3D VLA New Paradigm! CAS & ByteDance Seed Launch BridgeVLA, Wins CVPR 2025 Workshop Championship}
BridgeVLA, a novel 3D VLA paradigm by CAS and ByteDance Seed, achieves a leap in model capability and data efficiency, winning CVPR 2025 GRAIL workshop's COLOSSEUM Challenge.


Can just three trajectories reach a 96.8% success rate? Easily handle visual interference, task combinations, and generalization scenarios? Perhaps the new paradigm of 3D VLA operation has arrived.
Currently, the 2D VLA model that receives 2D images for Next Action Token prediction has shown potential for general robot operations; meanwhile, the '3D operation strategy' that accepts 3D information as input and uses the next keyframe as output has proven to have high data efficiency (~10 trajectories).
Intuitively, a good '3D VLA' model should combine these advantages, being both efficient and effective. However, current 3D VLA models have yet to meet these expectations.
To address this, CAS's Tieniu Tan's team, in collaboration with ByteDance Seed, introduced BridgeVLA, demonstrating a new 3D VLA paradigm that achieved a significant leap in model capability and data efficiency, winning the CVPR 2025 GRAIL workshop's COLOSSEUM Challenge. The code and data are now fully open source.

- Paper Title: BridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models
- Paper Link: https://arxiv.org/abs/2506.07961
- Project Homepage: https://bridgevla.github.io/
Starting Point: Aligning VLM and VLA
BridgeVLA's core idea is to align pretraining and fine-tuning input-output pairs into a unified 2D space, bridging the gap between VLM and VLA. Instead of using traditional 3D position encoding or 3D information injection, it aligns VLA inputs with VLM, i.e., only images and text instructions.
Additionally, the output is changed from Next token prediction to Heatmap prediction, transforming the output from unstructured tokens to spatially structured 2D heatmaps, fully utilizing 3D spatial priors and further aligning input-output in 2D space.
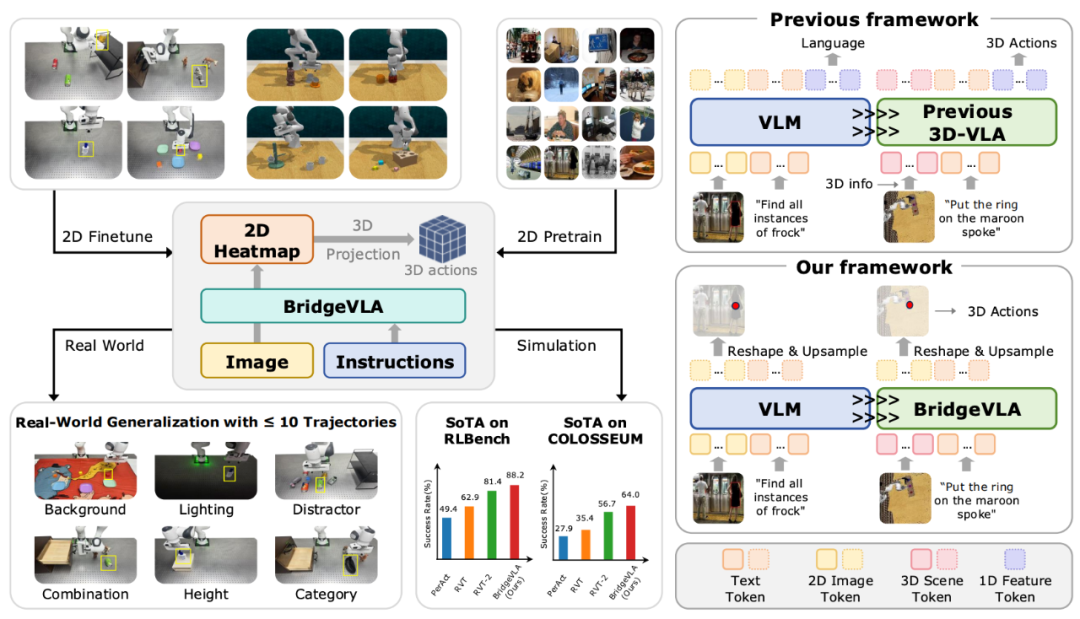
Pretraining: Enabling VLM to Predict 2D Heatmaps
Before fine-tuning with robot data, the model needs pretraining to acquire object detection capabilities. The authors propose a novel scalable pretraining method: input image-object text pairs, extract corresponding image tokens, rearrange these tokens as hidden states, and use a learnable upsampling to restore to the original image size as heatmaps. Cross-entropy loss supervises training, enabling the model to predict heatmaps that locate target objects in pixels.
