Agent KB: Experience Pool Enables Agents to Learn from Each Other! GAIA New Open-Source SOTA Pass@1 Performance Boosts Up to 6.66}
Agent KB introduces an experience pool for inter-agent learning, achieving up to 6.66 improvement in Pass@1 performance, and presents GAIA's new open-source SOTA for complex AI tasks.


近日,来自OPPO、耶鲁大学、斯坦福大学、威斯康星大学麦迪逊分校、北卡罗来纳大学教堂山分校等多家机构的研究团队联合发布了Agent KB框架。这项工作通过构建一个经验池并采用两阶段检索机制,实现了AI Agent之间的有效经验共享。Agent KB通过层级化的经验检索,让智能体能够从其他任务的成功经验中学习,显著提升了复杂推理和问题解决能力。

Agent记忆系统:从独立作战到协同学习
在AI Agent的发展历程中,记忆系统一直是实现持续学习和智能进化的关键组件。广义上的Agent记忆系统包括用于存储临时信息的短期记忆、保存重要知识和经验的长期记忆,以及处理当前任务的工作记忆,部分还包括场景记忆。
然而,现有的记忆系统存在根本限制:不同Agent框架下的经验无法有效共享。每当遇到新任务时,往往需要从零开始探索,即使相似的策略已在相关领域验证。
Agent KB正是为解决这一痛点而生。它构建了一个共享的经验池/知识库系统,让不同的多智能体系统(如OpenHands、MetaGPT、AutoGen等)执行不同任务后,将成功经验抽象化存储。当遇到新测试例时,从历史经验中检索相关策略,将其他Agent的经验适配到新场景中。
核心技术包括“Reason-Retrieve-Refine”方案和Teacher-Student双阶段检索机制,让Agent在不同层次学习和应用历史经验。
GAIA基准:通用AI助手的终极挑战
GAIA(General AI Assistants)被誉为“通用AI助手的终极测试”,是目前最具挑战性的智能体评估基准之一。它专为评估智能体在复杂现实任务中的能力设计,任务来源于真实用户需求,需处理文本、图像、音频等多模态信息,并调用搜索引擎、代码执行器等工具,完成多步骤推理,容错率极低。
GAIA包含165个测试用例,分为三级:Level 1(基础任务)、Level 2(中等复杂度)、Level 3(高难度),主要指标为Pass@1(首次成功率)和Pass@3(三次内成功率)。
实验结果:Agent KB表现惊人

在GAIA基准测试中,Agent KB取得了令人瞩目的成绩。研究团队选择了相对简单的smolagents作为基础智能体框架,测试经验共享机制的效果,而非复杂框架的性能提升。
- smolagents地址:https://github.com/huggingface/smolagents
结果显示,在最严格的Pass@1评估下,GPT-4.1模型的性能从55.15%提升至61.21%,增幅6.06%;Claude-3.7从58.79%提升至65.45%,增幅6.66%。这些数据表明,即使在基础智能体框架上,Agent KB也能达到接近顶级商业系统的性能水平。

