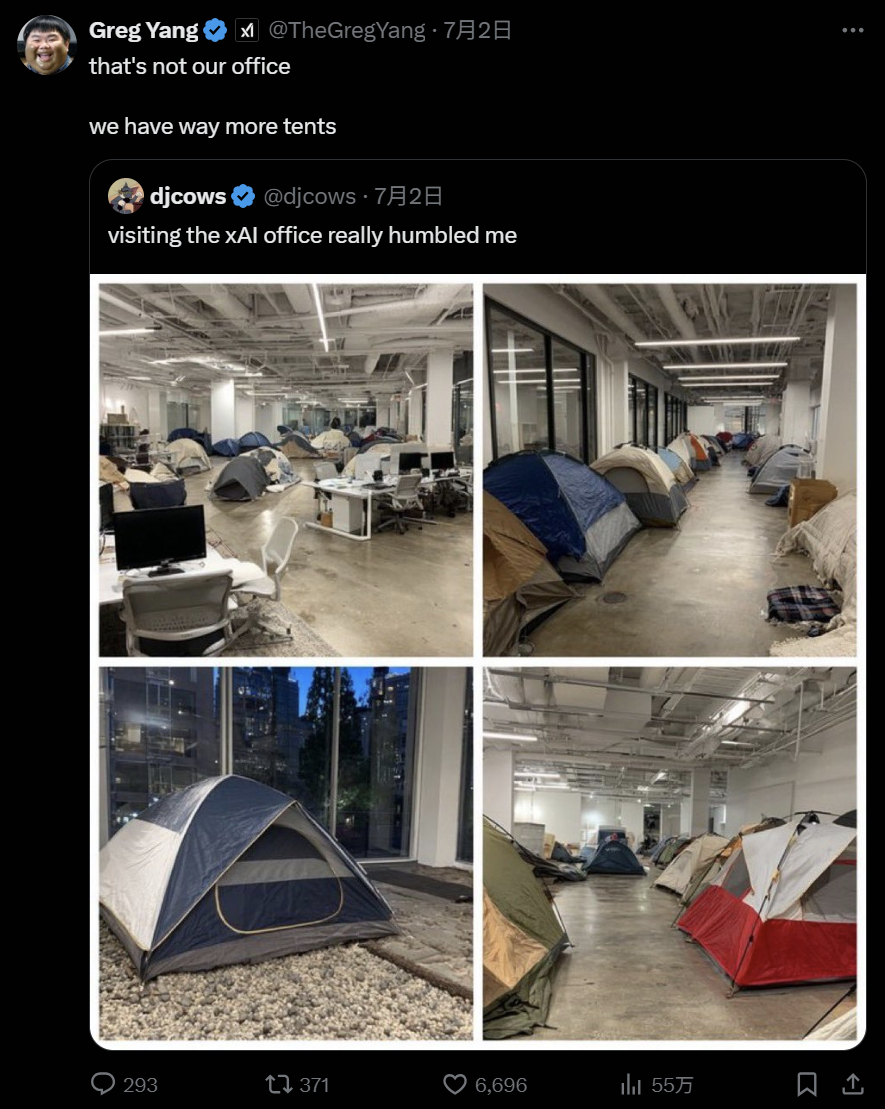
Is this AI race reaching new heights?
The leaked scores have excited many netizens and AI companies alike. Musk, while not officially announcing Grok4’s open-source release, said that the Twitter Grok features have significantly improved.

Some users asked Grok about the leak, and it responded that the July update was Grok4, but not complete.
With benchmark scores now exposed, Grok4 might be officially launched in the coming days. If true, its architecture and scale will likely push the development of large AI models forward. Let’s stay tuned.
References: