Beyond O4-mini: GThinker Model Achieves Visual Reconsideration in Multimodal Large Models}
The GThinker model from CASIA introduces a novel cue-guided rethinking approach, enabling multimodal models to revisit and improve visual understanding, surpassing previous models like O4-mini.


Despite significant progress in structured tasks like mathematics and science, current multimodal large models still face performance bottlenecks in flexible visual interpretation. Existing models rely heavily on knowledge-based reasoning but lack deep verification and reconsideration of visual cues, leading to frequent errors in complex scenarios.
To address this challenge, researchers from the Institute of Automation, Chinese Academy of Sciences, proposed GThinker, a new multimodal large model designed for general reasoning tasks.
GThinker’s core innovation is the “Cue-Guided Rethinking” mode, which enables the model to actively verify and correct its visual understanding during reasoning.
Through a carefully designed two-stage training process, GThinker achieved performance surpassing the latest O4-mini model on the challenging M³CoT comprehensive reasoning benchmark, demonstrating strong generalization capabilities. The paper, data, and models are all open source.

- Paper link: https://arxiv.org/abs/2506.01078
- Project page: https://github.com/jefferyZhan/GThinker
- Open-source repository: https://huggingface.co/collections/JefferyZhan/gthinker-683e920eff706ead8fde3fc0
Limitations of Slow Thinking: When Models “Ignore” in General Scenarios
Current models like Qwen2.5-VL and GPT-4o are expanding capabilities, especially with Chain-of-Thought (CoT) strategies. However, their reasoning in general multimodal scenarios remains limited, often failing to revisit visual cues for correction.
Unlike structured mathematical tasks, general scenarios such as interpreting images or analyzing complex scenes involve:
- High visual dependency: Correct interpretation of multiple or ambiguous visual cues is crucial.
- Complex reasoning paths: No fixed solution pattern; models need flexible reasoning strategies.
Existing methods, whether based on structured CoT or reinforcement learning, often lack mechanisms for “looking back” and correcting biases once visual misjudgments occur, leading to errors accumulating along the reasoning path.
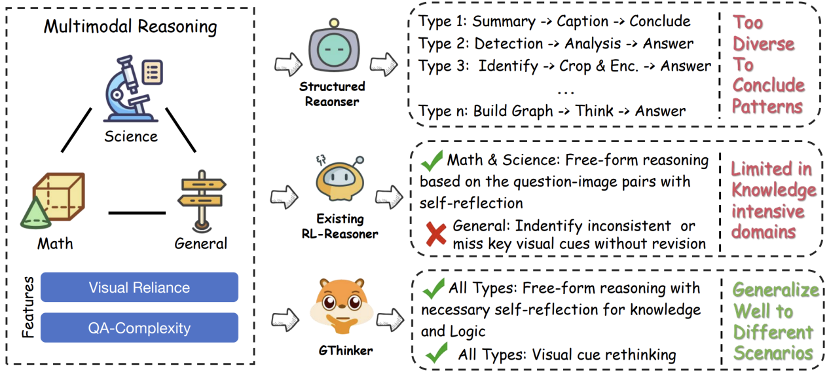
Characteristics and limitations of current mainstream multimodal reasoning methods
GThinker: From “Chain of Thought” to “Reconsideration Chain”
To break this bottleneck, the team proposed GThinker, which introduces a novel “Cue-Guided Rethinking” reasoning mode. This mode transforms reasoning into a human-like “think - reflect - revise” loop, allowing the model to systematically revisit and verify visual cues after initial reasoning.
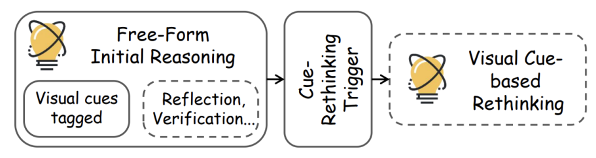
Figure: The core process of Cue-Rethinking, where dashed boxes indicate potential re-evaluation steps. The process involves three stages:
- Initial free reasoning based on question and image, with key visual cues marked with <vcues_*> tags.
- Triggering reflection with a prompt like “Let’s verify each visual cue and its reasoning before finalizing the answer.”
- Systematic review of marked cues, checking for inconsistencies or errors, then revising reasoning accordingly.

