ACL 2025 Oral | Your Model Evaluation Partner: Evaluation Agent Understands You and AI Better}
Evaluation Agent, developed by Shanghai AI Lab and Nanyang Technological University, offers customizable, efficient, and explainable model evaluation, transforming AI assessment practices.


Authors from Shanghai AI Lab & Nanyang Technological University: Zhang Fan, Tian Shulin, Huang Ziqi, supervised by Qiao Yu and Liu Ziwei.
How to quickly judge if a generative model is good? The most direct way is to ask a friend who specializes in image or video generation or evaluation. They understand the technology, have experience, and can tell you where the model excels or falls short, and whether it suits your needs.
But there are issues:
- Friends are too busy to review everything for you;
- You have many questions, not just about “good or bad,” but also “where is it bad,” “why is it good,” and “is it suitable for me.”
You need a professional, patient, on-demand evaluation consultant.
Thus, researchers from Shanghai AI Lab & Nanyang Technological University’s S-Lab co-developed an AI “expert friend” — Evaluation Agent.
It not only evaluates but also listens to your questions, customizes tests, and generates human-expert-like analysis reports.
- Ask “How about its ancient-style video?” and it plans a scheme;
- Ask “Does it understand aperture and focal length?” and it designs tests;
- Want to know if it’s suitable for you? It can explain.
This is a new paradigm for visual generative model evaluation: Evaluation Agent was selected as an oral presentation at ACL 2025.

- Paper: https://arxiv.org/abs/2412.09645
- Code: https://github.com/Vchitect/Evaluation-Agent
- Website: https://vchitect.github.io/Evaluation-Agent-project/
- Title: Evaluation Agent: Efficient and Promptable Evaluation Framework for Visual Generative Models
Why choose Evaluation Agent?
1. Customizable: You specify your focus, and it plans the evaluation scheme accordingly.
Different users have different expectations for generative models — style? Diversity? Consistency?
Just describe your focus in natural language, and Evaluation Agent can:
- Automatically plan suitable evaluation processes;
- Flexibly adjust evaluation directions based on intermediate results;
- Deeply analyze the capabilities you care about.
This truly achieves “on-demand evaluation,” serving your specific tasks.
2. High efficiency: Faster evaluation with fewer samples
Traditional evaluation often requires thousands of samples. Evaluation Agent uses multi-round interactive evaluation and intelligent sampling strategies to significantly reduce sample size. The entire process can be about 10% of traditional time, ideal for rapid iteration feedback.
3. Explainability: Making evaluation results human-readable
Results are not just tables and numbers. Evaluation Agent generates natural language analysis reports, providing a comprehensive summary of model capabilities, limitations, and improvement directions.
4. Extensibility: Supports integration of new tools, metrics, and tasks
Evaluation Agent is an open framework, adaptable to various visual generation tasks like image and video synthesis.
Framework Workflow

The framework consists of two stages:
1. Proposal Stage
- Plan Agent: Analyzes user needs and plans evaluation paths dynamically;
- PromptGen Agent: Generates specific prompts for each sub-task.
This stage customizes evaluation schemes based on your focus.
2. Execution Stage
The system uses visual generative models to produce content and evaluates quality with appropriate tools.
- Generation Models: Generate samples based on prompts;
- Evaluation Tools: Use the planned tools to assess the generated content.
3. Multi-round Dynamic Interaction
Evaluation is iterative. Each round’s results feed back into the proposal stage to optimize prompts and tasks, enabling dynamic, in-depth assessment of model capabilities.
Results Overview
1. Comparison with traditional evaluation frameworks

Comparison of evaluation efficiency between visual generative models and VBench framework.

Comparison of evaluation efficiency for image and video generation models against T2I-CompBench framework.
The team validated Evaluation Agent on image (T2I) and video (T2V) generation tasks. Results show it is significantly more efficient, saving over 90% of evaluation time with high consistency.
2. User-open evaluation scenarios

Sample user questions include: “Can it generate high-quality videos of specific historical scenes?” and “Does it understand focal length, aperture, ISO?” The system can handle personalized, complex queries, providing detailed, dynamic assessments.
Evaluation Agent can explore model capabilities across diverse scenarios, from basic questions to complex, domain-specific tasks, with detailed natural language analysis and summaries.
For example, it can evaluate whether a model can generate variations of existing artworks while maintaining style, with visualized results and detailed explanations.
In the system, the Open-Ended User Query Dataset is crucial for testing the framework’s open evaluation capabilities. It includes diverse scenarios, especially for complex, user-specific assessments, demonstrating the system’s flexibility and adaptability.
The dataset was created through user surveys, data cleaning, filtering, expansion, and labeling, covering broad evaluation dimensions. The following chart shows its distribution across categories.
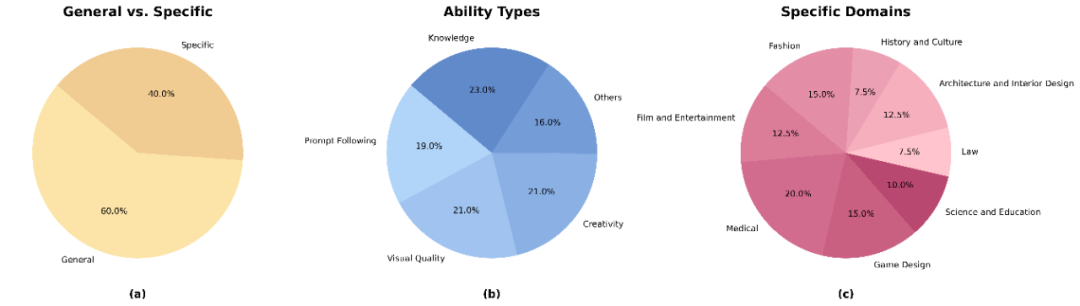
Statistics of the Open-Ended User Query Dataset.
Future prospects and plans
Initial studies show Evaluation Agent’s high efficiency and flexibility in visual model evaluation. Future directions include:
- Expanding evaluation capabilities to more visual tasks: including 3D content generation, AIGC video editing, and multi-modal AI evaluation.
- Optimizing open evaluation mechanisms: improving the dataset for complex concepts like style transfer, artistic fusion, and emotional expression, and incorporating reinforcement learning for self-optimization.
- Moving from automatic evaluation to intelligent recommendation: enabling personalized model recommendations based on user needs, and collecting expert feedback across domains to enhance adaptability and generalization.
Summary
Evaluation Agent introduces a high-efficiency, flexible, and explainable new paradigm for visual model evaluation. It overcomes traditional limitations, providing dynamic, user-focused analysis to support AI development.
The team hopes this approach will inspire new evaluation systems for more intelligent, adaptable generative AI.