研究团队还测试了六个主流LLMs在Agent KB增强后的性能,从DeepSeek-R1到Claude-3.7,从GPT-4o到o3-mini,表现均有显著提升,验证了方法的普适性和可靠性。
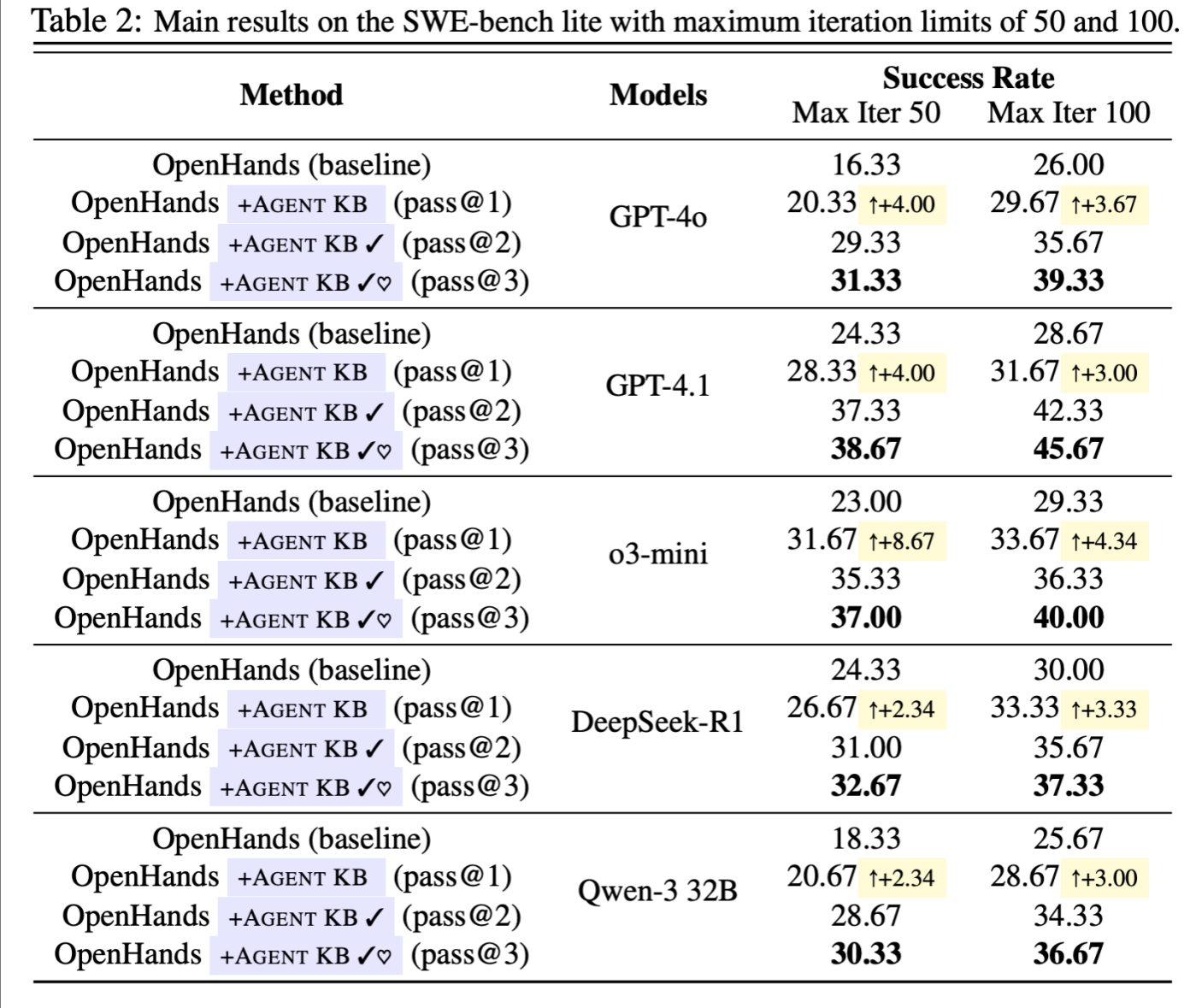
在SWE-bench数据集上,Agent KB在理解和修复代码方面也表现出色。o3-mini在50次迭代中从23.00%提升到31.67%,在100次迭代中从29.33%提升到33.67%,证明其跨域知识共享能力在专业任务中同样有效。
技术架构:Teacher-Student协作设计

Agent KB的核心创新在于“Reason-Retrieve-Refine”流程和Teacher-Student双阶段检索机制。它通过一个蛋白质数据库(PDB)距离计算案例,展示了这一机制的工作原理。在传统流程中,智能体会误读溶剂记录,导致错误距离,而Agent KB增强的智能体应用经验规则,过滤无关信息,验证距离,最终提取正确的骨架原子对,报告出准确距离。
深层架构体现:知识构建与增强推理
在知识构建阶段,系统从多个数据集提取泛化问题解决模式,通过自动摘要和few-shot提示,将日志转化为结构化知识条目,跨任务迁移能力强。增强推理阶段,采用双Agent协作:Student Agent负责检索和宏观策略,Teacher Agent负责微观细节和优化,确保整体策略正确,执行细节精确。整个架构支持跨域知识迁移,模块化设计,易于集成多种Agent架构,推动协作学习新方向。
深度消融验证:每个模块的重要性
系统性消融实验显示,双Agent架构的每个组件都至关重要。缺少Student Agent,Level 1任务准确率从79.25%降至75.47%;缺少Teacher Agent,准确率降至73.58%。移除Refine模块,整体准确率从61.21%骤降至55.15%,证明其在复杂推理中的关键作用。经验检索和格式规范的改进,显著提升模型性能和稳定性。
检索策略分析:多层次匹配确保知识精准
Agent KB采用多层次检索,包括文本相似度、语义相似度和混合策略,结合摘要和错误案例分析,优化宏观策略和微观细节匹配。实验显示,宏观策略中混合检索效果最佳,微观错误匹配则依赖文本相似度,确保知识匹配的准确性和泛化能力。
错误分析:优化智能体推理
通过错误统计分析,Agent KB的改进主要在于减少检索和规划错误,学习到更稳定的路径,格式规范显著减少,体现了经验的有效迁移和问题解决的提升。未来,系统将持续优化知识存储和检索机制,推动自主研究和跨域协作的深度发展。
技术与产业价值:开启AI协作新纪元
Agent KB的成功为深度研究提供新路径,展现了从历史经验中提炼洞察的潜力。未来,Agent的自我进化将依赖持续的经验积累和跨域知识迁移,推动AI系统的自主学习能力。其在GAIA基准上的开源SOTA成绩,仅是技术价值的冰山一角,未来将成为构建具备自我进化能力AI系统的核心技术支撑。