GThinker reasoning example
In the example above, GThinker initially misjudges a shape as a “crab.” During rethinking, it recognizes that the “red triangle” resembles a shrimp head rather than a crab body, and the “blue-pink combination” looks more like a shrimp tail than crab pincers. It then revises its reasoning path and correctly concludes “shrimp.” This mechanism allows GThinker to handle ambiguous or misleading visual cues effectively, greatly improving reasoning accuracy.
Two-Stage Training: Teaching the Model to Rethink
To internalize this powerful reflection ability, GThinker employs a tightly coupled two-stage training framework.
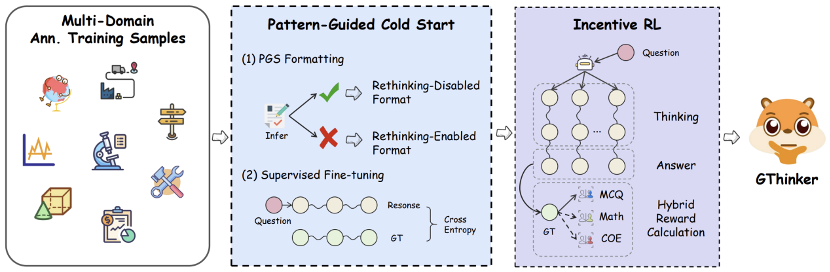
Overall training process diagram
Mode-guided cold start
Unlike mathematical reasoning, where reflection abilities emerge naturally after pretraining, relying solely on reinforcement learning for complex rethinking is costly and inefficient. Therefore, GThinker first uses supervised fine-tuning to build visual-cue-based rethinking ability, providing a “cold start.”
Specifically, a “multi-modal iterative annotation” process was used to create a high-quality dataset of 7,000 cold-start samples. This involved leveraging GPT-4o, O1, O3, and other advanced models to iteratively reason and annotate complex problems across general, math, and science domains, generating high-quality rethinking paths.
During training, GThinker adopts a “selective formatting based on mode guidance” strategy, applying full “rethink chains” only to samples where the base model might misjudge visual cues, while others remain in standard reasoning format. This enables the model to learn when to perform rethinking, avoiding unnecessary overhead.
Reinforcement Learning with Rewards
Building on the learned “how to think” and “rethink based on visual cues,” GThinker introduces a reward-based reinforcement learning approach, designing a hybrid reward mechanism and multi-scenario training data to encourage active exploration across diverse tasks, promoting cross-scenario generalization.
- Multi-scenario data: Collects open-source reasoning data, uses embedding clustering for balanced, diverse sampling, and curates about 4,000 multi-task, multi-scenario training samples to enhance generalization.
- Dynamic sampling (Dapo): Ensures effective batch samples, applying strategies like no KL and higher clipping, suitable for long-chain reasoning and exploration, enabling the model to choose optimal reasoning modes in different scenarios.
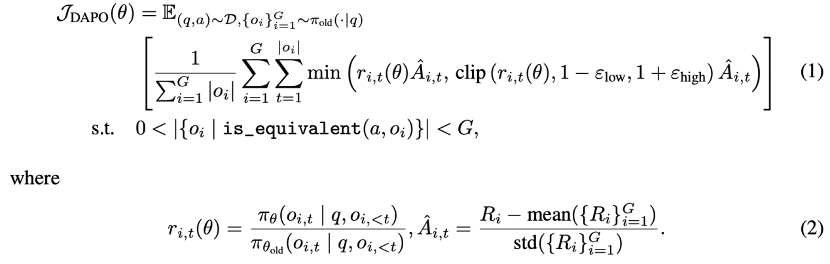
- Hybrid reward calculation: For common tasks like multiple-choice and math problems, rewards are computed via exact matching and Math-Verify tools. For open-ended questions, formatted responses are used to ensure accurate reward signals and support task diversity.
Results
On the complex, multi-step, multi-domain multimodal reasoning benchmark M3CoT, GThinker outperforms current leading open-source models and O4-mini in various scenarios.
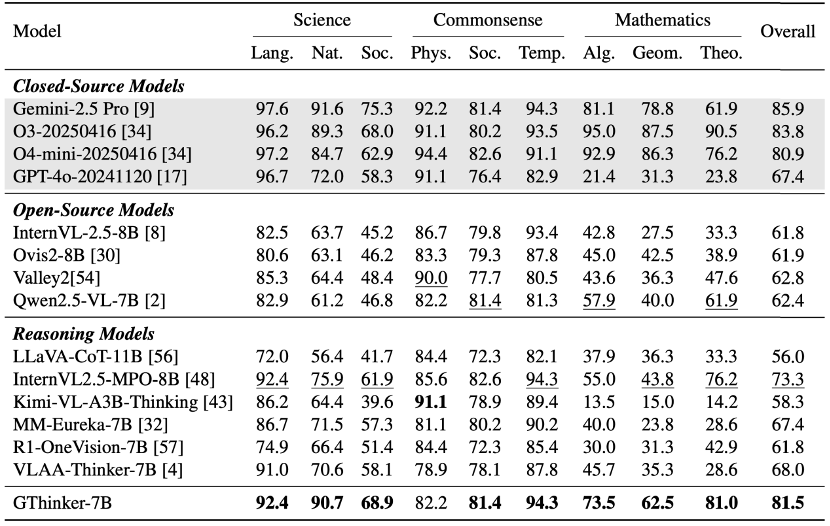
In tests across general, multi-disciplinary, and math benchmarks, GThinker demonstrates performance equal to or better than state-of-the-art models, confirming its strong rethinking ability and overall generalization.
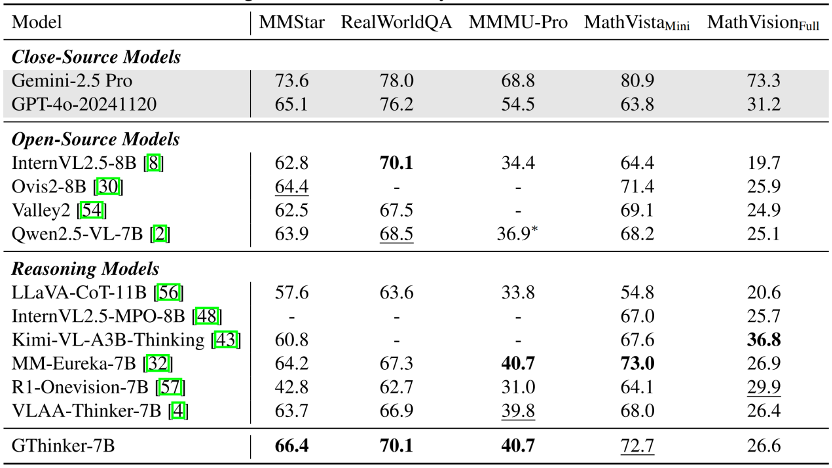
Despite training on complex reasoning tasks, GThinker can further improve on general benchmarks. Testing on the latest open-source models ranked in the OpenCompass leaderboard shows about 1% performance gains across three top models, demonstrating its strong generalization and effectiveness.

Demo