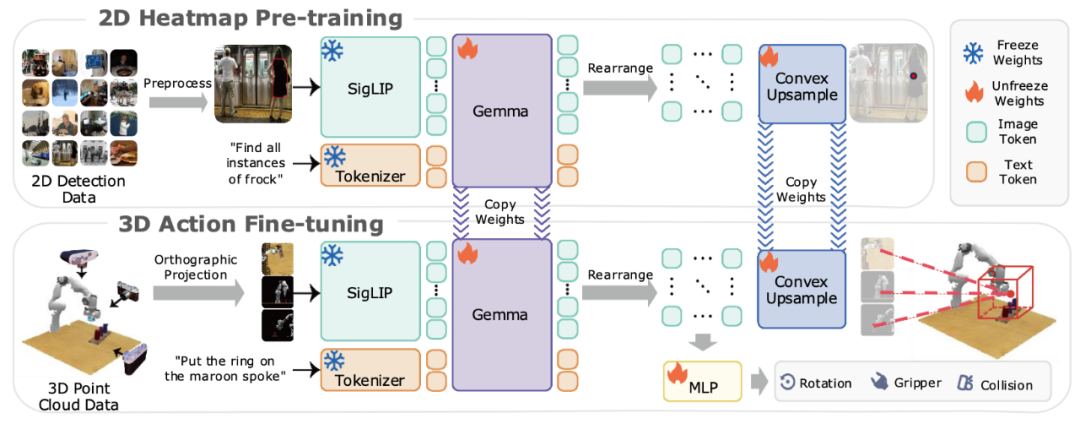
Fine-tuning: Enabling Action Prediction
Similar to typical 3D manipulation strategies like RVT and RVT-2, BridgeVLA predicts keypoints for the next action. It takes scene point clouds and instructions as input, projects point clouds orthogonally from three directions, producing three 2D images. The model outputs heatmaps, which are back-projected to estimate scores for structured grid points in 3D space, selecting the highest-scoring point as the translation target for the robot arm. For rotation, gripper state, and collision detection, global and local features are concatenated and fed into an MLP for prediction.
Additionally, BridgeVLA uses a coarse-to-fine multi-level prediction approach, enlarging and cropping point clouds near initial heatmap targets for a second forward pass, achieving more precise localization.
Simulation Experiments: Leading in 3D Manipulation Benchmarks
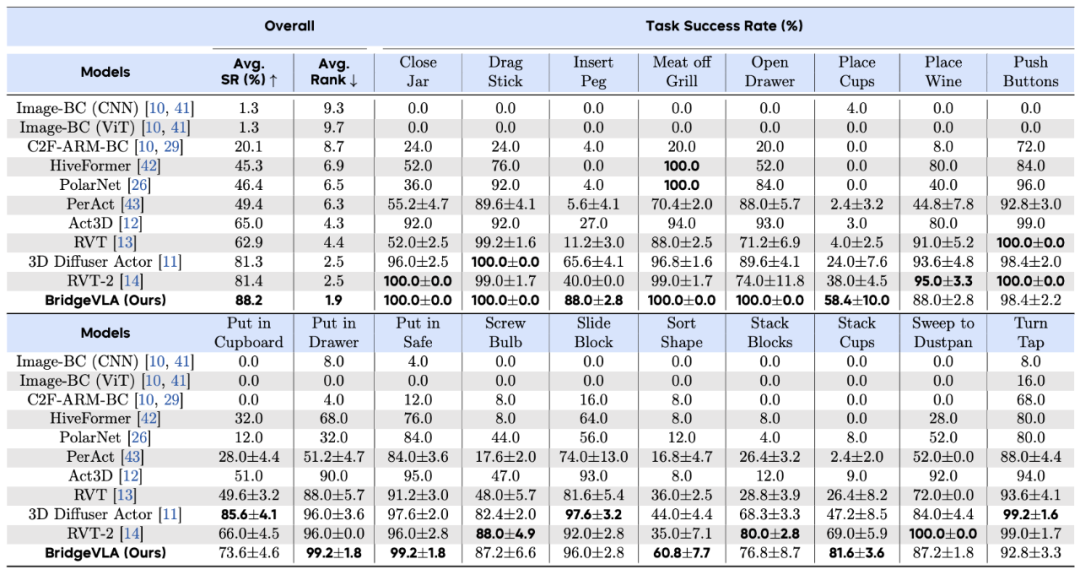
RLBench: Tested on 18 complex RLBench tasks, including non-grasping, grasping, placement, and high-precision insertion tasks. BridgeVLA significantly outperforms existing baselines, increasing success rate from 81.4% to 88.2%, excelling in high-precision tasks.
