At WAIC, the World's First Large Model with 'Native Memory' Debuts, Not Based on Transformer}
The first large model with native memory, not based on Transformer, was unveiled at WAIC, showcasing a new architecture that significantly reduces inference complexity and enhances on-device intelligence.


After eight years of dominance by Transformer models, Google, the creator of Transformer, has begun exploring new architectures. Last month, Google product lead Logan Kilpatrick highlighted the limitations of current attention mechanisms, leading to the launch of the new MoR architecture. These moves indicate a broad consensus on the need for architectural innovation in AI.
At the recent WAIC (World Artificial Intelligence Conference), this trend was evident, and even domestic companies are making more radical changes than Google.
The agile robotic hand in the video is driven by an offline multimodal large model. Although the model is only 3B in size, once deployed on edge devices, its performance and latency are comparable to much larger cloud models, with multimodal capabilities like seeing, hearing, and reasoning.

Crucially, this model is not based on Transformer but on the Yan 2.0 Preview architecture proposed by China’s AI startup RockAI. This architecture greatly reduces inference computation, enabling offline deployment on devices with limited computing power, such as Raspberry Pi.
Unlike other on-device models that are small versions of cloud large models, Yan 2.0 has a form of native memory, allowing it to incorporate memory into its parameters during inference, thus improving over time as it interacts with users. This means each new session builds on previous interactions, unlike Transformer-based models that forget past conversations like a friend who forgets after sleeping.
Why did RockAI undertake such a radical overhaul of Transformer? How is it achieved? And what does it mean for AGI? After an in-depth interview with RockAI’s founding team, we obtained valuable insights.
Why does RockAI challenge Transformer after so many years?
RockAI’s challenge to Transformer began early in 2024, with the release of Yan architecture 1.0, after two years of exploration into architecture innovation. Transformer models face issues like data walls and computational dependence. They require massive data for pretraining, which is increasingly hard to obtain, and their inference demands high computing power, making deployment on low-resource devices difficult. Moreover, models cannot be easily updated once deployed, as techniques like quantization and pruning damage their ability to learn and adapt, locking their intelligence at deployment time.
To fundamentally solve these issues, RockAI started from scratch, exploring a non-Transformer, non-Attention architecture—Yan 2.0. They not only found effective technical solutions quickly but also achieved commercial deployment on limited hardware.

