AI 'Stealing' Your Data? Six Major Institutions Propose a Four-Level Data Protection System}
Leading global institutions jointly introduce a four-tier data protection framework for AI, addressing privacy, traceability, and deletion to safeguard data in the era of generative AI.

The co-first authors are Dr. Yiming Li, Postdoctoral Researcher at Nanyang Technological University, Singapore, and Miao Shao, PhD student at Zhejiang University’s National Key Laboratory of Blockchain and Data Security. Corresponding authors are Dr. Yiming Li and Professor Zhan Qin of Zhejiang University. Other contributors include: PhD student Yu He from Zhejiang University, Postdoctoral researcher Junfeng Guo from Maryland University, Associate Professor Tianwei Zhang and Professor Cheng Tao from NTU Singapore, Dr. Pin-Yu Chen, Chief Research Scientist at IBM Research, Professor Michael Backes of Helmholtz Center for Information Security, Professor Philip Torr of Oxford University, and Dean Kui Ren of Zhejiang University’s School of Computer Science and Technology.
Have you ever worried that a code snippet or report you casually shared with an AI assistant might lead to a leak? Or that a piece of artwork you posted online could be copied and used commercially by AI painting tools?
This is not alarmist talk. In 2023, a Samsung employee leaked confidential source code to ChatGPT; the same year, Italy’s data protection authority temporarily halted ChatGPT over concerns about user conversations being used for overseas AI training. As generative AI becomes ubiquitous, more users rely on and depend on AI in daily work and life, sounding alarms for every AI user and industry practitioner.
This reveals a profound transformation: in the AI era, especially with generative AI, data is no longer static files stored on disks but a “fluid” throughout the entire lifecycle of training, inference, and generation. Traditional data protection methods (like encryption and firewalls) are no longer sufficient. There is an urgent need for a new conceptual framework to comprehensively understand data protection challenges in the generative AI age.
What does data protection mean in the (generative) AI era? To answer this, researchers from Zhejiang University’s Blockchain and Data Security Laboratory, NTU Singapore, Maryland University, IBM, Helmholtz Center for Information Security, and Oxford University recently published a forward-looking paper titled "Rethinking Data Protection in the (Generative) Artificial Intelligence Era". The paper aims to provide a simple yet systematic perspective on data protection issues in AI.

- Paper title: Rethinking Data Protection in the (Generative) Artificial Intelligence Era
- Link to the paper: http://arxiv.org/abs/2507.03034
Which data needs protection in the generative AI era?
Data protection in AI is no longer just about static data but involves various data types across the entire model lifecycle, including training datasets, AI models, deployment data, user inputs, and AI-generated content.
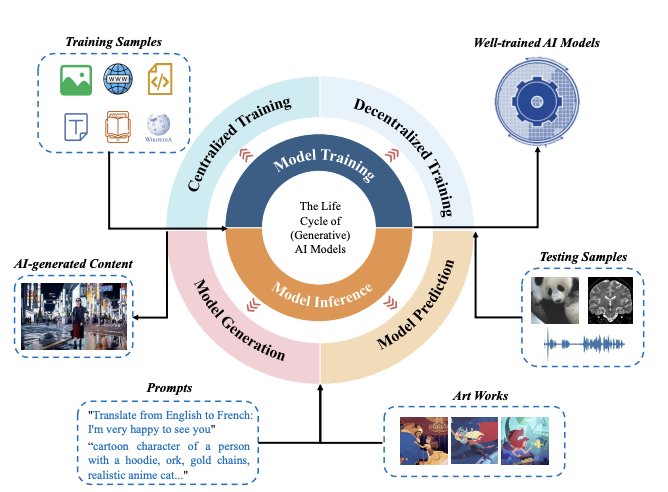
- Training Data: During model development, large amounts of high-quality training data are collected from multiple sources, often containing sensitive or copyrighted information.
- AI Models: Post-training, the architecture and weights of AI models become valuable data assets, with applications in downstream tasks and industry value.
- Deployment Data: During deployment, auxiliary data like prompts and external databases are used to improve performance and relevance, raising privacy concerns.
- User Inputs: User queries, which may contain personal or confidential information, need protection to ensure privacy and security, especially against leaks or misuse.
- AI-Generated Content (AIGC): As AI-generated content reaches high quality, it can be used to create large synthetic datasets, raising copyright and ethical issues.
How should we protect data in the AI era?
To systematically address data protection, this paper proposes a new four-tiered Data Protection Grading System, ranking from strongest to weakest: Data Unavailability, Data Privacy, Data Traceability, and Data Deletability. This classification aims to balance “data utility” and “data control,” providing a structured approach to complex data protection challenges and guiding practitioners and regulators to find optimal balances.
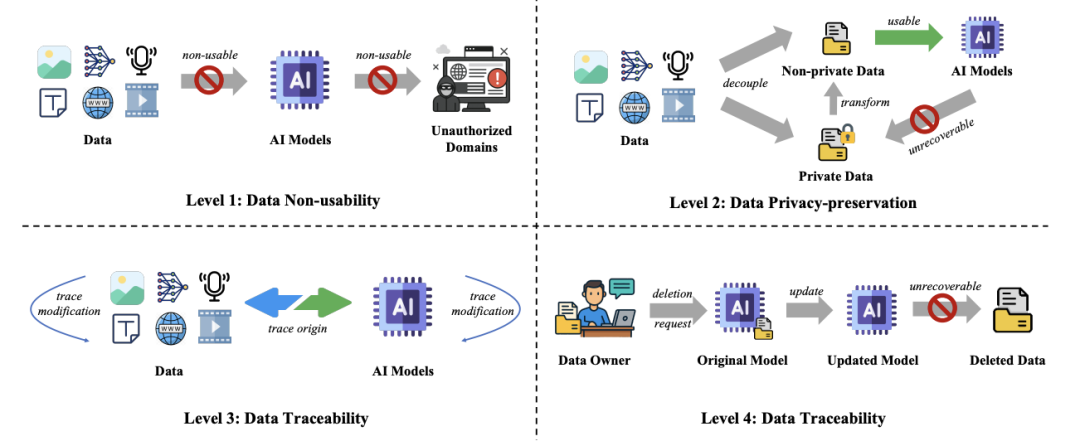
- Level 1. Data Non-Usability: Data is fundamentally blocked from being used in training or inference, even if accessed by attackers, ensuring maximum protection at the cost of utility.
- Level 2. Data Privacy-preservation: Protects personal information (like age, gender, address) during collection and inference, maintaining some data utility while ensuring privacy.
- Level 3. Data Traceability: Enables tracking data sources, usage, and modifications, allowing audits and preventing misuse, with minimal impact on data utility.
- Level 4. Data Deletability: Allows complete removal of data or its influence in AI systems, aligning with “right to be forgotten” laws like GDPR, providing the weakest protection but full control during deployment.
Practical implications and future challenges
This data protection framework offers valuable insights for understanding current technologies, shaping regulations, and addressing future challenges in AI data governance.
Design principles of existing data protection techniques: The paper discusses various strategies aligned with each protection level, providing a unified perspective for application and future development.
Global regulations and governance: It reviews laws from different regions, analyzing their characteristics, strengths, and shortcomings through the lens of the proposed grading system.
Future frontiers and interdisciplinary challenges: The paper explores the broader implications of data protection, including issues like data security, AI-generated content governance, cross-border data flow, and ethical considerations, emphasizing the need for balanced, responsible AI development.