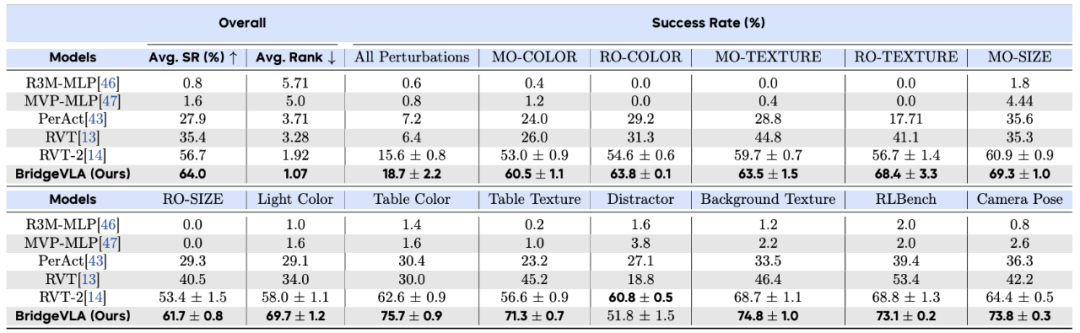
COLOSSEUM: An extension of RLBench, focusing on robustness under 12 types of perturbations (texture, color, size, background, lighting, interference, camera pose). Results show strong robustness, success rate from 56.7% to 64.0%, outperforming in 13 of 14 perturbations.
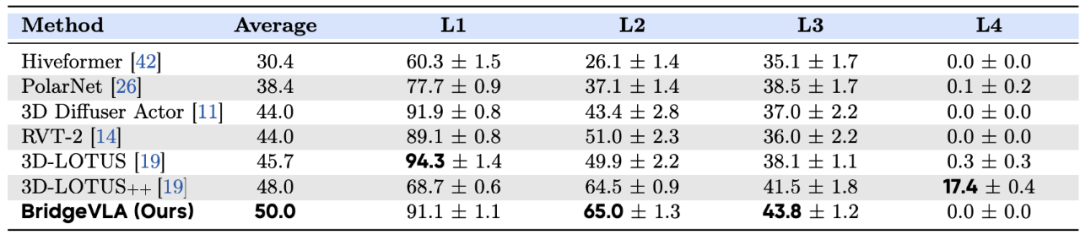
GemBench: Comprising four increasing challenge levels (L1-L4), involving placement, rigid objects, articulated objects, and multi-action long tasks. BridgeVLA achieves top success rates, especially in L2 and L3, demonstrating strong generalization, but performance on L4 remains limited.