Yan 2.0 Preview: The World’s First Large Model with 'Native Memory'
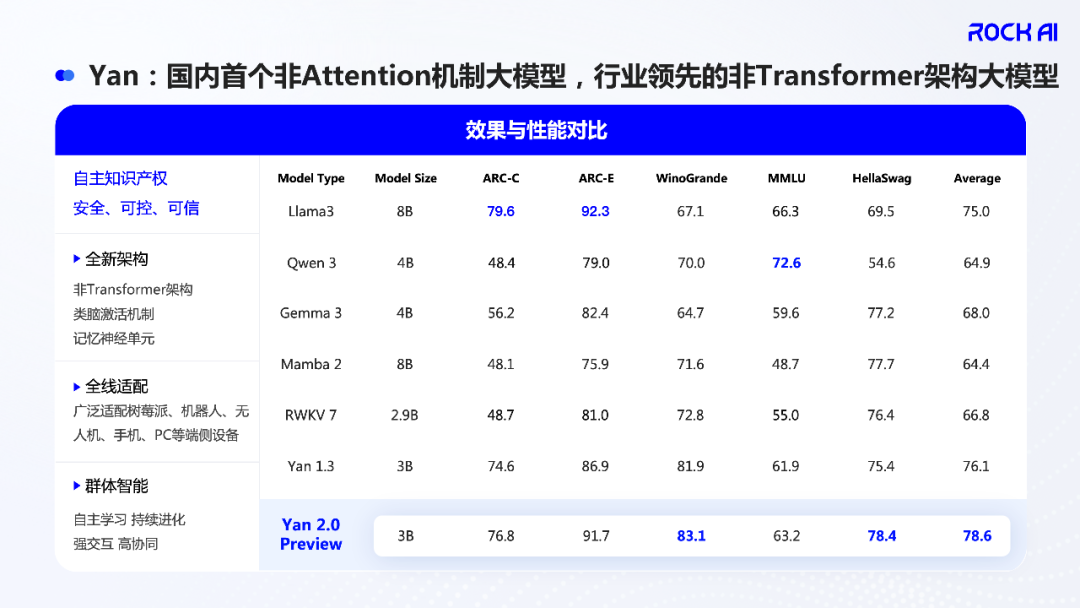
The comparison chart below shows Yan 2.0’s performance against other architectures. Yan 2.0 excels in generation, understanding, and reasoning, demonstrating a significant advantage in efficiency and parameter utilization over mainstream Transformer models.
Of course, the real highlight is the “memory” feature. Recent papers, products, and discussions emphasize memory as a key shortcoming of current LLMs and a breakthrough for future AI applications. Imagine a talking Labubu with personalized memory that deepens over years of interaction, creating emotional bonds.
Currently, most industry approaches use external memory modules like long context windows or RAG (Retrieval-Augmented Generation). RockAI criticizes these methods because they treat memory as a sequence without a true sense of time, lacking genuine personalization. They believe that integrating native memory into the model itself, like Yan 2.0, is closer to biological memory, embedding knowledge directly into the neural network weights.
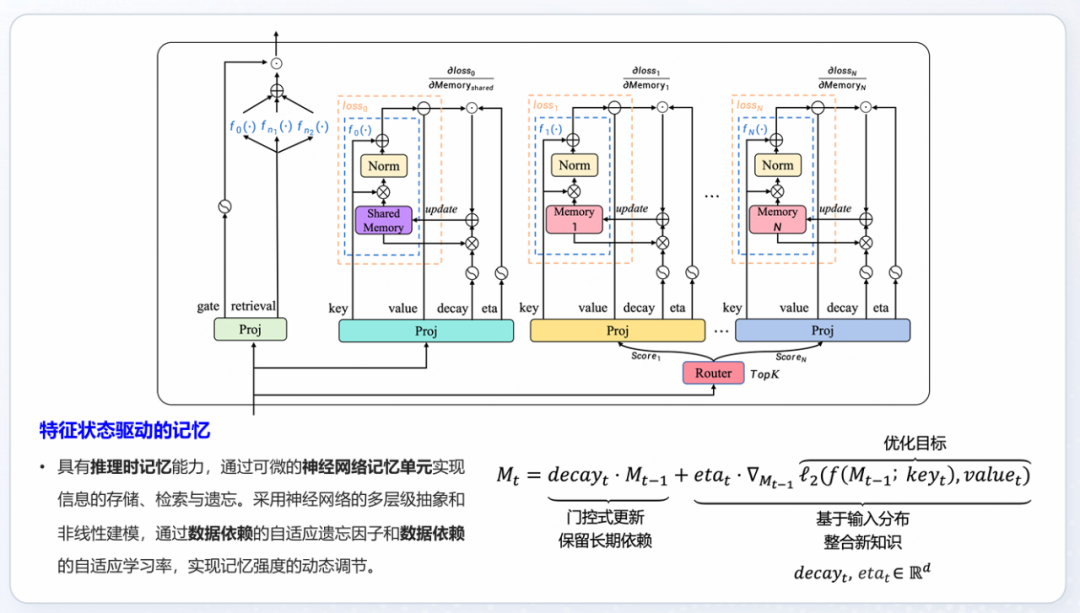
The diagram below illustrates Yan 2.0’s architecture, which uses a differentiable “neural memory cell” to store, retrieve, and forget information. This mechanism resembles the evolution from early machine learning to deep learning, where features are learned automatically, and models become end-to-end, without manual feature engineering.
At the scene, we experienced Yan 2.0’s native memory with a “learn-as-you-go” robot dog. After restarting the chat, it still remembered its learned actions and preferences.
Embedding memory into the model architecture transforms it from a temporary cache into a form of “intelligent accumulation” with a sense of time, personality, and context. This could revolutionize the current paradigm of massive data dependence, turning models into lifelong companions that learn and adapt locally, respecting privacy and enabling personalized, long-term interaction.
Such models could evolve into “digital brains” with perception, memory, and learning capabilities, fundamentally changing how devices serve users and how AI develops in the future.
Offline Intelligence: Enabling Every Device to Have Its Own Intelligence
Researchers like Yang Hu from RockAI emphasize that their goal is not just “edge AI” but “offline intelligence,” where models run entirely on local devices without internet connection, enabling autonomous learning and growth, akin to a child developing over time.
This approach contrasts with cloud-dependent models, offering long-term value and differentiation in hardware, as devices become capable of continuous self-improvement, which could lead to a new era of personalized AI devices.
RockAI’s vision is to create a future where every device has its own evolving intelligence, fostering a collective intelligence emerging from autonomous, self-learning units, ultimately aiming for artificial general intelligence (AGI).
In this long-term vision, the device’s value grows with its ability to learn and adapt, transforming from a static tool into a “digital brain” with perception, memory, and learning, capable of lifelong development.