Berkeley & Meta Present World Model for Embodied Intelligence: Enabling AI to 'See' the Future Through Full-Body Movements}
Researchers from Berkeley and Meta develop a world model for embodied intelligence, allowing AI to predict visual outcomes based on full-body actions, advancing human-like perception and planning.


This article is based on research by Yutong Bai, Danny Tran, Amir Bar, Yann LeCun, Trevor Darrell, and Jitendra Malik.

- Paper Title: Whole-Body Conditioned Egocentric Video Prediction
- Project Link: https://dannytran123.github.io/PEVA/
- Further Reading: https://x.com/YutongBAI1002/status/1938442251866411281
For decades, AI researchers have pondered a fundamental question:
What kind of "world model" does an agent need to act, plan, and interact effectively in the real world?
Early models were primarily predictive engines: given an abstract control command like "move forward one meter" or "turn left 30 degrees," they could simulate future images. While effective in lab environments, these models often fall short in complex real-world settings.
Humans are not floating cameras; we have limbs, joints, bones, and physical constraints:
- Range of joint motion
- Balance and stability of the torso
- Muscle strength limits
These physical constraints determine which actions are feasible within reach, balance, and strength limits. Such physicality shapes human movement and the visual information we perceive or miss.
Examples include:
- Turning your head or body to see behind you
- Bending down to see under the table
- Reaching up to grab a cup on a high shelf
These actions are not arbitrary but governed by body structure and kinematic constraints. For AI to predict the future like humans, it must learn what actions its body can perform and the visual consequences of those actions.
Why is vision part of planning?
Psychology, neuroscience, and behavioral science have long shown that humans pre-visualize what they will see next before executing actions:
- Predicting when a water glass will appear as you approach it
- Anticipating the scene ahead when turning a corner
- Imagining when your arm will enter the visual field while reaching
This "pre-visualization" allows us to correct actions and avoid mistakes. We don’t just decide based on what we see but also on mental simulations of future visual states.
To achieve human-like planning, AI must incorporate similar predictive mechanisms: "If I move this way, what will I see next?"
Old and new approaches to world models
The concept of world models is not new, dating back to Craik’s 1943 idea of a "small-scale brain model," control theories like Kalman filters and LQR, and recent deep learning visual prediction models. All aim to answer: "What happens if I take an action?"
However, these methods often only consider low-dimensional controls like "move forward" or "turn." Compared to human full-body movements, they are simplistic because human actions involve:
- Dozens of degrees of freedom in joints
- Hierarchical control structures
- Visual outcomes that change with environment dynamics
A world model that ignores body movement’s impact on visual information cannot survive in real-world scenarios.
PEVA’s small experiment
In this context, researchers from UC Berkeley and Meta posed a simple yet profound question: "If I perform a full-body movement, what will I see from my eyes next?"
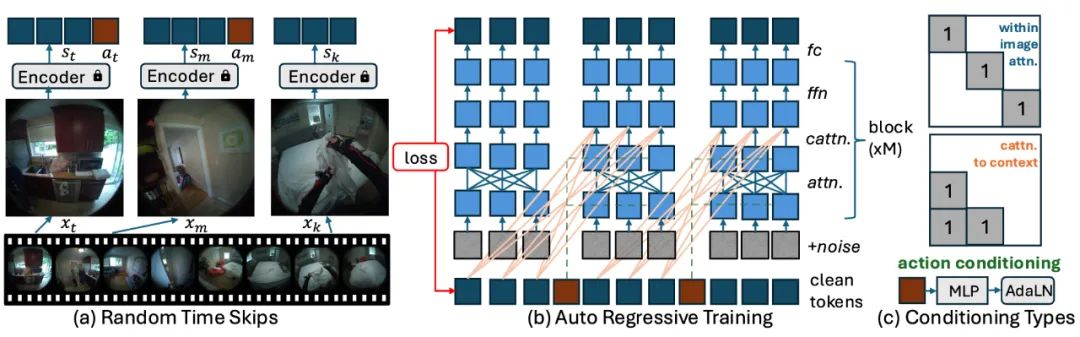
Unlike traditional models that only predict speed and direction, PEVA inputs the entire 3D body pose (joint positions and rotations) along with historical video frames, enabling AI to learn how body movements reorganize visual perception.

Examples include:
- Raising an arm blocks some objects but reveals new areas
- Squatting changes the viewpoint height and reveals ground features
- Turning the head reintroduces behind-the-back information into view
This is PEVA’s core: predicting the future, not just pixels, but visual consequences driven by body actions.

PEVA’s capabilities include:
- Predicting continuous first-person videos from future full-body 3D poses
- Decomposing complex behaviors into "atomic actions," such as controlling only the left hand or head rotation

It can generate visual streams up to 16 seconds long, support "counterfactual" inference: "What if I perform a different action?" and plan among multiple action sequences by visual similarity to select the best scenario.
PEVA enables learning in diverse daily environments, avoiding overfitting in simple scenarios. In essence, PEVA acts as a "body-driven visual simulator," giving AI a more human-like way of imagining the future.
Technical details
PEVA’s approach is straightforward, mainly involving:
- Full-body motion input (48-dimensional 3D pose)
- Conditional diffusion model + Transformer, balancing visual generation and temporal logic
- Training on synchronized real videos and motions (Nymeria dataset)
- Predicting up to 16 seconds ahead using a jump strategy
- Planning multiple scenarios by selecting the most visually similar trajectory
Researchers also discuss limitations and future directions, such as planning for only one arm or partial body, coarse goal descriptions, and the need for natural language goal specification. These are areas for ongoing development.
Capabilities summary
PEVA demonstrates feasibility in several aspects:
- Short-term visual prediction aligned with body actions
- Maintaining coherence in up to 16 seconds of video
- Controlling atomic actions like hand movements or turning
- Planning multiple actions and selecting the closest goal
These suggest that body-driven future visual prediction is a promising step toward embodied intelligence.
Future prospects
- Incorporating language goals and multimodal inputs
- Closed-loop control in real interactions
- Interpretable planning for complex tasks
To make AI act like humans, it may first need to learn: "If I move this way, what will I see?"
Conclusion
Perhaps we can say: "Humans see the future because their bodies move, and vision updates accordingly." PEVA is a small step but aims to inspire future explainable and trustworthy embodied AI."