Audio-Visual Synchronization: AI Video Can Now Have Perfect 'Original Sound' — Keling AI Launches!}
Keling AI introduces advanced multimodal video audio generation, enabling AI to produce synchronized, high-quality soundtracks and effects directly from video and text inputs, now available to users.

Has AI generated the 'final boss' level been surpassed?
Thanks to generative AI, the popular Labubu now has an adorable exclusive background music (BGM):
Video from KeLing AI Creative Circle users.
Even complex natural environments can now have corresponding background sounds.
Video from WeChat.
Now, it’s also possible to generate various ASMR sounds, such as the sound of cracking a bomb shell:
Video from KeLing AI Creative Circle users.
Recently, people have been discussing a large model that adds sound effects to AI-generated videos.
It claims to be an 'all-rounder': whether input is text or silent video, it can generate matching sound effects or music with precise timing and realistic details. Even more impressively, it can match environmental sounds within the scene, creating a stereo soundscape.
This marks a significant breakthrough compared to previous AI sound effect generators.
This new innovation comes from KeLing AI, which introduced the Kling-Foley multimodal video sound generation model capable of automatically producing high-quality, synchronized stereo audio matching video content.
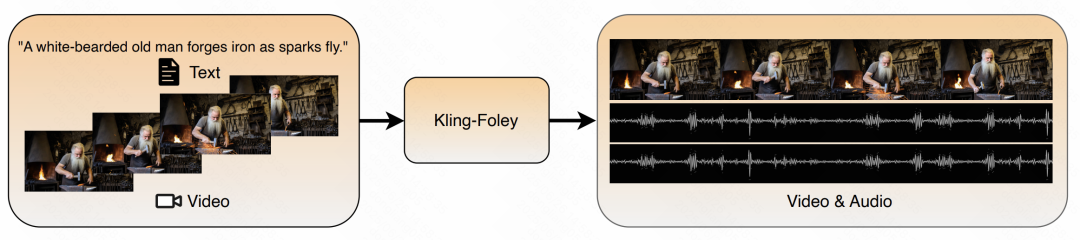
Input: video and text; Output: sound effects and BGM.
Kling-Foley supports automatic generation of semantically relevant, time-synchronized stereo audio, including sound effects and background music, based on video content and optional text prompts. It can generate any length of audio, supports spatial sound source modeling, and delivers immersive stereo rendering.
Many overseas users have already adopted it and praised it on social media.
KeLing AI has published a technical report on Kling-Foley, providing an in-depth look at the technology behind it.

- Paper: https://arxiv.org/pdf/2506.19774
- Project Homepage: https://klingfoley.github.io/Kling-Foley/
- GitHub: https://github.com/klingfoley/Kling-Foley
- Benchmark: https://huggingface.co/datasets/klingfoley/Kling-Audio-Eval
How does AI generate background sound just by watching videos?
Audio-visual synchronization is a key milestone for generative AI.
Generative AI is rapidly evolving worldwide, especially in video generation. The latest models from KeLing AI, like the 2.1 series, produce astonishingly realistic character movements and details.

Video from WeChat influencer @Artedeingenio
However, AI-generated videos have lacked synchronized sound effects for two years. Manually adding soundtracks reduces efficiency, as most users cannot master complex tools like professional voice actors.
How can large models better generate synchronized sound for videos?
Research in this area has existed for some time, but traditional Text-to-Audio (T2A) methods face challenges like limited input modalities and difficulty in accurately understanding video content, often resulting in desynchronization.
In contrast, Video-to-Audio (V2A) methods can directly combine video and text, improving relevance and accuracy. This requires large, multimodal datasets with aligned video, audio, and annotations, which is a significant challenge.
