5 Million Video Dataset + New Evaluation Framework! Peking University Opens Source for the New Infrastructure in Subject-Consistent Video Generation: OpenS2V-Nexus, Making Videos "Look" and "Natural"}
Peking University releases OpenS2V-Nexus, a comprehensive open-source toolkit with 5 million high-quality videos and a new evaluation framework, advancing subject-consistent video generation "like" and "natural".


Want AI to "generate consistent and natural short videos" just by "watching your selfie"? This is the challenge that Subject-to-Video (S2V) generation aims to solve: making videos not only aligned with text but also accurately preserving the features of specific persons or objects, ensuring the generated videos are both "like" and "natural". This capability is hugely significant for short video creation, virtual humans, AI editing, and more.
However, training and evaluating such models have long lacked publicly available large-scale datasets and fine-grained evaluation benchmarks, limiting rapid breakthroughs in S2V technology.
To address this, Peking University’s team launched the new open-source suite OpenS2V-Nexus, specially designed for S2V generation:
🌟 OpenS2V-Eval: The world’s first fine-grained evaluation benchmark for subject consistency, naturalness, and text alignment in S2V, enabling fair comparison across different models.
🌟 OpenS2V-5M: The world’s first publicly available 5 million high-quality 720P person-text-video triplet dataset, covering real and synthetic data, helping researchers train more powerful generation models.
The Peking University team also conducted systematic evaluations on 18 representative S2V models, revealing the real capabilities and gaps in maintaining subject consistency and naturalness.
Through OpenS2V-Nexus, future AI video generation will no longer be blind guessing, making training more efficient, evaluation more scientific, and enabling truly controllable, natural, and identity-preserving AI video generation to be quickly applied in real scenarios.
This work brings three core contributions:
- Building OpenS2V-Eval: The most comprehensive S2V evaluation benchmark, with 180 multi-domain prompts + real/synthetic dual categories, and proposing NexusScore, NaturalScore, and GmeScore to precisely quantify model performance in subject consistency, naturalness, and text alignment.
- Releasing OpenS2V-5M: A dataset with 5.4 million 720P high-definition “image-text-video” triplets, generated via cross-video association and multi-view synthesis to ensure diversity and high-quality annotations.
- Providing new insights for S2V model selection: Using the new evaluation framework, the team comprehensively evaluated 18 mainstream models, revealing their strengths and weaknesses in complex scenarios.

- Paper link: https://arxiv.org/abs/2505.20292
- Project site: https://pku-yuangroup.github.io/OpenS2V-Nexus/
- Dataset: https://huggingface.co/datasets/BestWishYsh/OpenS2V-5M
- Evaluation benchmark: https://huggingface.co/datasets/BestWishYsh/OpenS2V-Eval
Three major challenges faced by Subject-to-Video (S2V)
(1) Poor generalization: models perform significantly worse on unseen subject categories, e.g., models trained only on Western faces struggle with Asian faces.
(2) “Copy-paste” issue: models tend to directly copy poses, lighting, and contours from reference images, resulting in unnatural outputs.
(3) Insufficient identity consistency: existing models often fail to maintain consistent identity in generated videos.
Current evaluation benchmarks often give high scores even when videos look unnatural or lack identity consistency, hindering progress in S2V.
The Peking University team used OpenS2V-Eval to reveal these deficiencies and proposed OpenS2V-5M to address them at the data level.
OpenS2V-Eval benchmark
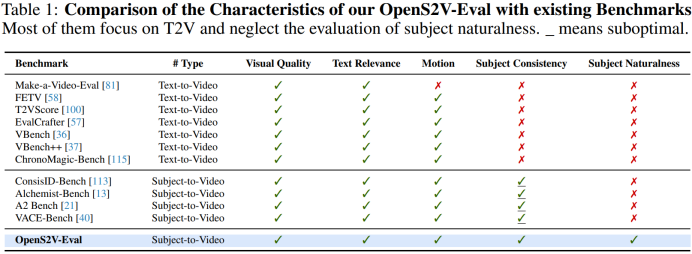
Most existing text-to-video benchmarks focus on text-to-video tasks, like VBench and ChronoMagic-Bench. While ConsisID-Bench supports S2V, it only evaluates facial consistency. Alchemist-Bench, VACE-Benchmark, and A2 Bench evaluate open-domain S2V but mainly use coarse, global metrics that fail to assess naturalness of subjects.
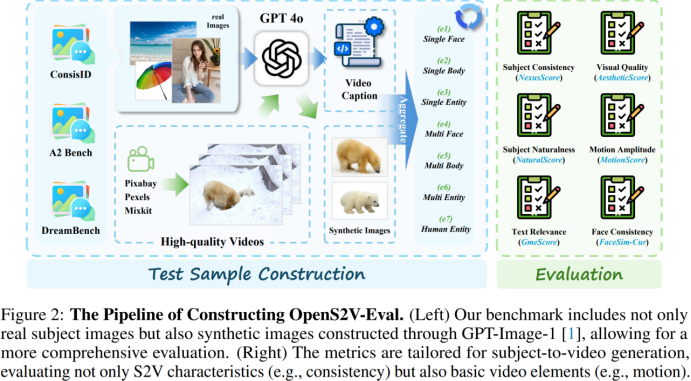
To address this, the team proposed OpenS2V-Eval, the first comprehensive Subject-to-Video benchmark. It defines seven categories (see diagram): ① single face, ② full body, ③ single entity, ④ multiple faces, ⑤ multiple full bodies, ⑥ multiple entities, ⑦ mixed face and entity videos. For each, 30 visual-rich test samples are created to evaluate generalization across subjects.

Additionally, to improve evaluation robustness, the team introduced NexusScore, combining image detection and multimodal retrieval; NaturalScore, based on VLM for naturalness; and GmeScore, for more accurate text relevance assessment.
Million-scale dataset OpenS2V-5M

To support complex downstream tasks, the team created OpenS2V-5M, the first million-scale dataset for Subject-to-Video, also applicable to text-to-video tasks. It includes 5.4 million high-quality, multi-view, multi-modal triplets generated via cross-video association and multi-view synthesis, addressing core challenges like diversity and annotation quality.
Traditional methods crop subjects from video frames, risking the model learning shortcuts rather than true knowledge. To solve this, the team introduced Nexus Data, which includes:
- Rich pairing information via cross-video association;
- Multi-view representations generated by multimodal models to enhance diversity and generalization.
Compared with conventional data, Nexus Data shows higher quality and better addresses the three core challenges of S2V, as illustrated in Figure 5.
Evaluation experiments
The team evaluated nearly all S2V models, including four closed-source and twelve open-source models, covering various support levels for subjects. Results, shown in the figures, indicate closed-source models like Kling outperform others, but open-source models like Phantom and VACE are gradually closing the gap. Common issues include:
- Weak generalization: e.g., low fidelity for certain subjects, such as incorrect backgrounds or low-fidelity characters.
- Copy-paste: models copying expressions, lighting, or poses from reference images, leading to unnatural results.
- Identity fidelity: failure to accurately render consistent identities over time.
Figures 6-11 illustrate these issues, showing fidelity decline with more reference images, initial blurriness, and identity inconsistency over time.