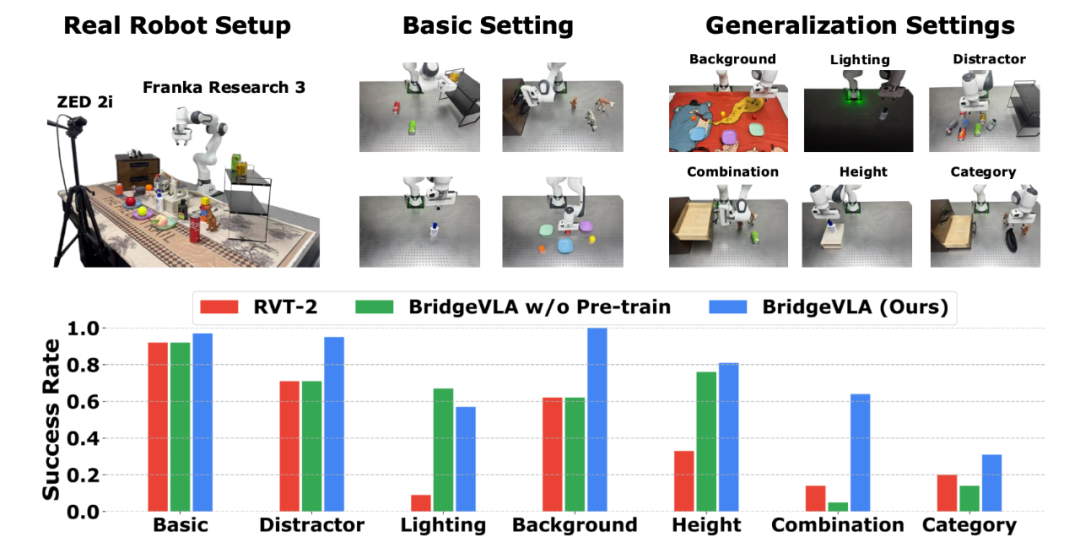
Real Robot Experiments: Surpassing Existing Baselines
In real-world tests, 13 basic tasks and 6 generalization tests (including interference objects, lighting, background, height, combinations, and categories) were designed. Results show BridgeVLA outperforms RVT-2 in six of seven settings.
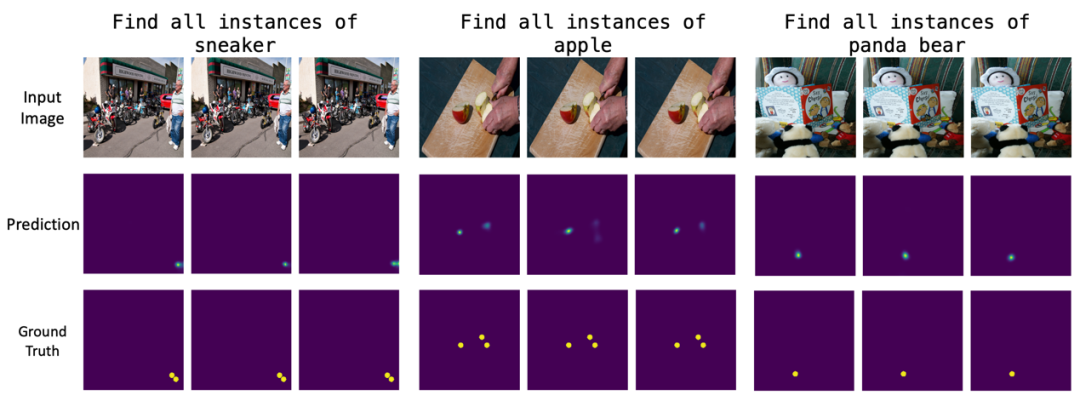
In four visual interference scenarios, BridgeVLA shows high robustness, especially under interference and background changes. Pretraining with 2D heatmaps is crucial for understanding language semantics and generalizing to new object-skill combinations. Even after fine-tuning with robot data, the model retains pretraining knowledge, demonstrating strong transferability.
Summary and Outlook
New VLA Paradigm: Transition from 'Next Token Prediction' to 'Heatmap Prediction' offers a more data-efficient and effective design for 3D VLA.Future Directions: Explore pretraining on more diverse tasks like semantic segmentation and keypoint detection to enhance general visual understanding; develop more expressive action decoding methods; improve performance on long-term tasks with LLM-based task decomposition.