Kling-Foley demonstrates several innovations. Its overall structure is as follows:
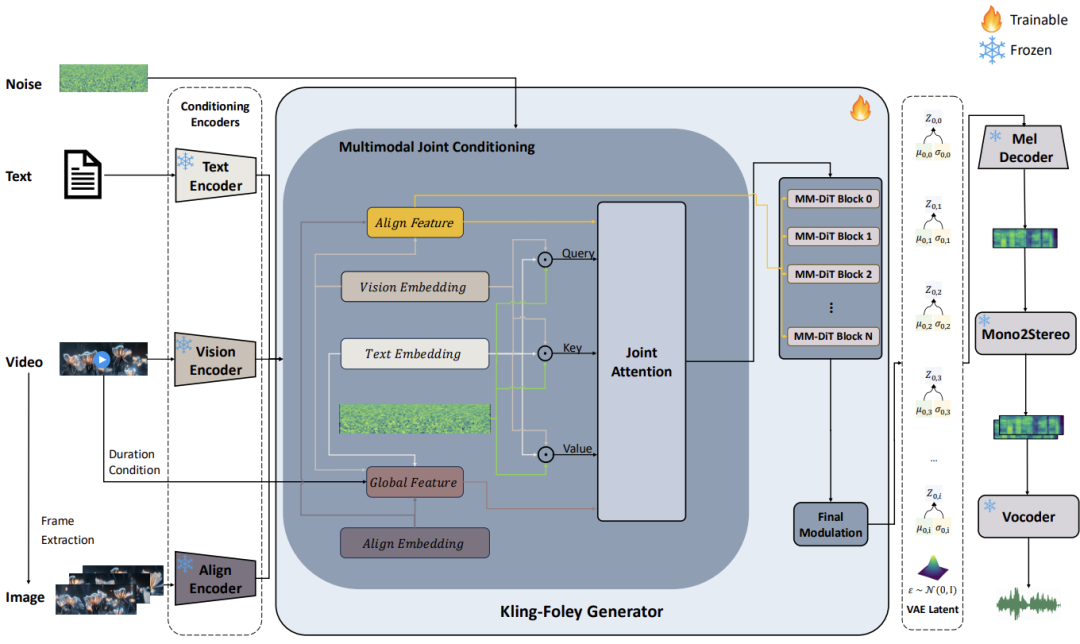
Specifically, Kling-Foley is a multimodal control flow matching model. During audio generation, text, video, and frame-level features are used as conditions. These features are fused through a multimodal joint conditioning module and processed by the MMDit module, which predicts VAE latent features. These are then reconstructed into mono Mel spectrograms via a pre-trained Mel decoder, rendered into stereo Mel spectrograms, and finally converted into waveforms by a vocoder.
To address the interaction between video, audio, and text modalities, Kling-Foley adopts a flexible MM-DiT block design inspired by Stable Diffusion 3, allowing arbitrary combinations of text, video, and audio inputs.
Ensuring the generated sound aligns temporally with video is crucial. The framework introduces visual semantic representation and audio-video synchronization modules, which perform frame-level alignment of video conditions and audio latent features, enhancing semantic and temporal coherence. Discrete duration embeddings are also used to support variable-length audio-visual generation and improve timing control.
At the latent audio representation level, Kling-Foley employs a universal latent audio codec, capable of high-quality modeling across diverse scenarios like sound effects, speech, singing, and music.
The core of the latent audio codec is a Mel-VAE, jointly trained with a Mel encoder, decoder, and discriminator. This VAE structure enables the model to learn a continuous, complete latent space, significantly enhancing audio representation capabilities.
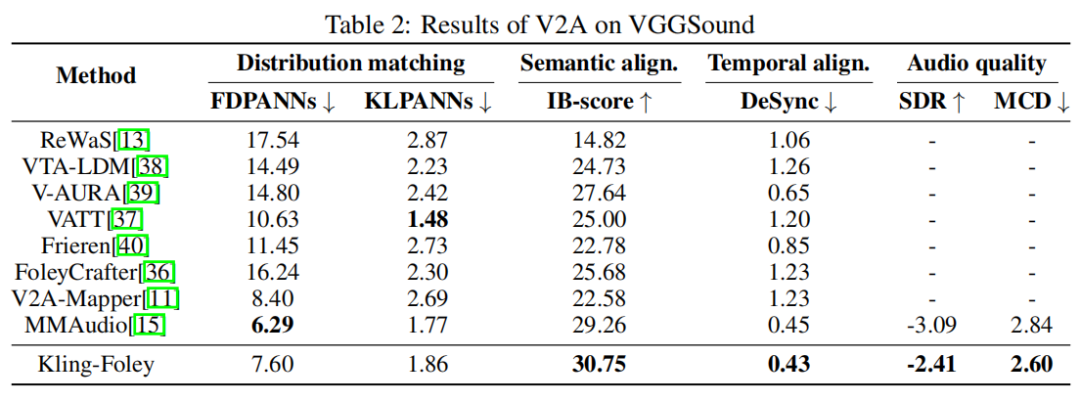
Experimental results show that Kling-Foley trained with stream matching objectives achieves state-of-the-art performance in audio quality, semantic alignment, and synchronization compared to existing models.
Building Multimodal Datasets from Scratch
KeLing AI also built a large-scale multimodal dataset with over 100 million samples, each containing raw video clips, corresponding mono audio, and structured textual descriptions. These are sourced from real online videos, with all three modalities tightly aligned.
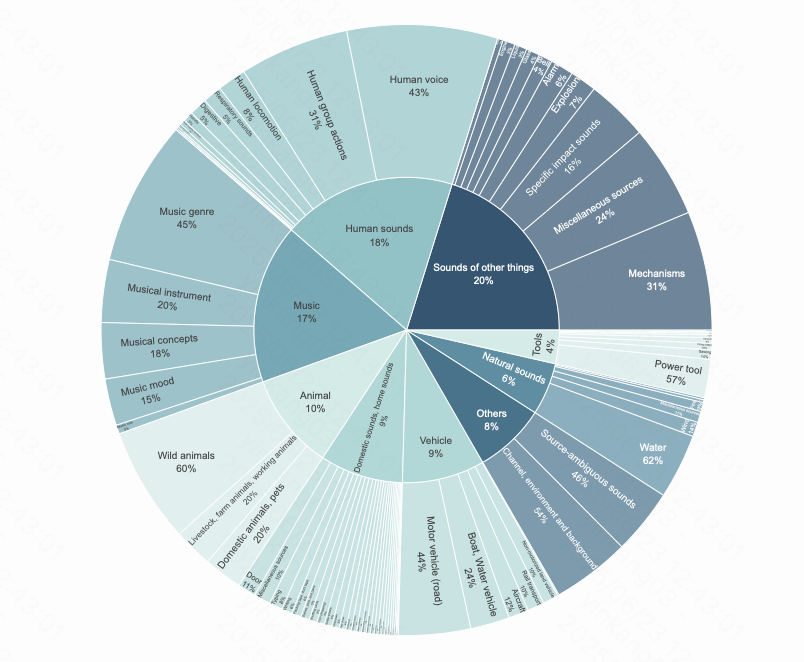
During data processing, KeLing AI uses an automated multimodal data pipeline combined with manual annotation to ensure quality. The dataset covers a wide range of acoustic scenes, including natural environments, human activities, animal sounds, machinery, and transportation, providing a solid foundation for learning diverse generation patterns and improving realism and controllability.
KeLing AI also released Kling-Audio-Eval, an open benchmark dataset containing video, video descriptions, audio, audio descriptions, and multi-level sound event labels. It includes 20,935 finely annotated samples covering nine major sound event categories like traffic, human voices, and animals. It is the industry’s first multimodal benchmark with both audio and video descriptions, supporting comprehensive evaluation of models’ performance.
Finally, KeLing AI compared Kling-Foley with several mainstream methods on public benchmarks, demonstrating its superior performance in semantic alignment, temporal synchronization, and audio quality.
If comparing the encoding and decoding capabilities across sound effects, music, speech, and singing, Kling-Foley also achieves top scores in most metrics.